S05-06 JS高级-进程、任务队列、事件循环、错误处理、Storage、正则、手写
[TOC]
浏览器进程、线程
进程和线程
线程和进程是操作系统中的两个概念:
进程(process):计算机已经运行的程序,是操作系统管理程序的一种方式;
线程(thread):操作系统能够运行运算调度的最小单位,通常情况下它被包含在进程中;
听起来很抽象,这里还是给出我的解释:
进程:我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程);
线程:每一个进程中,都会启动至少一个线程用来执行程序中的代码,这个线程被称之为主线程;
所以我们也可以说进程是线程的容器;
再用一个形象的例子解释:
操作系统类似于一个大工厂;
工厂中里有很多车间,这个车间就是进程;
每个车间可能有一个以上的工人在工厂,这个工人就是线程;
操作系统-进程-线程
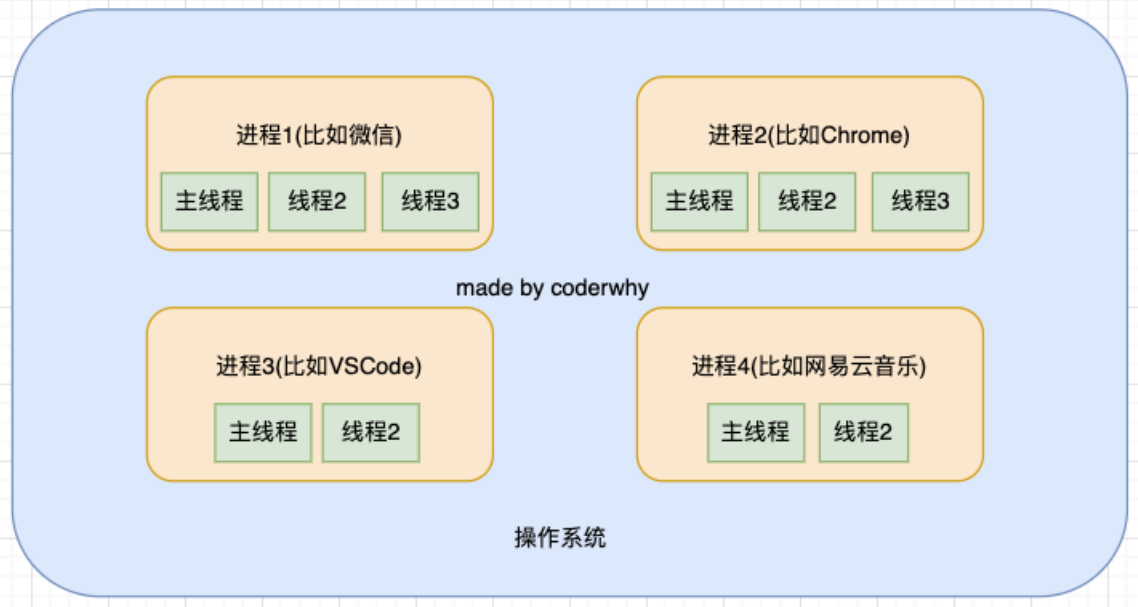
操作系统的工作方式
操作系统是如何做到同时让多个进程(边听歌、边写代码、边查阅资料)同时工作呢?
这是因为CPU的运算速度非常快,它可以快速的在多个进程之间迅速的切换;
当我们进程中的线程获取到时间片时,就可以快速执行我们编写的代码;
对于用户来说是感受不到这种快速的切换的;
你可以在Mac的活动监视器或者Windows的资源管理器中查看到很多进程:
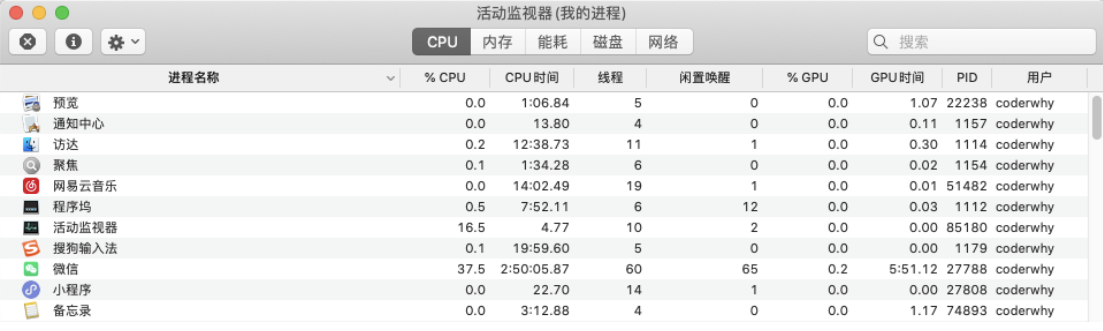
浏览器中的JavaScript线程
我们经常会说*JavaScript是单线程(可以开启workers)的,但是JavaScript的线程应该有自己的容器进程**:浏览器或者**Node。
浏览器是一个进程吗,它里面只有一个线程吗?
目前多数的浏览器其实都是多进程的,当我们打开一个tab页面时就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出;
每个进程中又有很多的线程,其中包括执行JavaScript代码的线程;
JavaScript的代码执行是在一个单独的线程中执行的:**
这就意味着JavaScript的代码,在同一个时刻只能做一件事;
如果这件事是非常耗时的,就意味着当前的线程就会被阻塞;
所以真正耗时的操作,实际上并不是由JavaScript线程在执行的:
浏览器的每个进程是多线程的,那么其他线程可以来完成这个耗时的操作;
比如网络请求、定时器,我们只需要在特性的时候执行应该有的回调即可;
浏览器的事件循环
如果在执行JavaScript代码的过程中,有异步操作呢?
中间我们插入了一个setTimeout的函数调用;
这个函数被放到入调用栈中,执行会立即结束,并不会阻塞后续代码的执行;
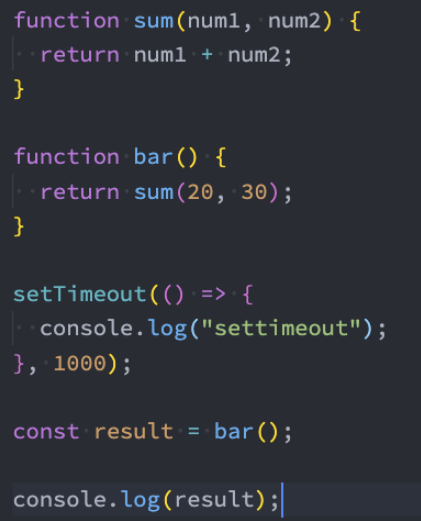

宏任务、微任务队列
宏任务和微任务
但是事件循环中并非只维护着一个队列,事实上是有两个队列:
宏任务队列(macrotask queue):ajax、setTimeout、setInterval、DOM监听、UI Rendering等
微任务队列(microtask queue):Promise的then回调、 Mutation Observer API、*queueMicrotask()*等
那么事件循环对于两个队列的优先级是怎么样的呢?
1.main script中的代码优先执行(编写的顶层script代码);
2.在执行任何一个宏任务之前(不是队列,是一个宏任务),都会先查看微任务队列中是否有任务需要执行
- 也就是宏任务执行之前,必须保证微任务队列是空的;
- 如果不为空,那么就优先执行微任务队列中的任务(回调);
下面我们通过几到面试题来练习一下。
Promise面试题
Promise面试题
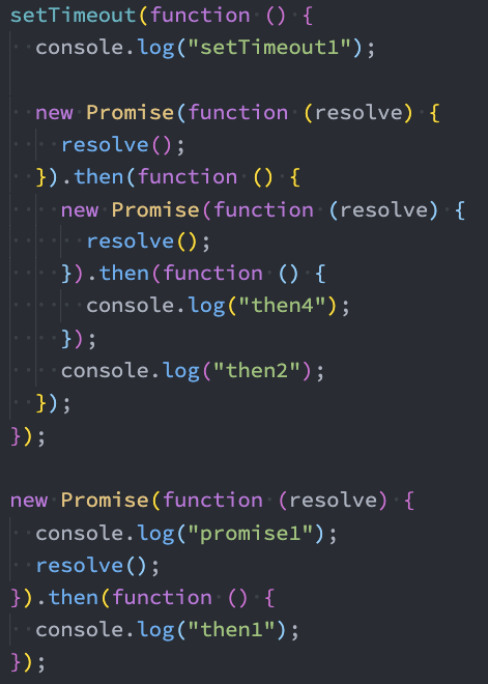
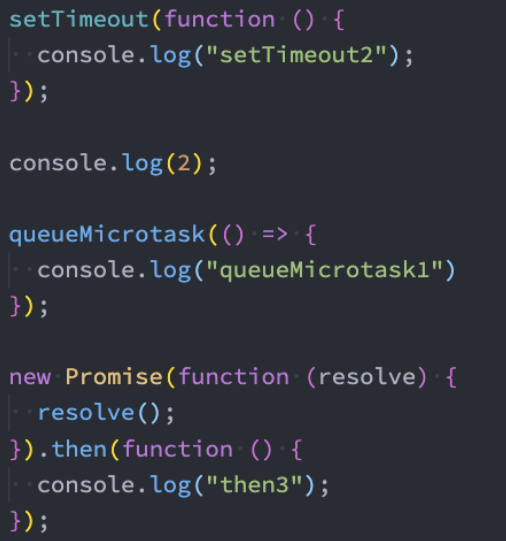
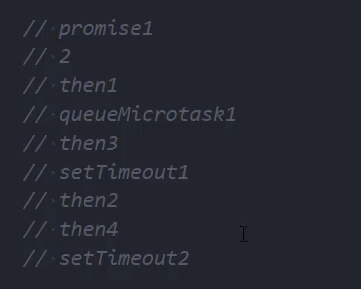
promise async await 面试题



事件循环
Node的事件循环
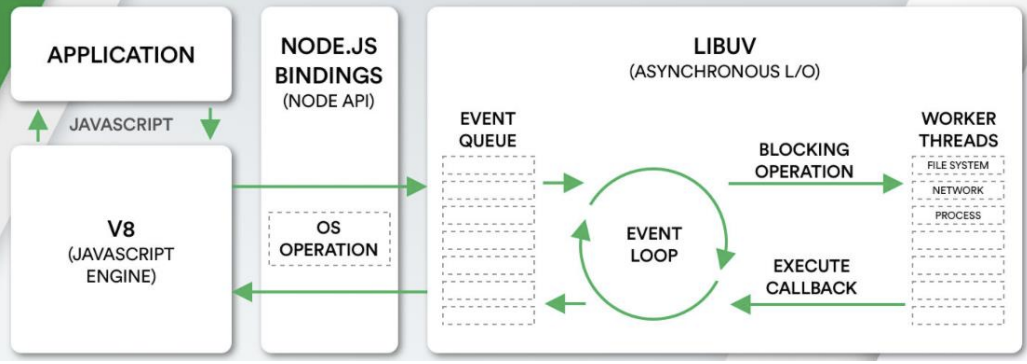
浏览器中的EventLoop是根据HTML5定义的规范来实现的,不同的浏览器可能会有不同的实现,而Node中是由libuv实现的。
这里我们来给出一个Node的架构图:
我们会发现libuv中主要维护了一个EventLoop和worker threads(线程池);
EventLoop负责调用系统的一些其他操作:文件的IO、Network、child-processes等
libuv是一个多平台的专注于异步IO的库,它最初是为Node开发的,但是现在也被使用到Luvit、Julia、pyuv等其他地方;
Node事件循环的阶段
我们最前面就强调过,事件循环像是一个桥梁,是连接着应用程序的JavaScript和系统调用之间的通道:
无论是我们的文件IO、数据库、网络IO、定时器、子进程,在完成对应的操作后,都会将对应的结果和回调函数放到事件循环(任务队列)中;
事件循环会不断的从任务队列中取出对应的事件(回调函数)来执行;
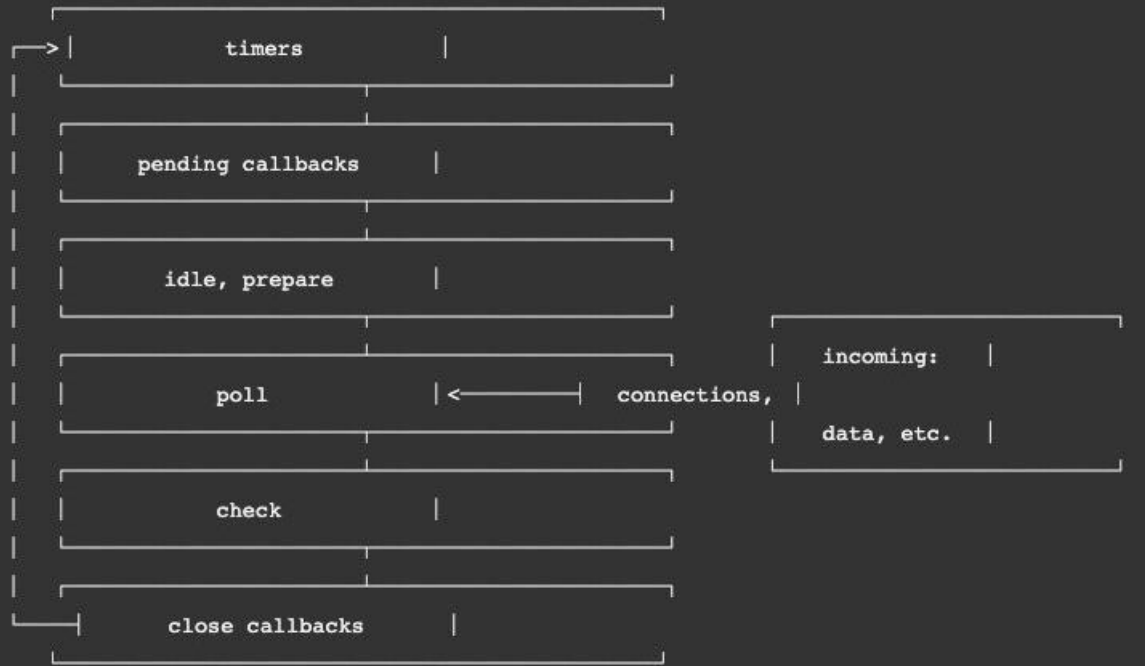
但是一次完整的事件循环Tick分成很多个阶段:
定时器(Timers):本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数。
待定回调(Pending Callback):对某些系统操作(如TCP错误类型)执行回调,比如TCP连接时接收到ECONNREFUSED。
idle, prepare:仅系统内部使用。
轮询(Poll):检索新的 I/O 事件;执行与 I/O 相关的回调;
检测(check):setImmediate() 回调函数在这里执行。
关闭的回调函数:一些关闭的回调函数,如:socket.on('close', ...)。
Node事件循环的阶段图解
Node的宏任务和微任务
我们会发现从一次事件循环的Tick来说,Node的事件循环更复杂,它也分为微任务和宏任务:
宏任务(macrotask):setTimeout、setInterval、IO事件、setImmediate、close事件;
微任务(microtask):Promise的then回调、process.nextTick、queueMicrotask;
但是,Node中的事件循环不只是 微任务队列和 宏任务队列:
微任务队列:
- next tick queue:process.nextTick;
- other queue:Promise的then回调、queueMicrotask;
宏任务队列:
- timer queue:setTimeout、setInterval;
- poll queue:IO事件;
- check queue:setImmediate;
- close queue:close事件;
Node事件循环的顺序
所以,在每一次事件循环的tick中,会按照如下顺序来执行代码:
next tick microtask queue;
other microtask queue;
timer queue;
poll queue;
check queue;
close queue;
Node执行面试题
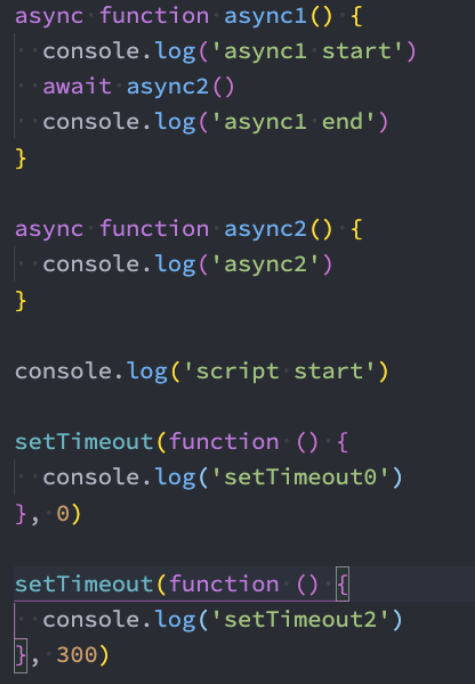
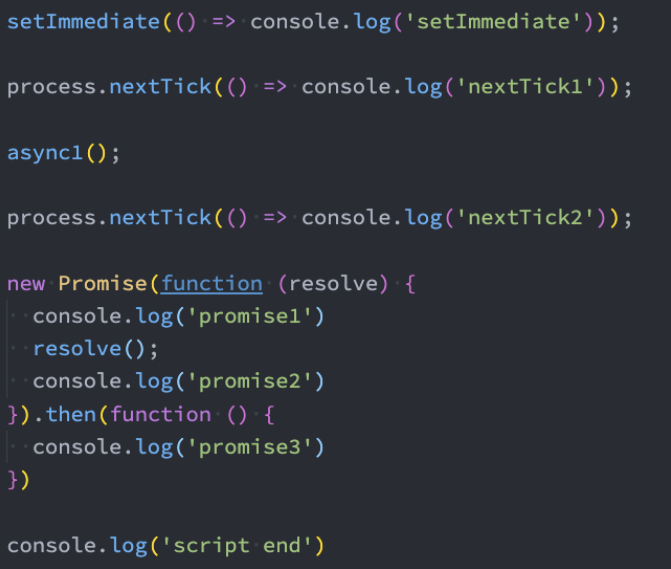
throw、try catch
错误处理方案
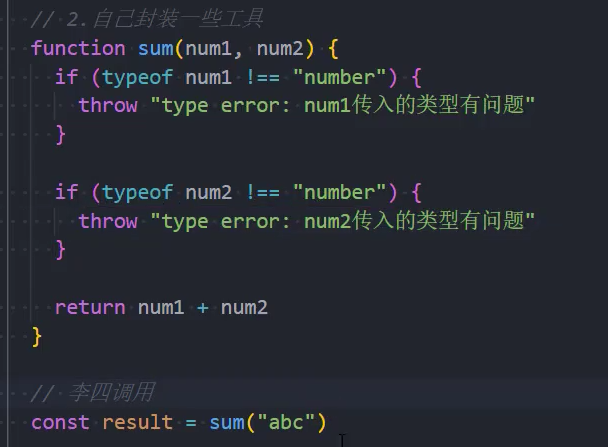
开发中我们会封装一些工具函数,封装之后给别人使用:
在其他人使用的过程中,可能会传递一些参数;
对于函数来说,需要对这些参数进行验证,否则可能得到的是我们不想要的结果;
很多时候我们可能验证到不是希望得到的参数时,就会直接return:
但是return存在很大的弊端:调用者不知道是因为函数内部没有正常执行,还是执行结果就是一个undefined;
事实上,正确的做法应该是如果没有通过某些验证,那么应该让外界知道函数内部报错了;
如何可以让一个函数告知外界自己内部出现了错误呢?
- 通过throw关键字,抛出一个异常;
throw语句:
throw语句用于抛出一个用户自定义的异常;
当遇到throw语句时,当前的函数执行会被停止(throw后面的语句不会执行);
如果我们执行代码,就会报错,拿到错误信息的时候我们可以及时的去修正代码。

throw关键字
throw表达式就是在throw后面可以跟上一个表达式来表示具体的异常信息:

throw关键字可以跟上哪些类型呢?
基本数据类型:比如number、string、Boolean
对象类型:对象类型可以包含更多的信息
但是每次写这么长的对象又有点麻烦,所以我们可以创建一个类:
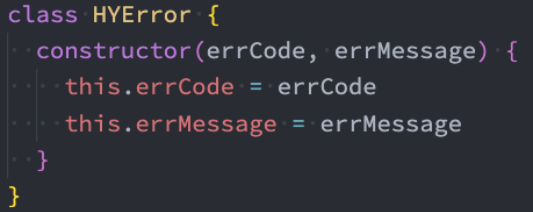
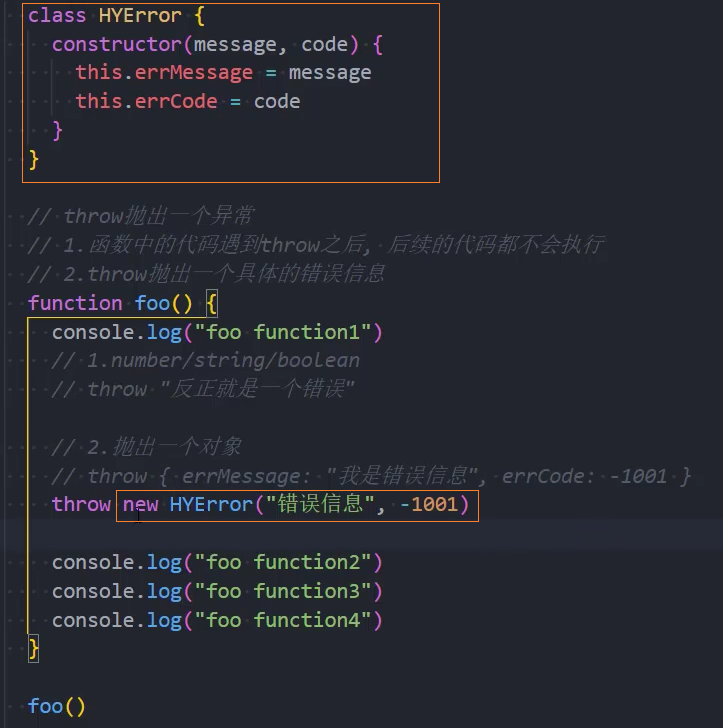
Error类型
事实上,JavaScript已经给我们提供了一个Error类,我们可以直接创建这个类的对象:

Error包含三个属性:
messsage:创建Error对象时传入的message;
name:Error的名称,通常和类的名称一致;
stack:整个Error的错误信息,包括函数的调用栈,当我们直接打印Error对象时,打印的就是stack;
Error有一些自己的子类:**
RangeError:下标值越界时使用的错误类型;
SyntaxError:解析语法错误时使用的错误类型;
TypeError:出现类型错误时,使用的错误类型;
异常的处理
我们会发现在之前的代码中,一个函数抛出了异常,调用它的时候程序会被强制终止:
这是因为如果我们在调用一个函数时,这个函数抛出了异常,但是我们并没有对这个异常进行处理,那么这个异常会继续传递到上一个函数调用中;
而如果到了最顶层(全局)的代码中依然没有对这个异常的处理代码,这个时候就会报错并且终止程序的运行;
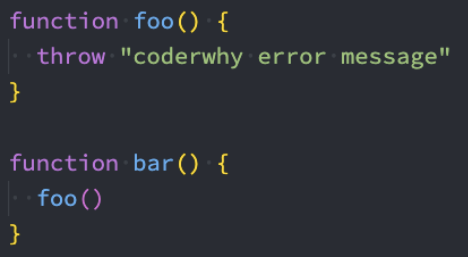
我们先来看一下这段代码的异常传递过程:
foo函数在被执行时会抛出异常,也就是我们的bar函数会拿到这个异常;
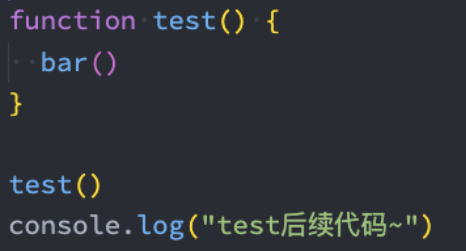
但是bar函数并没有对这个异常进行处理,那么这个异常就会被继续传递到调用bar函数的函数,也就是test函数;
但是test函数依然没有处理,就会继续传递到我们的全局代码逻辑中;
依然没有被处理,这个时候程序会终止执行,后续代码都不会再执行了;
异常的捕获
但是很多情况下当出现异常时,我们并不希望程序直接退出,而是希望可以正确的处理异常:
- 这个时候我们就可以使用try catch


在ES10(ES2019)中,catch后面绑定的error可以省略。
当然,如果有一些必须要执行的代码,我们可以使用finally来执行:
- finally表示最终一定会被执行的代码结构;
注意:如果try和finally中都有返回值,那么会使用finally当中的返回值;
Storage
正则表达式
防抖、节流
简介
防抖和节流的概念其实最早并不是出现在软件工程中,防抖是出现在电子元件中,节流出现在流体流动中
而JavaScript是事件驱动的,大量的操作会触发事件,加入到事件队列中处理。
而对于某些频繁的事件处理会造成性能的损耗,我们就可以通过防抖和节流来限制事件频繁的发生;
防抖和节流函数目前已经是前端实际开发中两个非常重要的函数,也是面试经常被问到的面试题。
但是很多前端开发者面对这两个功能,有点摸不着头脑:
某些开发者根本无法区分防抖和节流有什么区别(面试经常会被问到);
某些开发者可以区分,但是不知道如何应用;
某些开发者会通过一些第三方库来使用,但是不知道内部原理,更不会编写;
接下来我们会一起来学习防抖和节流函数:
我们不仅仅要区分清楚防抖和节流两者的区别,也要明白在实际工作中哪些场景会用到;
并且我会带着大家一点点来编写一个自己的防抖和节流的函数,不仅理解原理,也学会自己来编写;
防抖函数
防抖函数(debounce)
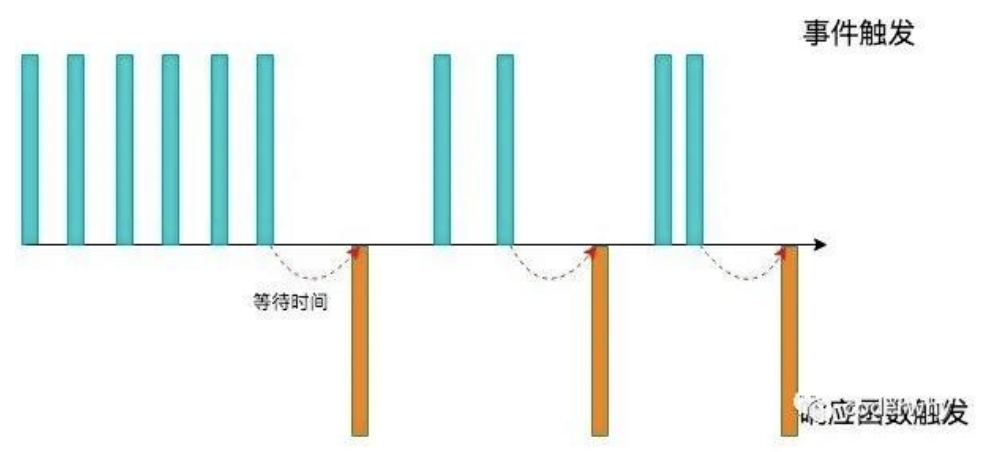
我们用一副图来理解一下它的过程:
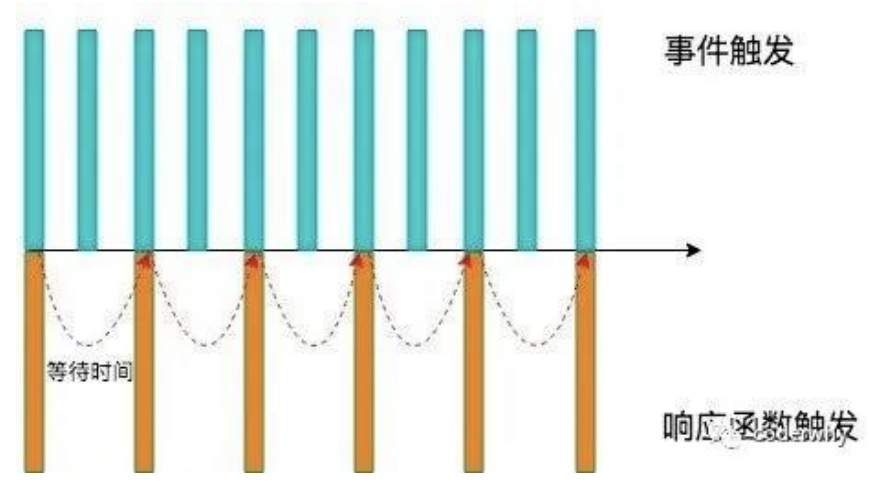
当事件触发时,相应的函数并不会立即触发,而是会等待一定的时间;
当事件密集触发时,函数的触发会被频繁的推迟;
只有等待了一段时间也没有事件触发,才会真正的执行响应函数;
应用场景:
防抖的应用场景很多:
搜索联想:
oninput,输入框中频繁的输入内容,搜索或者提交信息;频繁点击事件:
onclick,频繁的点击按钮,触发某个事件;浏览器滚动事件:
onscroll,监听浏览器滚动事件,完成某些特定操作;浏览器缩放事件:
onresize,用户缩放浏览器的resize事件;
示例: 搜索联想
我们都遇到过这样的场景,在某个搜索框中输入自己想要搜索的内容:
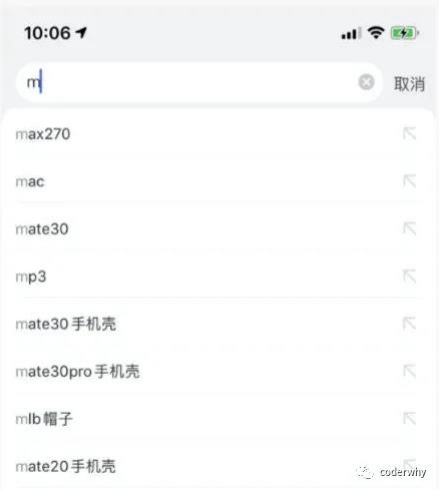
比如想要搜索一个MacBook:
当我输入m时,为了更好的用户体验,通常会出现对应的联想内容,这些联想内容通常是保存在服务器的,所以需要一次网络请求;
当继续输入ma时,再次发送网络请求;
那么macbook一共需要发送7次网络请求;
这大大损耗我们整个系统的性能,无论是前端的事件处理,还是对于服务器的压力;
但是我们需要这么多次的网络请求吗?
不需要,正确的做法应该是在合适的情况下再发送网络请求;
比如如果用户快速的输入一个macbook,那么只是发送一次网络请求;
比如如果用户是输入一个m想了一会儿,这个时候m确实应该发送一次网络请求;
也就是我们应该监听用户在某个时间,比如500ms内,没有再次触发时间时,再发送网络请求;
这就是防抖的操作:只有在某个时间内,没有再次触发某个函数时,才真正的调用这个函数;
节流函数
节流函数(throttle)
我们用一副图来理解一下节流的过程
当事件触发时,会执行这个事件的响应函数;
如果这个事件会被频繁触发,那么节流函数会按照一定的频率来执行函数;
不管在这个中间有多少次触发这个事件,执行函数的频率总是固定的;
应用场景:
页面滚动事件:监听页面的滚动事件;
鼠标移动事件;
频繁点击事件:用户频繁点击按钮操作;
游戏某些设计:游戏中的一些设计,如发射子弹;
很多人都玩过类似于飞机大战的游戏
在飞机大战的游戏中,我们按下空格会发射一个子弹:
很多飞机大战的游戏中会有这样的设定,即使按下的频率非常快,子弹也会保持一定的频率来发射;
比如1秒钟只能发射一次,即使用户在这1秒钟按下了10次,子弹会保持发射一颗的频率来发射;
但是事件是触发了10次的,响应的函数只触发了一次;

生活中的例子
生活中防抖的例子:
比如说有一天我上完课,我说大家有什么问题来问我,我会等待五分钟的时间。
如果在五分钟的时间内,没有同学问我问题,那么我就下课了;
在此期间,a同学过来问问题,并且帮他解答,解答完后,我会再次等待五分钟的时间看有没有其他同学问问题;
如果我等待超过了5分钟,就点击了下课(才真正执行这个时间);
生活中节流的例子:
比如说有一天我上完课,我说大家有什么问题来问我,但是在一个5分钟之内,不管有多少同学来问问题,我只会解答一个问题;
如果在解答完一个问题后,5分钟之后还没有同学问问题,那么就下课;
案例准备
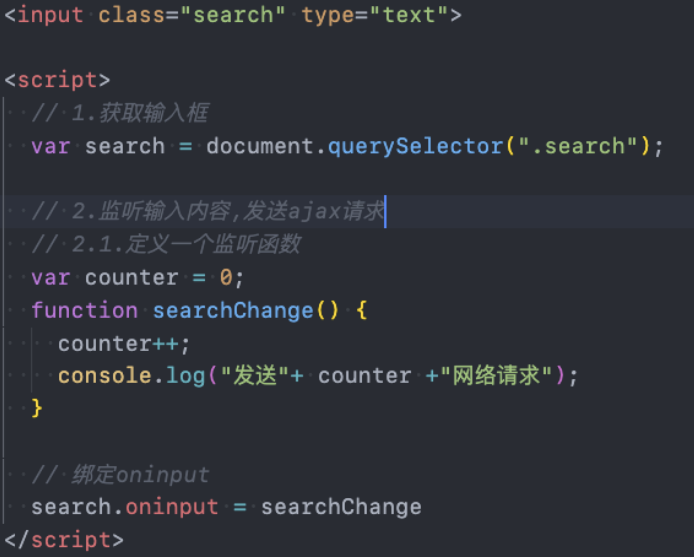
我们通过一个搜索框来延迟防抖函数的实现过程:
- 监听input的输入,通过打印模拟网络请求
测试发现快速输入一个macbook共发送了7次请求,显示我们需要对它进行防抖操作:

underscore
Underscore库的介绍
事实上我们可以通过一些第三方库来实现防抖操作:
lodash
underscore
这里使用underscore
我们可以理解成lodash是underscore的升级版,它更重量级,功能也更多;
但是目前我看到underscore还在维护,lodash已经很久没有更新了;
Underscore的官网: https://underscorejs.org/
安装:
Underscore的安装有很多种方式:
下载Underscore,本地引入;
通过CDN直接引入;
通过包管理工具(npm)管理安装;
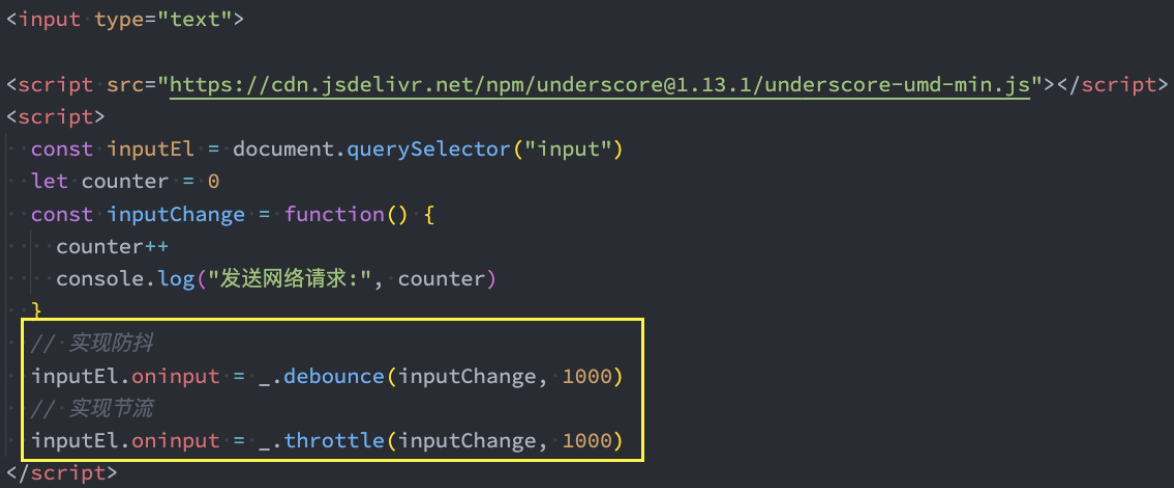
这里我们直接通过CDN:
<script src="https://cdn.jsdelivr.net/npm/underscore@1.13.1/underscore-umd-min.js"></script>Underscore实现防抖和节流
手写题
手写-防抖函数
我们按照如下思路来实现:
- 防抖基本功能实现:可以实现防抖效果
- 优化一:优化参数和this指向
- 优化二:优化取消操作(增加取消功能)
- 优化三:优化立即执行效果(第一次立即执行)
- 优化四:优化返回值
1、基本实现
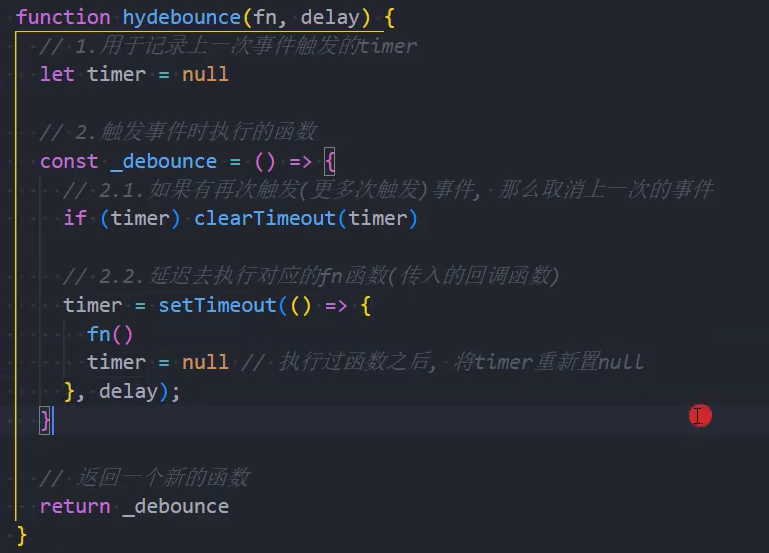
2、优化:参数和this绑定
this指向
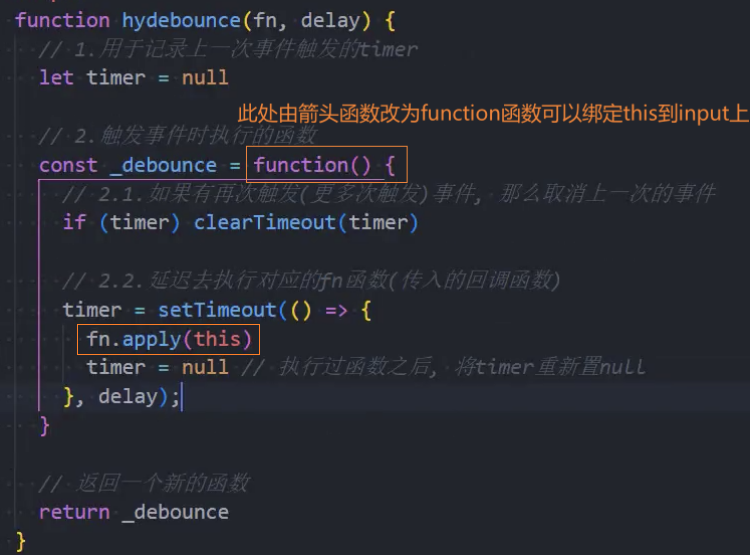
参数
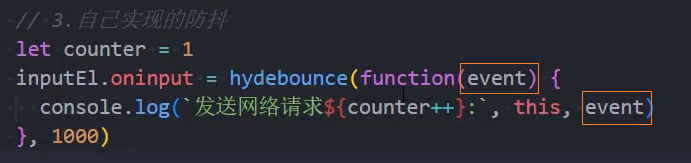
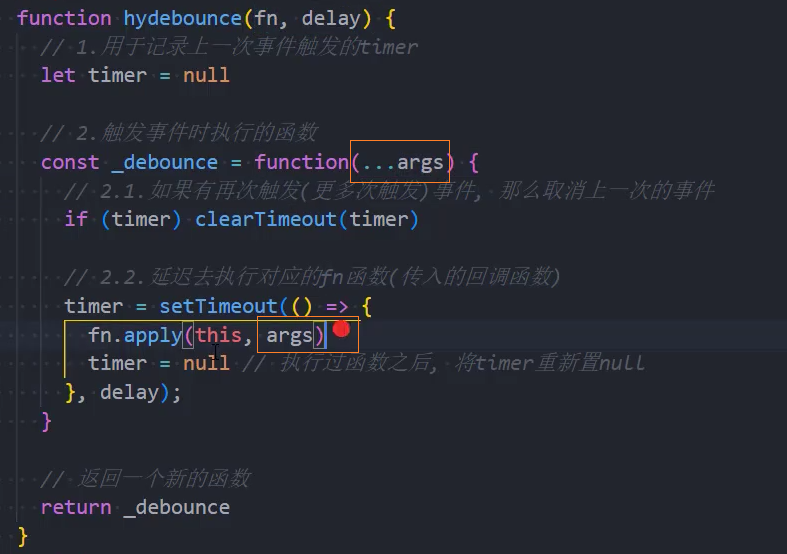
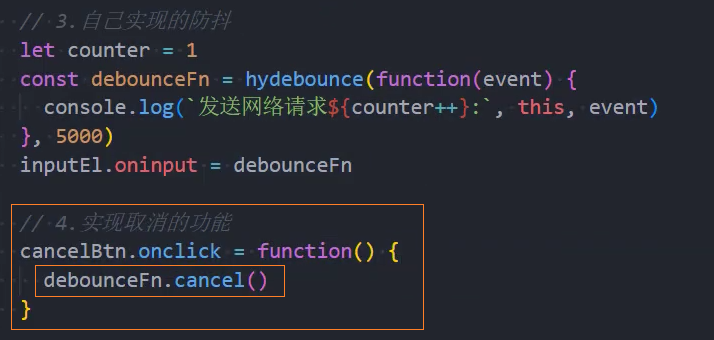
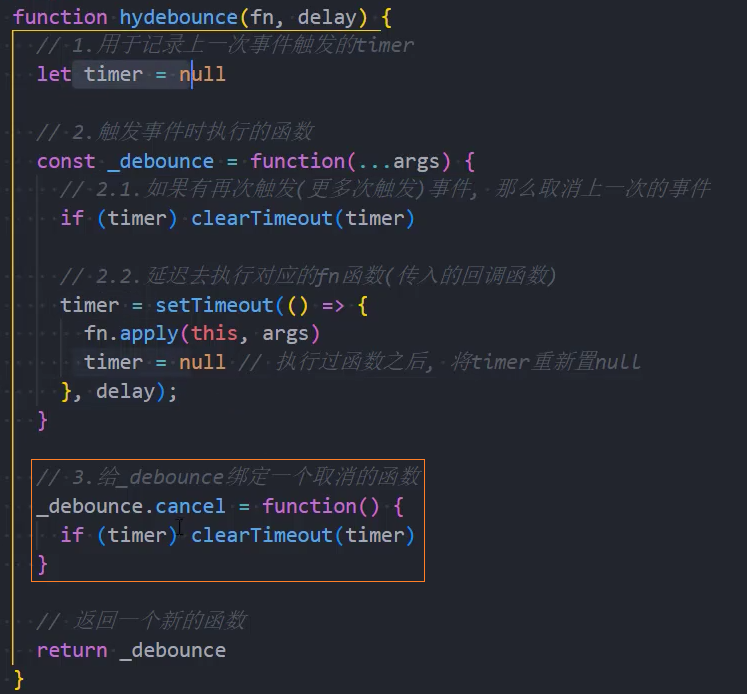
3、优化:取消功能
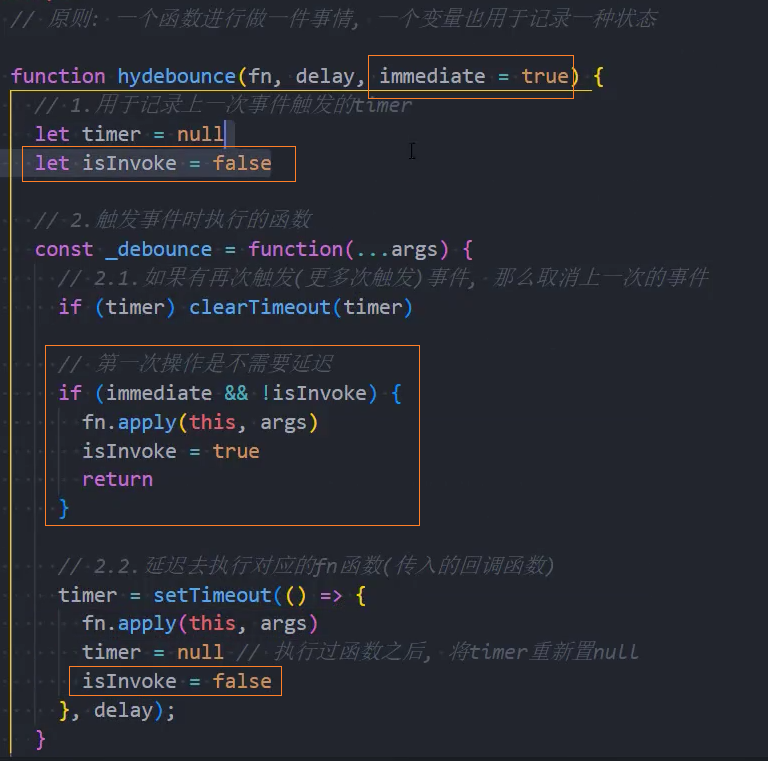
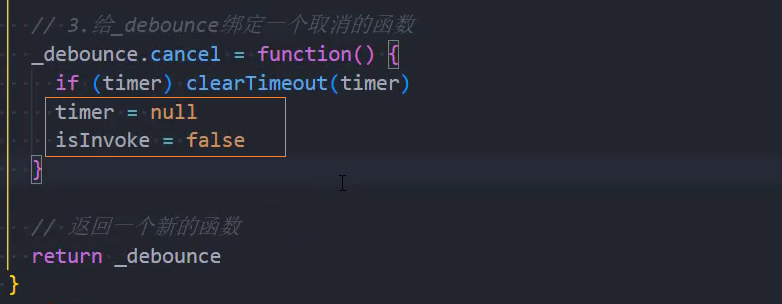
4、优化:第一次立即执行
immediate:控制否时启用立即执行功能isInvoke:控制函数是否已经立即执行一次了
5、优化:返回值
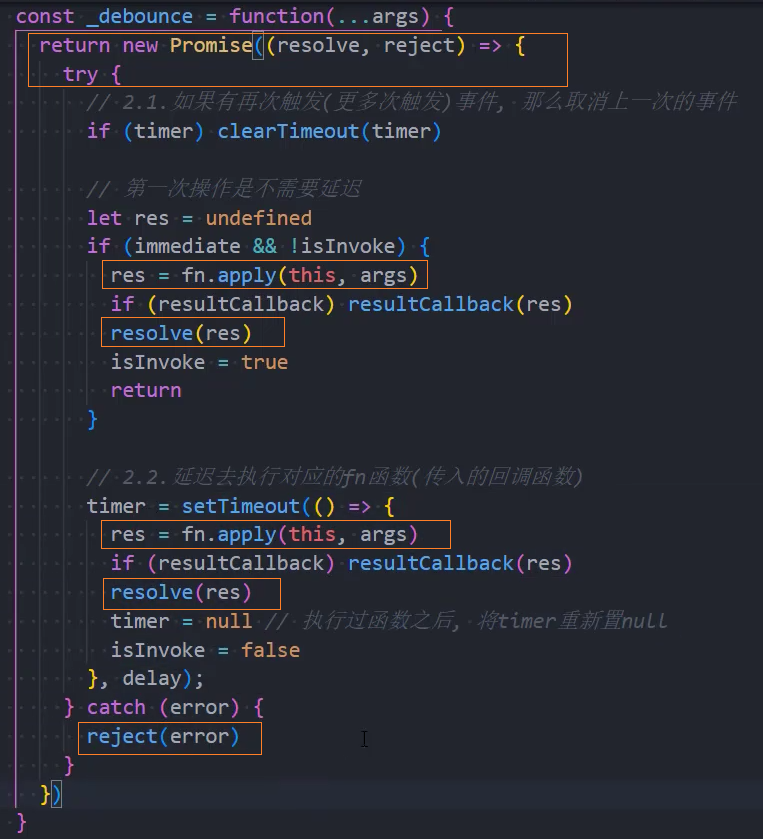
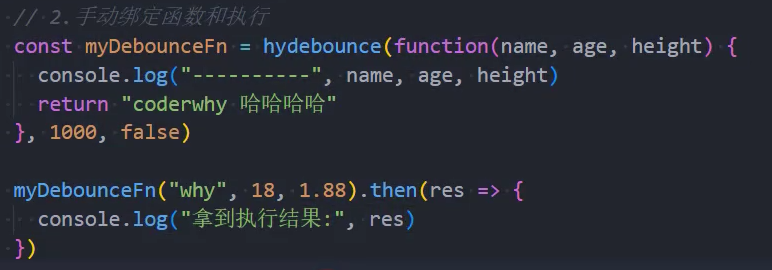
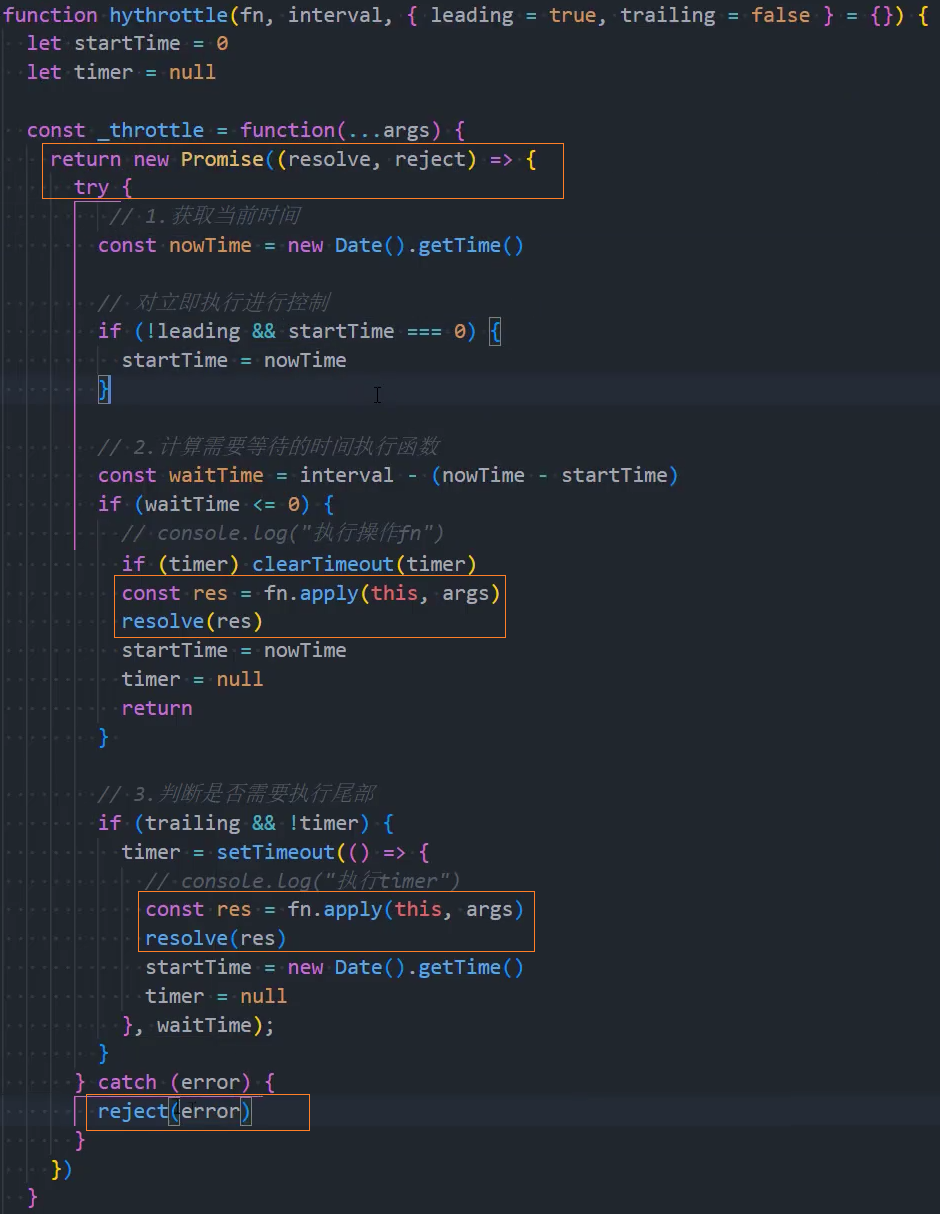
手写-节流函数
我们按照如下思路来实现:
- 节流函数的基本实现:可以实现节流效果
- 优化一:绑定this和参数
- 优化二:控制立即执行,节流最后一次也可以执行
- 优化三:优化添加取消功能
- 优化四:优化返回值问题
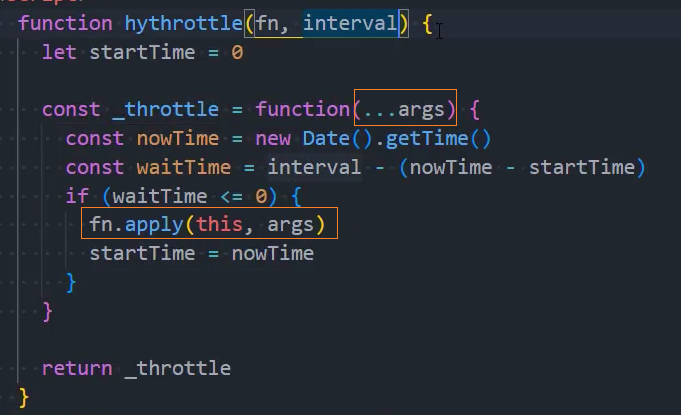
1、基本实现
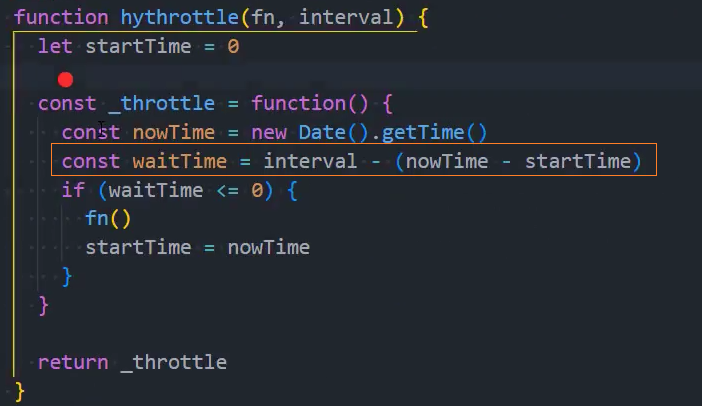
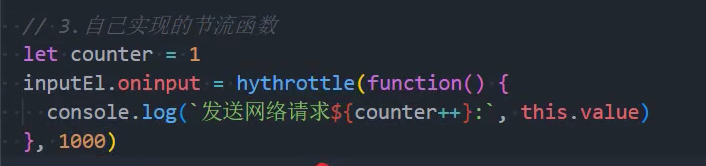
2、优化:绑定this和参数
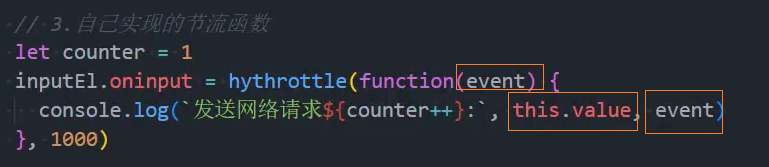
3、优化:控制立即执行
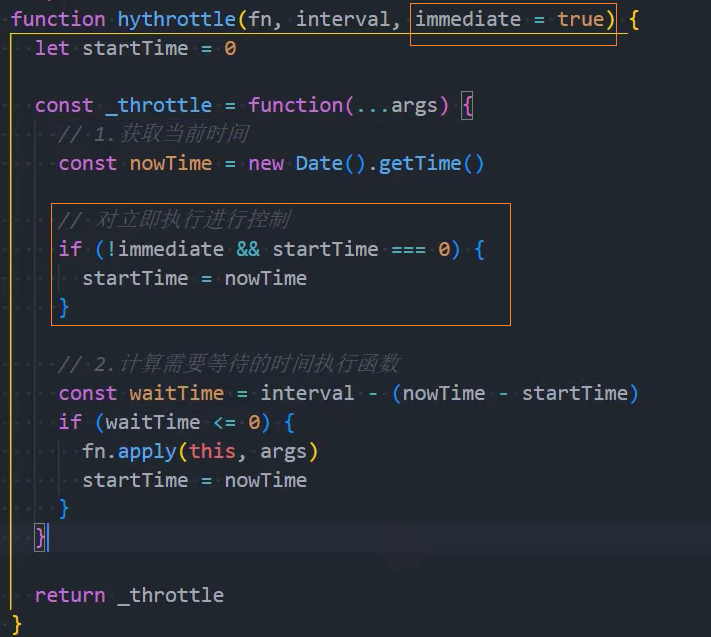
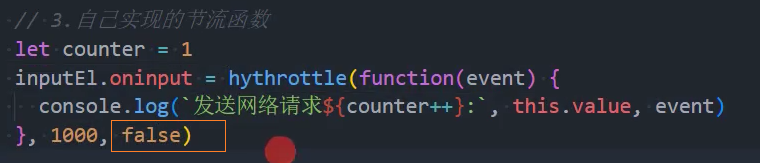
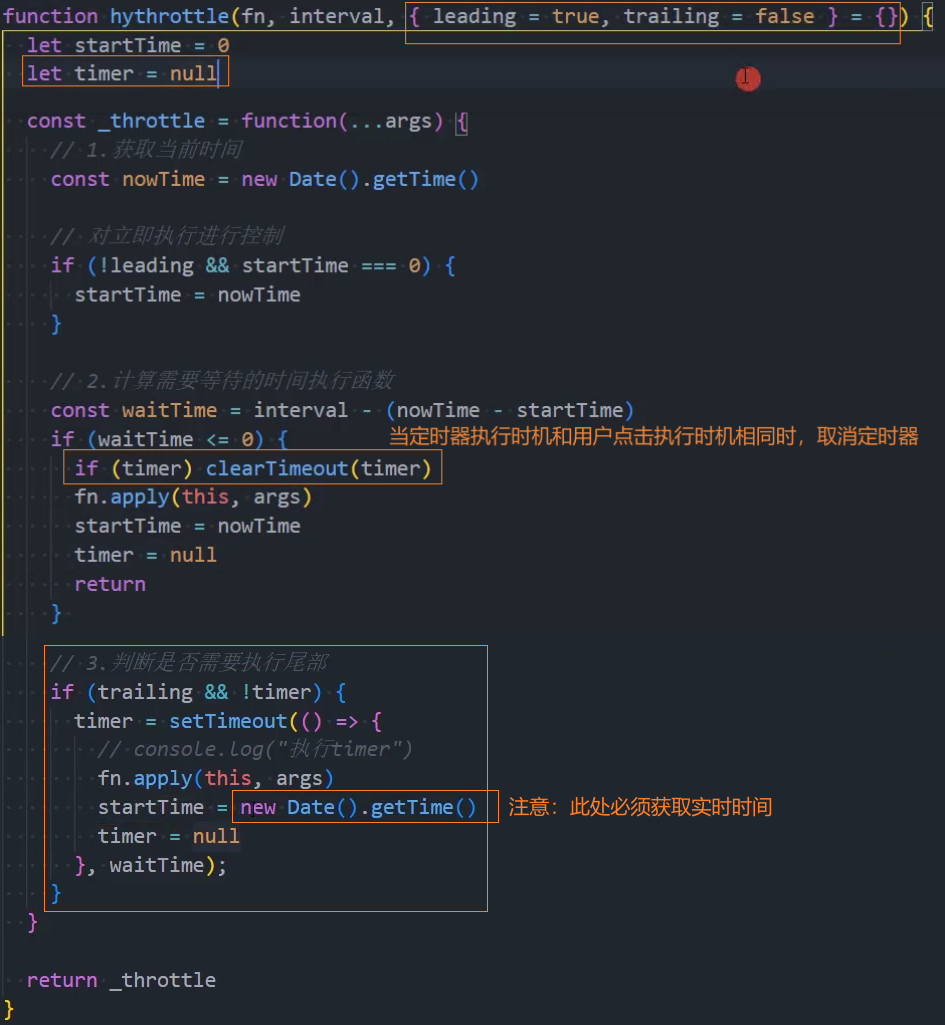
4、优化:控制执行最后一次
思路一: 给每次点击时添加一个定时器,延迟时间设为waitTime,当再次点击时取消上次的定时器,重新添加一个。
思路二: 在每个执行fn函数的节点,添加一个延迟时间为waitTime的定时器,当用户在fn函数执行节点的时间上也点击了一次就取消该定时器(使用中)
4、优化:取消功能
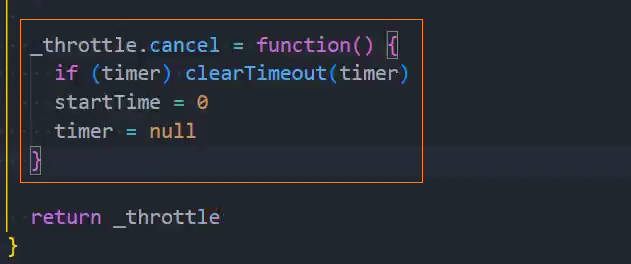
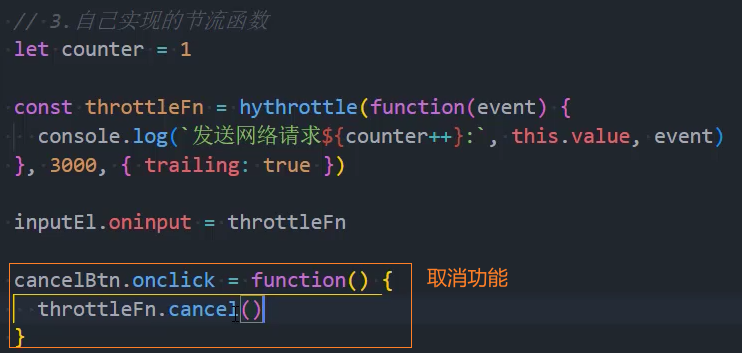
5、优化:返回值
手写-深拷贝函数
前面我们已经学习了对象相互赋值的一些关系,分别包括:
引用赋值:指向同一个对象,相互之间会影响;
对象的浅拷贝:只是浅层的拷贝,内部引入对象时,依然会相互影响;
对象的深拷贝:两个对象不再有任何关系,不会相互影响;
深拷贝实现方式:
- JSON.parse
- 第三方库:underscore、lodash
- 自己实现
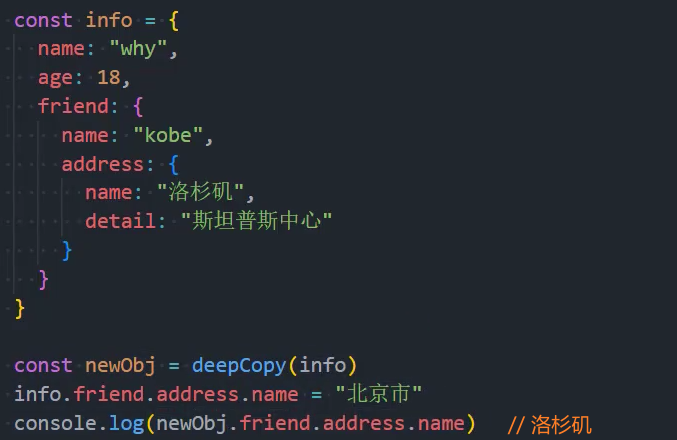
前面我们已经可以通过一种方法来实现深拷贝了:JSON.parse
这种深拷贝的方式其实对于函数、Symbol等是无法处理的;
并且如果存在对象的循环引用,也会报错的;
const obj = JSON.parse(JSON.stringify(info))自定义深拷贝函数:
1.自定义深拷贝的基本功能;
2.对Symbol的key进行处理;
3.其他数据类型的值进程处理:数组、函数、Symbol、Set、Map;
4.对循环引用的处理;
工具函数:判断对象
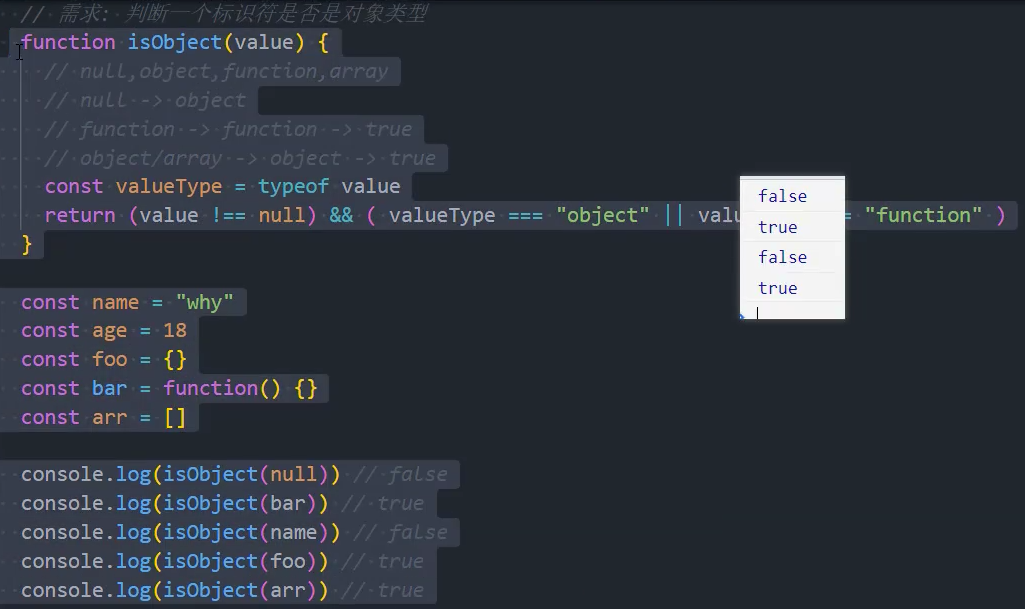
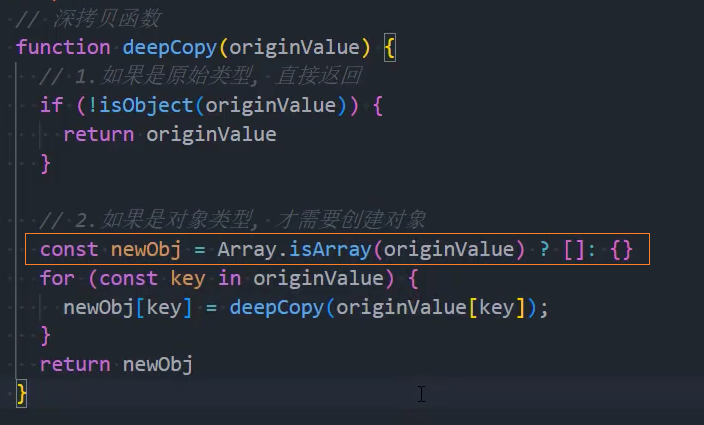
1、基本实现
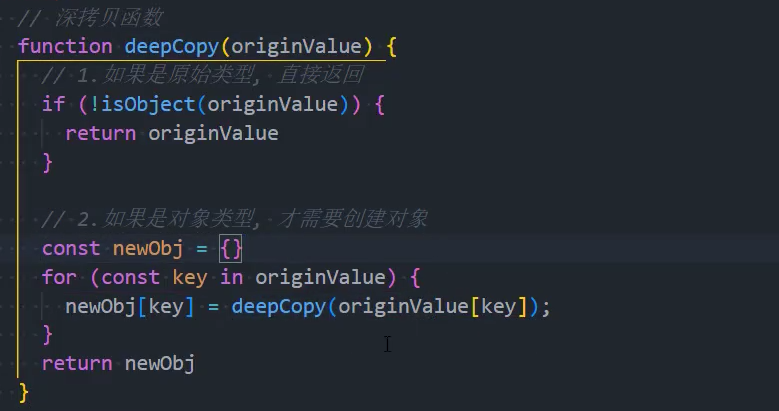
2、优化:区分数组和对象

3、优化:其他类型-处理set
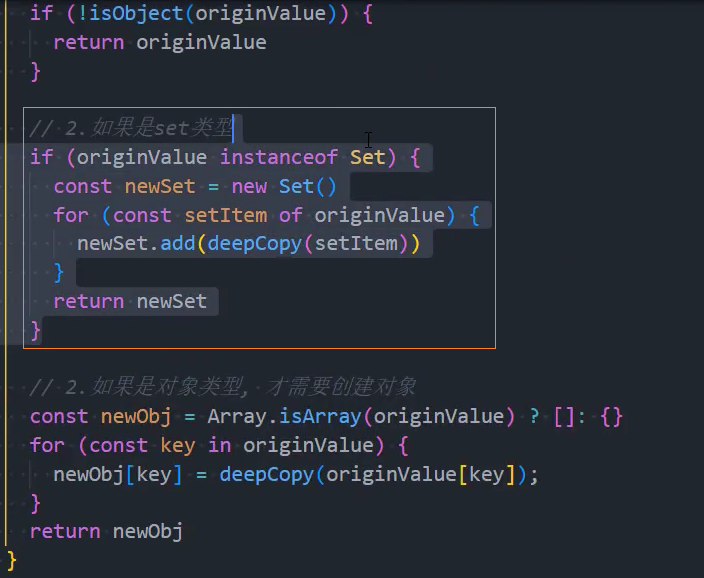
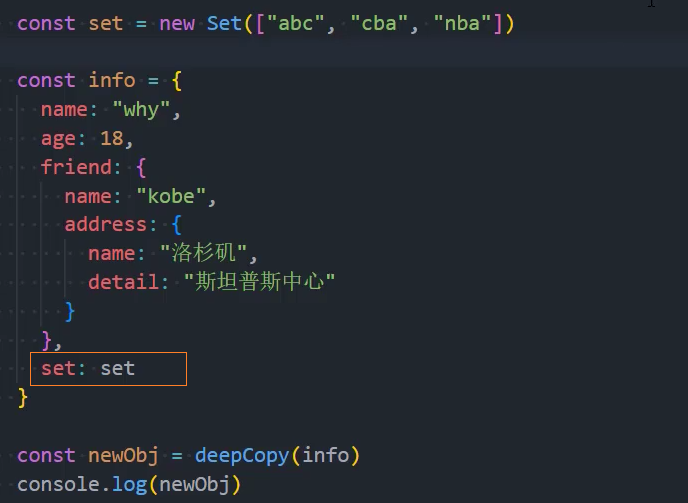
4、优化:其他类型-处理map
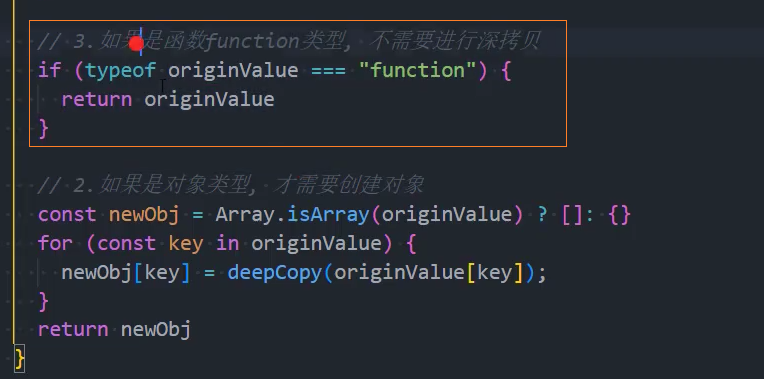
5、优化:其他类型-处理function
function: 不需要深拷贝
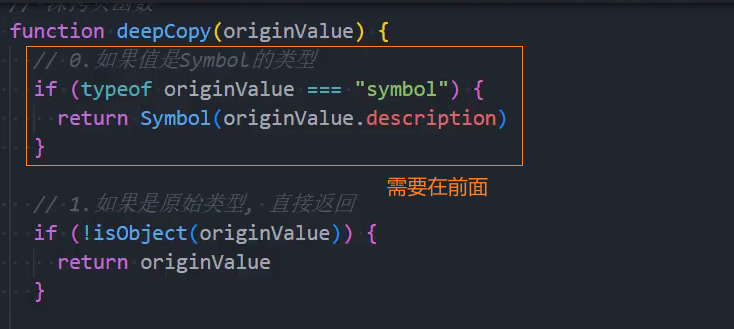
6、优化:其他类型-处理Symbol为值
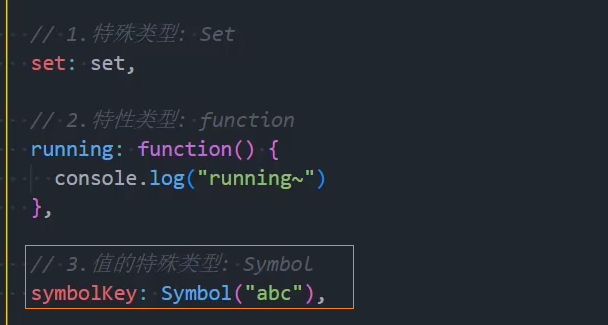
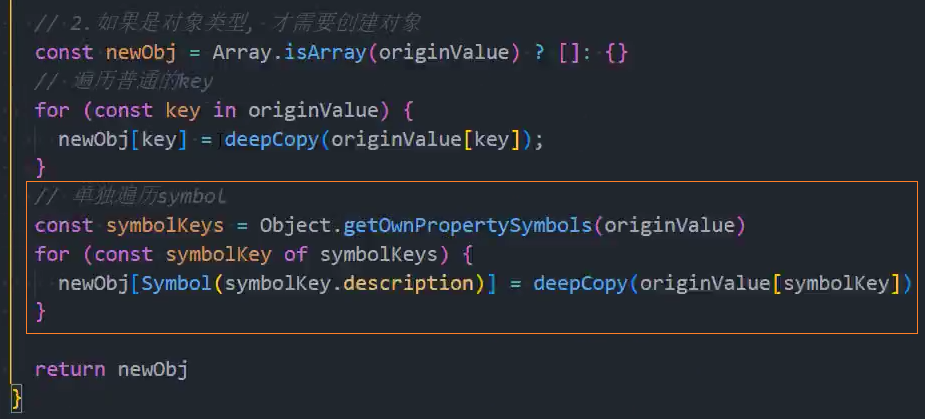
7、优化:其他类型-处理Symbol为key
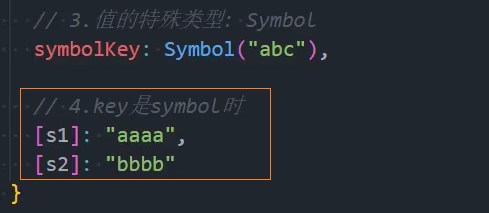
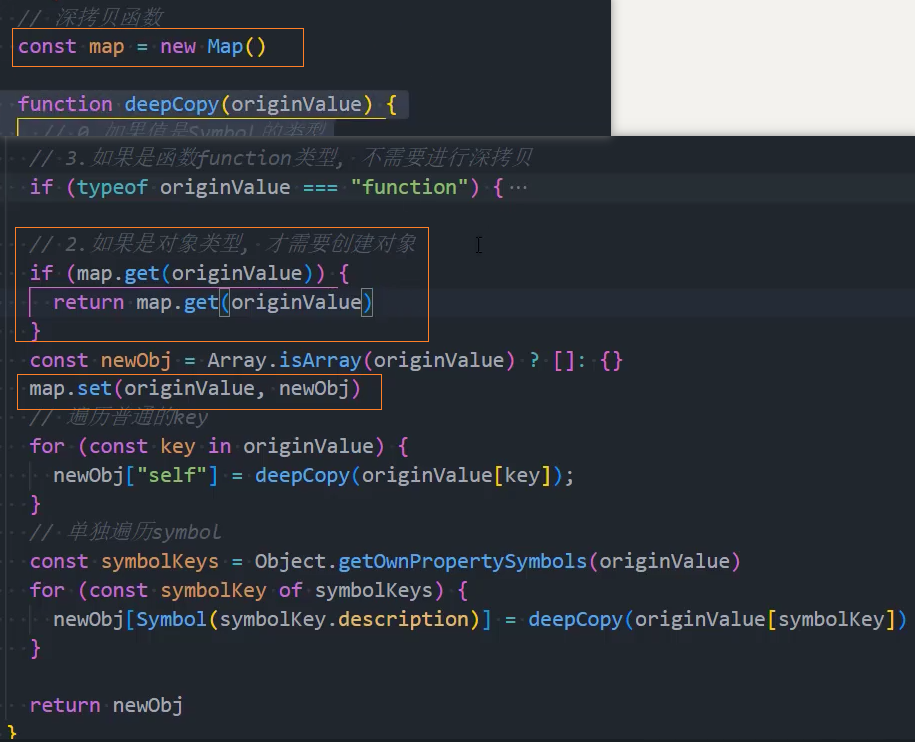
8、优化:处理循环引用
方案一:将每次新创建的对象保存到Map中,每次遍历前判断之前是否已经保存过了该对象
问题:需要在deeCopy外部定义一个map,并且每次拷贝完成后map依然会形成对对象的强引用,没有销毁
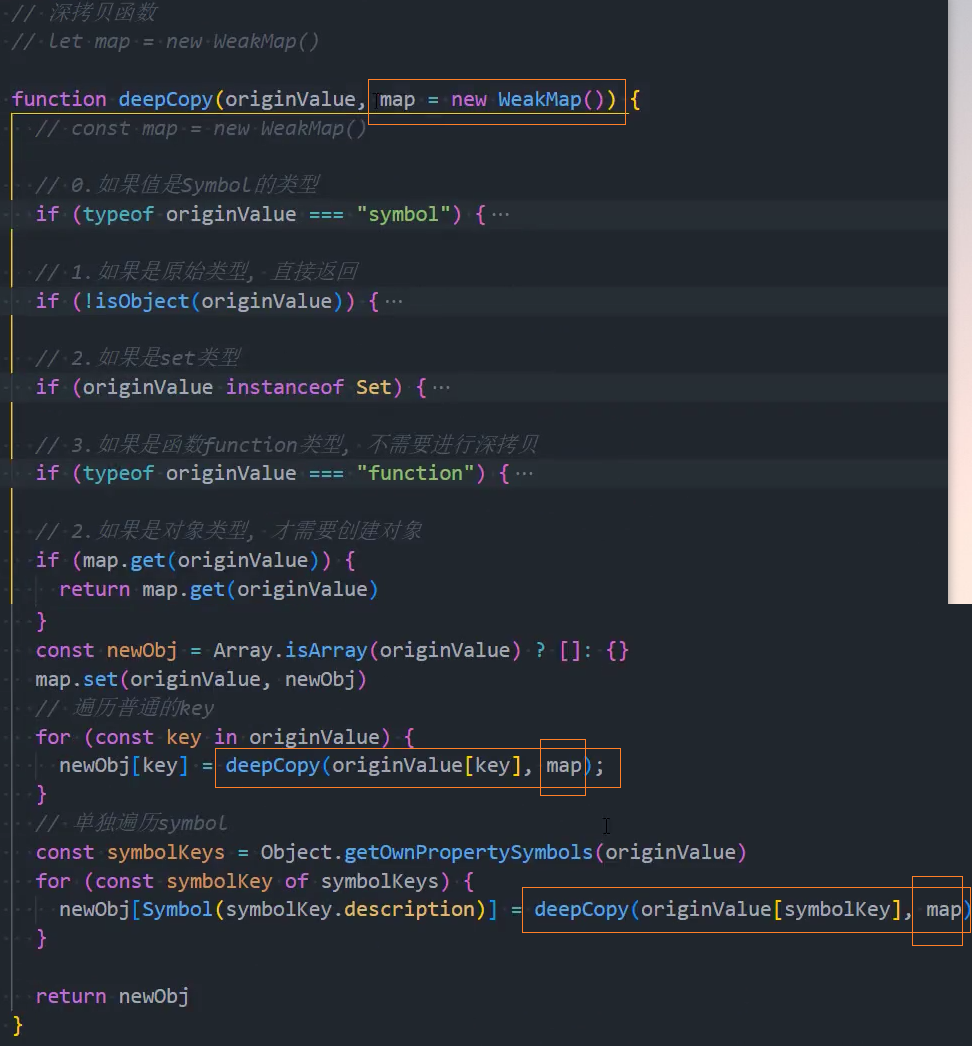
方案二(推荐):使用WeakMap替代Map;将map放入参数中并设置一个默认值new WeakMap()
手写-事件总线
自定义事件总线属于一种观察者模式,其中包括三个角色:
发布者(Publisher):发出事件(Event);
订阅者(Subscriber):订阅事件(Event),并且会进行响应(Handler);
事件总线(EventBus):无论是发布者还是订阅者都是通过事件总线作为中台的;
当然我们可以选择一些第三方库:
Vue2默认是带有事件总线的功能;
Vue3中推荐一些第三方库,比如mitt;
当然我们也可以实现自己的事件总线:
事件的监听方法on;
事件的发射方法emit;
事件的取消监听off;
1、基本实现
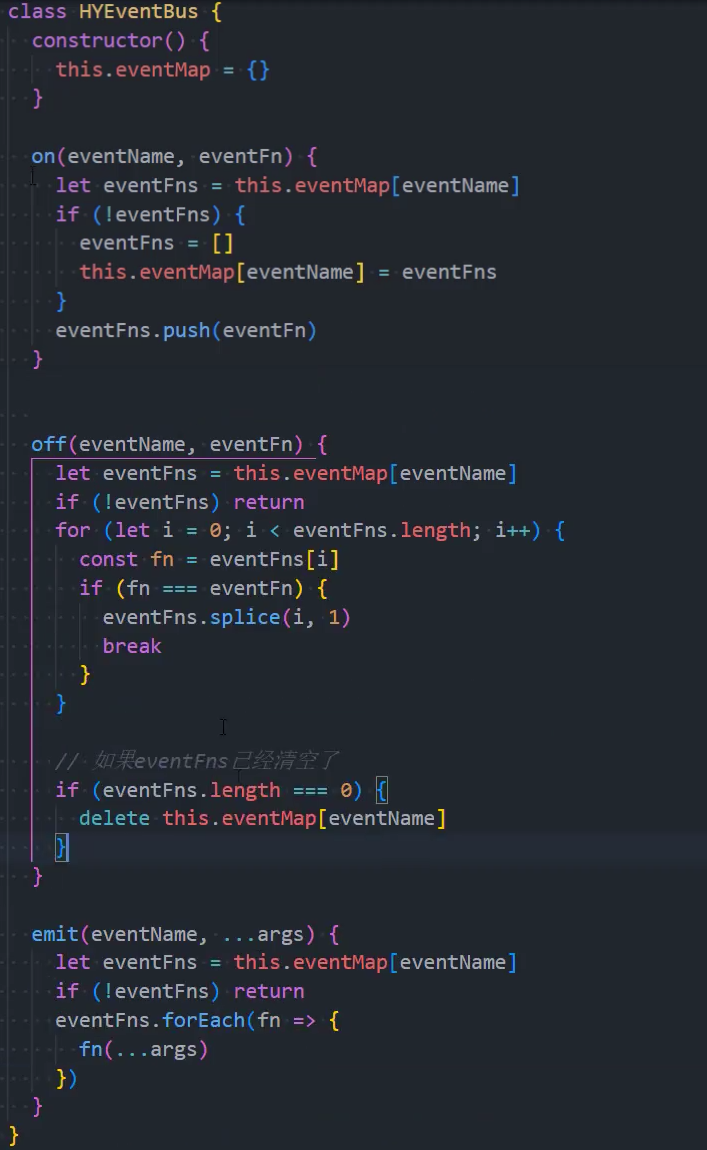
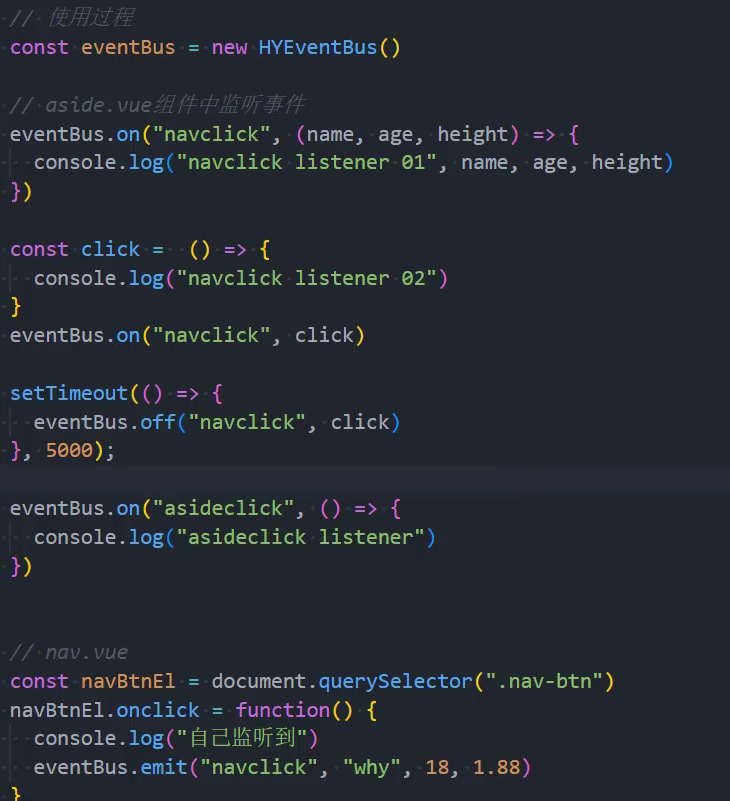
2、优化:绑定参数
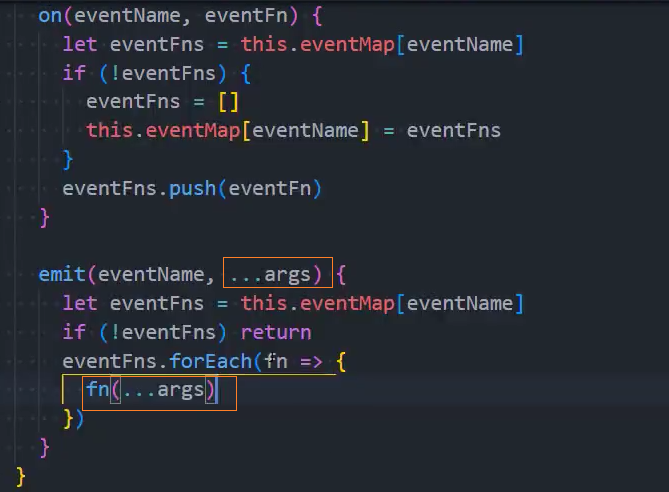
3、优化:移除监听