S16-00 专题-JS-正则
[TOC]
基础
基本使用
正则表达式(Regular Expression,简写:reg、re,正则表示式、正则表示法、规则表达式、常规表示法):是 JS 中处理文本模式匹配的核心工具,它使用特定语法创建搜索模式,用于在字符串中执行查找、替换、验证和提取操作。正则表达式在 JavaScript 中通过 RegExp 对象实现,并深度集成到字符串方法中。
- 维基百科:正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
- 简单概括:正则表达式是一种字符串匹配利器,可以帮助我们搜索、获取、替代字符串。
- 许多程序设计语言都支持利用正则表达式进行字符串操作。
语法结构:
在JavaScript中,正则表达式使用 RegExp类 来创建,也有对应的字面量的方式。
new RegExp():(pattern, flags?),用于动态创建正则表达式对象的构造函数,适用于模式需要运行时拼接的场景。
// 字面量形式(推荐)
const regex1 = /pattern/flags;
// 构造函数形式
const regex2 = new RegExp('pattern', 'flags');组成部分:
- 模式(patterns):定义正则表达式的匹配规则。
- 修饰符(flags):控制正则表达式的匹配行为。
基本示例:

正则测试网站:https://regex101.com/
常用方法
常用方法:
有了正则表达式我们要如何使用它呢?
JS 中的正则表达式被用于 RegExp 的 exec 和 test 方法。
也包括 String 的 match、matchAll、replace、search 和 split 方法。
RegExp
String:
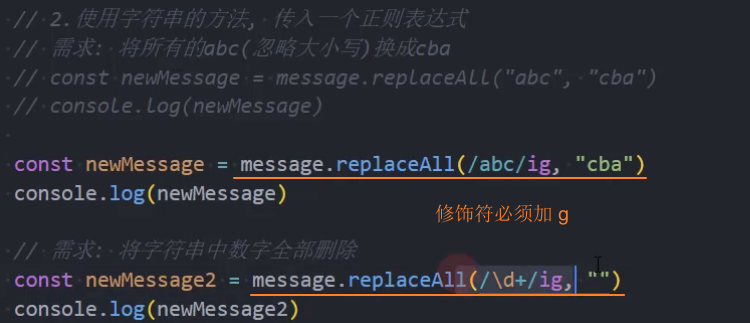
- str.match():
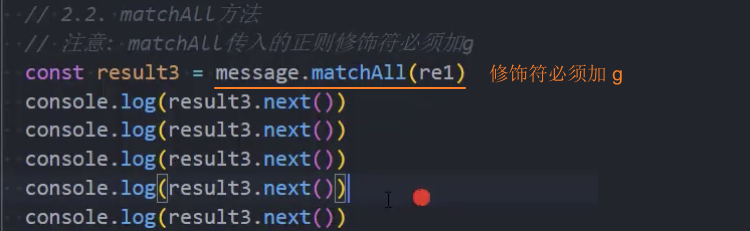
(regexp),支持正则,用于检索字符串中与正则表达式匹配的结果。 - str.matchAll():
(regexp),ES2020,支持正则,必须包含g,用于返回包含所有匹配正则表达式的结果及分组捕获组的迭代器。 - str.search():
(regexp),支持正则,用于检索字符串中匹配正则表达式的第一个位置。与indexOf()类似但支持正则表达式。 - str.replace():
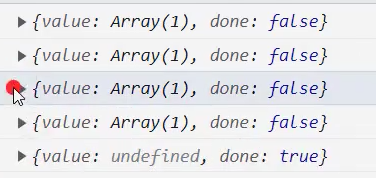
(searchValue, replaceValue),支持正则,用于替换字符串中匹配的子串。返回新字符串,支持字符串替换和正则表达式替换,并允许使用函数进行高级处理。 - str.replaceAll():
(searchValue, replaceValue),ES2021,支持正则,用于全局替换字符串中所有匹配的子串。无需正则表达式即可实现全量替换。 - str.split():
(separator?, limit?),支持正则,用于将字符串分割为子字符串数组。支持限制返回数组长度。
示例:

re.test()

re.exec()

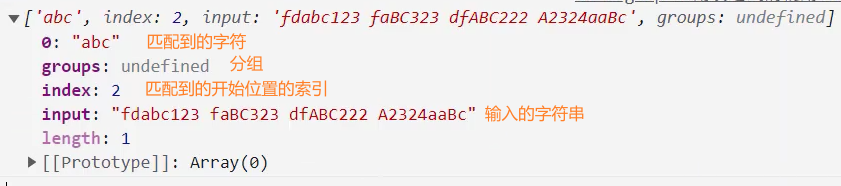
str.match()

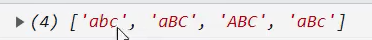
str.matchAll()
str.replace() / replaceAll()
str.split()


str.search()

修饰符
常见修饰符:
g:全局匹配。i:忽略大小写。m:多行匹配。s:允许.匹配换行符。u:使用 unicode 码的模式进行匹配。y:执行“粘性 (sticky)”搜索,匹配从目标字符串的当前位置开始。
示例:
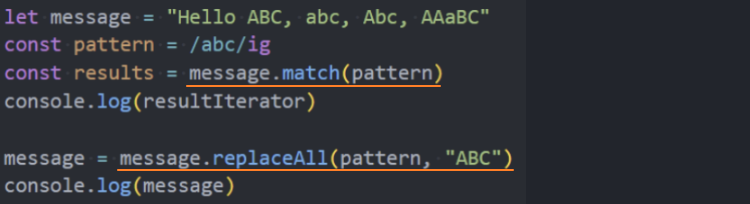
获取一个字符串中所有的abc;
将一个字符串中的所有abc换成大写;
规则
字符类
字符类(Character Classes):是一个特殊的符号,匹配特定集中的任何符号。
\d:匹配任何数字 (阿拉伯数字)。相当于[0-9]。\s:匹配单个空白字符,包括空格、制表符、换页符、换行符和其他 Unicode 空格。相当于[\f\n\r\t\v]。\w:匹配基本拉丁字母中的任何字母数字字符,包括下划线。相当于[A-Za-z0-9_]。.:匹配除行终止符之外的任何单个字符。终止符:\n,\r\D:匹配任何非数字 (阿拉伯数字) 的字符。相当于[^0-9]。\S:匹配除空格以外的单个字符。相当于[^\f\n\r\t\v]。\W:匹配任何不是来自基本拉丁字母的单词字符。相当于[^A-Za-z0-9_]。\r:匹配回车符。\n:匹配换行符。\f:匹配换页符。\t:匹配水平制表符。\v:匹配垂直制表符。\:指示应特殊处理或“转义”后面的字符。
示例:匹配字符

断言
边界类断言:
^:匹配输入的开头。如果多行模式设为 true,^在换行符后也能立即匹配。$:匹配输入的结束。如果多行模式设为 true,$在换行符前也能立即匹配。\b:匹配一个单词的边界。\B:匹配非单词边界。
其他断言:
x(?=y):先行断言: x 被 y 跟随时匹配 x。x(?!y):先行否定断言: x 没有被 y 紧随时匹配 x。(?<=y)x:后行断言: x 跟随 y 的情况下匹配 x。(?<!y)x:后行否定断言: x 不跟随 y 时匹配 x。
锚点:
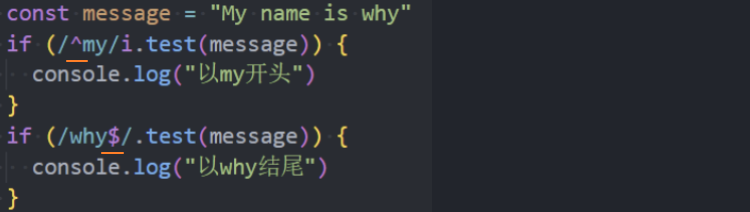
符号 ^ 和符号 $ 在正则表达式中具有特殊的意义,它们被称为“锚点”。
符号 ^ 匹配文本开头;
符号 $ 匹配文本末尾;
示例:使用^和$
词边界(Word Boundary):
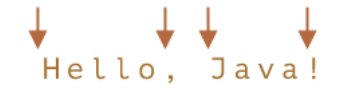
词边界 \b 是一种检查,就像 ^ 和 $ 一样,它会检查字符串中的位置是否是词边界。
词边界测试 \b 检查位置的一侧是否匹配 \w,而另一侧则不匹配 “\w”
在字符串 Hello, Java! 中,以下位置对应于 \b:
示例:匹配下面字符串中的时间

转义字符串
语法格式:如果要把特殊字符作为常规字符来使用,需要在它前面加个反斜杠 \ 对其进行转义。
常见的需要转义的字符:
正则表达式中使用到的特殊字符都需要转义。

/:并不是一个特殊符号,但是在字面量正则表达式中也需要转义;
示例:
示例:匹配所有以
.js或者.jsx结尾的文件名在 webpack 中就是以这样的方式匹配文件名

示例:只匹配
.点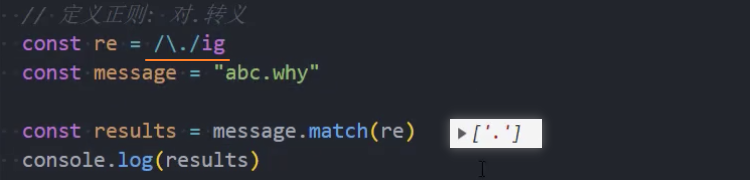
集合、范围
集合(Sets):[xyz]
有时候我们只要选择多个匹配字符的其中之一就可以:
在方括号
[…]中的几个字符或者字符类意味着“搜索给定的字符中的任意一个”;比如说,
[eao]意味着查找在 3 个字符 ‘a’、‘e’ 或者 ` ‘o’ 中的任意一个;
范围(Ranges):[a-z]
方括号也可以包含字符范围。示例:
[a-z]:会匹配从 a 到 z 范围内的字母。[0-5]:表示从 0 到 5 的数字。[0-9A-F]:表示两个范围:它搜索一个字符,满足数字 0 到 9 或字母 A 到 F。\d:和[0-9]相同。\w:和[a-zA-Z0-9\_]相同。
示例: 匹配手机号码
// 手机号
/^1[3-9]\d{9}$/排除范围:除了普通的范围匹配,还有类似 [^…] 的 “排除”范围匹配;
量词
需求示例:假设我们有一个字符串 +7(903)-123-45-67,并且想要找到它包含的所有数字。
- 因为它们的数量是不同的,所以我们需要给与数量一个范围;
量词( Quantifiers ):用来形容我们所需要的数量的词。
语法:
{m}: 确切的位数:{5}{m,n}: 某个范围的位数:{3,5}
注意:
{m,n}此处逗号后面不能加空格
缩写:
+:代表“一个或多个”,相当于{1,}?:代表“零个或一个”,相当于{0,1}。换句话说,它使得符号变得可选;*:代表着“零个或多个”,相当于{0,}。也就是说,这个字符可以多次出现或不出现;
示例: 匹配开始或结束标签

贪婪模式、惰性模式
需求示例:如果我们有这样一个需求:匹配下面字符串中所有使用 《》 包裹的内容


贪婪模式( Greedy):默认情况下的匹配规则是查找到匹配的内容后,会继续向后查找,一直找到最后一个匹配的内容。
惰性模式( lazy):只要获取到对应的内容后,就不再继续向后匹配,懒惰模式中的量词与贪婪模式中的相反。通过在量词后面添加?来启用(如+? / *? / ??)。
示例:启用惰性模式

捕获组
捕获组(Capturing Group):模式的一部分可以用括号括起来 (...)。
作用:
它允许将匹配的一部分作为结果数组中的单独项。
它将括号视为一个整体。
匹配结果:方法 str.match(re),如果 re 没有 g 标志,将查找第一个匹配并将它作为一个数组返回:
在索引 0 处:完全匹配。
在索引 1 处:第一个括号的内容。
在索引 2 处:第二个括号的内容。
…等等…
示例:
匹配到HTML标签,并且获取其中的内容

匹配所有
《》包裹的内容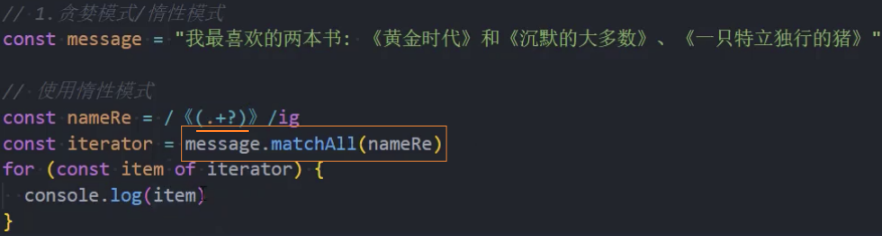

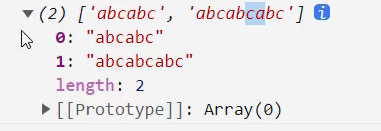
将捕获组作为整体

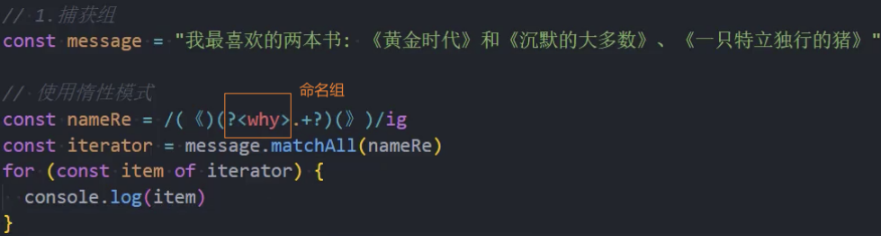
命名组
命名组:ES2018
用数字记录组很困难。
对于更复杂的模式,计算括号很不方便。我们有一个更好的选择:给括号起个名字。
这是通过在开始括号之后立即放置
?<name>来完成的。如(?<name>xxx)
示例:命名组

非捕获组
非捕获组:
有时我们需要括号才能正确应用量词,但我们不希望它们的内容出现在结果中。
可以通过在开头添加
?:来排除组。如(?:xxx)
示例:非捕获组

or
or:|,是正则表达式中的一个术语,实际上是一个简单的“或”。通常和捕获组一起来使用,在其中表示多个值。
示例:or


对比 集合:
- or:可以给多个字符分类:
(abc|cba|nba)表示abc或cba或nba。 - 集合:只能给单个字符分类:
[abc]表示a或b或c。
反向引用
反向引用(Backreferences):允许你引用先前捕获组匹配的内容,用于检测重复模式或匹配对称结构。
基本语法:
- 使用
\n引用第 n 个捕获组(n 为数字) - 组编号从 1 开始,按左括号顺序计数
- 引用必须在捕获组定义之后
// 匹配重复单词
const duplicateWords = /(\b\w+\b)\s+\1/gi;
console.log(duplicateWords.test("hello hello")); // true,\1 必须是 "hello" 这个字符串。
console.log(duplicateWords.test("hello world")); // false工作原理:
- 捕获组匹配:
(\b\w+\b)匹配整个单词并捕获 - 引用捕获内容:
\1引用第一个捕获组匹配的内容 - 精确匹配:要求后续文本与捕获组内容完全一致
核心特性:
匹配过程解析:
text模式: /(a)(b)\1\2/ 输入: "abab" 1. (a) 匹配并捕获 "a" 2. (b) 匹配并捕获 "b" 3. \1 引用第一个捕获组 "a" → 匹配 "a" 4. \2 引用第二个捕获组 "b" → 匹配 "b"
应用场景:
HTML 标签配对:
js// HTML标签配对 const htmlTag = /<(\w+)>.*?<\/\1>/; "<div>Content</div>".match(htmlTag); // 匹配 div "<p>Text</div>".match(htmlTag); // 不匹配 p引号配对:
js// 引号配对 const quotes = /(['"])(.*?)\1/; `"Hello" and 'World'`.match(quotes); // 匹配 "
案例
歌词解析
歌词地址:http://123.207.32.32:9002/lyric?id=167876

实现代码:
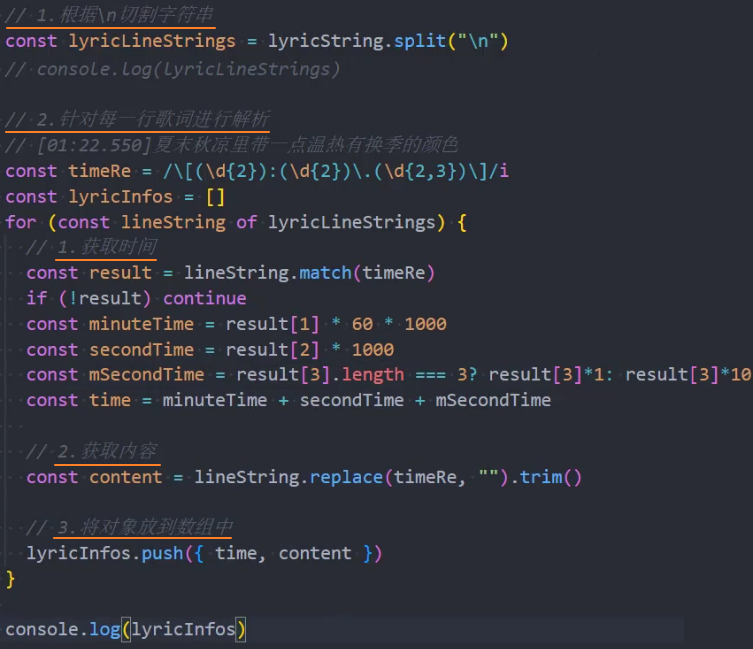
输出:

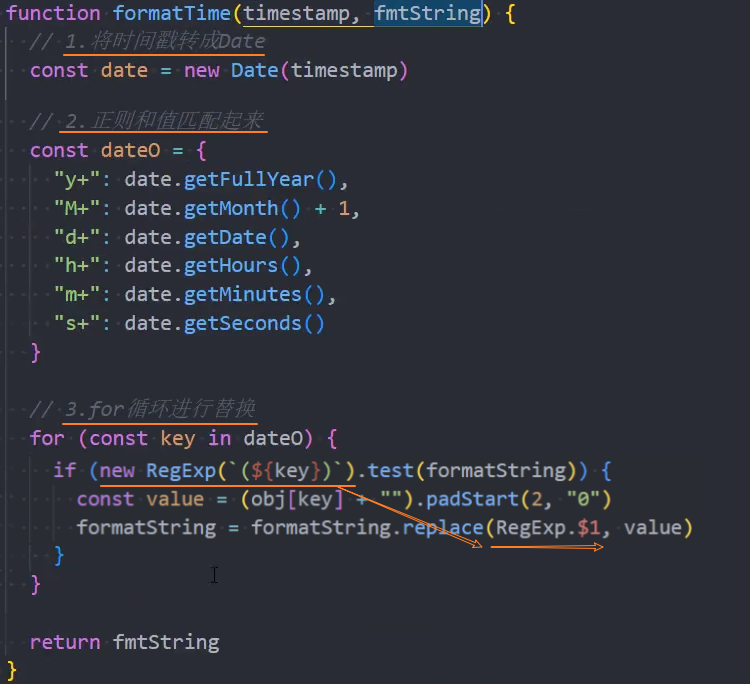
时间格式化
时间格式化:从服务器拿到时间戳,转成想要的时间格式
使用:将时间戳格式转成日常时间格式
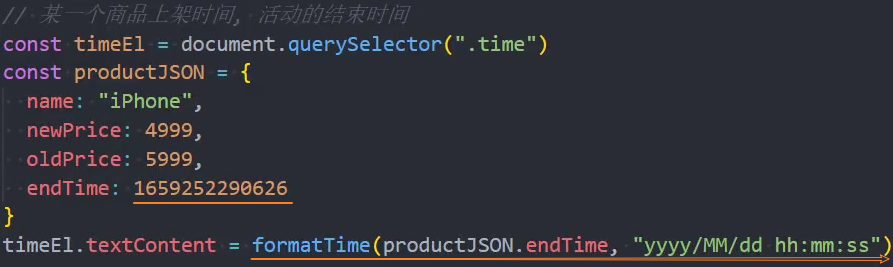
实现代码: