Node-内置模块
[TOC]
内置模块
path
概述
作用: 用于对路径和文件进行处理
痛点: mac、linux、windows 上路径分隔符格式不同
- windows:使用
\或者\\来作为文件路径的分隔符,目前也支持/; - Mac、Linux、Unix:使用
/来作为文件路径的分隔符;
解决: 为了屏蔽他们之间的差异,在开发中对于路径的操作我们可以使用 path 模块
API
const path = require('path')
const p1 = 'C://temp/user/index.js'
const p2 = '/web/test'path.dirname():
(p1),获取文件目录p1:
string,路径字符串文件路径字符串:返回该文件所在的目录部分目录路径字符串:返回该目录的上一级目录
返回:
dir:
string,返回该路径的目录部分- js
const path = require('path') console.log(path.dirname('/Users/johndoe/Documents/file.txt')) // /Users/johndoe/Documents console.log(path.dirname('/Users/johndoe/Documents/')) // /Users/johndoe
path.basename():
(p1, extension?),获取文件名。p1:
string,要获取文件名的路径字符串extension?:
string,指定要排除的文件扩展名返回:
filename:
string,文件名。- js
const path = require('path') const filename = path.basename('/Users/johndoe/Documents/file.txt'=) // file.txt const filename = path.basename('/Users/johndoe/Documents/file.txt', '.txt') // file
path.extname():
(p1),获取文件扩展名p1:
string,要获取文件扩展名的路径字符串返回:
extension:
string,返回文件扩展名- js
const path = require('path') path.extname('/Users/johndoe/Documents/file.txt') // .txt path.extname('/Users/johndoe/Documents/file') // '' path.extname('/Users/johndoe/Documents/') // ''
path.join():
(...paths?),用于将多个路径片段拼接成一个完整的路径(解析./../)...paths?:
string,要拼接的路径片段返回:
joinedPath:
string,返回拼接完成的路径注意:
join()可以兼容不同操作系统的分隔符join()可以解析./和../
- js
const path = require('path') path.join('/path', 'to', 'directory') // /path/to/directory // 注意:此处和resolve不同 path.join('/path/', '/to/', '/directory/') // /path/to/directory path.join('/path', '../relative') // /relative
path.resolve():
(...paths?),将多个路径拼接(解析./../),返回一个绝对路径...paths?:
string,要解析的路径片段返回:
resolvedPath:
string,返回解析完成的绝对路径注意:
- 拼接顺序从右到左,依次解析 path,直到构成一个绝对路径。若始终没有形成绝对路径,则继续拼接当前工作目录
- 返回的路径会去除尾部的/
- 不传参数,返回当前目录
resolve()可以解析./和../
- js
const path = require('path'); path.resolve('/path', 'to', 'directory')) // /path/to/directory path.resolve('/path/', '/to/', '/directory/') // /directory path.resolve('/path', '../relative') ///relative path.resolve('abc.txt') // /Users/04_learn_node/06_常见的内置模块/02_文件路径/abc.txt - js
// 应用:在 webpack 中使用 resolve() const CracoLessPlugin = require('craco-less') const path = require('path') const resolve = (dir) => path.resolve(__dirname, dir) module.exports = { plugins: [ { plugin: CracoLessPlugin, options: { lessLoaderOptions: { lessOptions: { modifyVars: { '@primary-color': '#1DA57A' }, javascriptEnabled: true } } } } ], webpack: { alias: { '@': resolve('src'), components: resolve('src/components') } } }
fs
概述
~~概念:~~fs 是 File System 的缩写,表示文件系统。
痛点: 任何服务器端语言都需要有自己的文件系统,方便将各种数据、文件等放到不同的地方
作用: 提供了一组功能丰富的方法来处理文件系统操作。包括创建、读取、写入和操作文件和目录
特点:
- 跨系统:借助 Node 的文件系统,可以在任何的操作系统(window、Mac、Linux)上直接操作文件
文档: https://nodejs.org/dist/latest-v14.x/docs/api/fs.html
操作方式:
- 同步操作:代码会被阻塞,后续代码不会继续执行
- 异步操作-回调函数:代码不会被阻塞,需要传入回调函数,当获取到结果时,调用回调函数
- 异步操作-Promise:代码不会被阻塞,通过 fs.promises 调用方法操作,会返回一个 Promise,可以通过 then, catch 处理结果
基本使用
这里以获取一个文件的状态为例:
*注意:*需要提前引入 fs 模块;
~~方式一:~~同步操作文件
// 1.方式一: 同步读取文件
const state = fs.statSync('../foo.txt')
console.log(state)
console.log('后续代码执行')~~方式二:~~异步回调函数操作文件
// 2.方式二: 异步读取
fs.stat('../foo.txt', (err, state) => {
if (err) {
console.log(err)
return
}
console.log(state)
})
console.log('后续代码执行')~~方式三:~~异步 Promise 操作文件
// 3.方式三: Promise方式
fs.promises
.stat('../foo.txt')
.then((state) => {
console.log(state)
})
.catch((err) => {
console.log(err)
})
console.log('后续代码执行')文件描述符
概念: 文件描述符(File descriptors):在 POSIX 系统上,对于每个进程,内核都维护着一张当前打开着的文件和资源的表格。每个打开的文件都分配了一个称为文件描述符的简单的数字标识符。在系统层,所有文件系统操作都使用这些文件描述符来标识和跟踪每个特定的文件。Windows 系统使用了一个虽然不同但概念上类似的机制来跟踪资源。为了简化用户的工作,Node.js 抽象出操作系统之间的特定差异,并为所有打开的文件分配一个数字型的文件描述符。
作用:
- 从文件读取数据:fs.readFile()
- 向文件写入数据:fs.writeFile()
- 请求关于文件的信息:fs.fstat()
fs.open() 方法用于分配新的文件描述符
// 获取文件描述符
fs.open('../foo.txt', 'r', (err, fd) => {
console.log(fd)
fs.fstat(fd, (err, state) => {
console.log(state)
})
})API
对象
fs.Stats
说明: 提供了一些常用的方法和属性,用于获取文件或目录的不同信息
常见属性:
- stats.size:文件大小(以字节为单位)。
- stats.mtime:文件的最后修改时间。
- stats.ctime:文件的创建时间。
常见方法:
- stats.isFile():判断是否为文件。
- stats.isDirectory():判断是否为目录。
flags
说明: 打开文件的方式
选项:
- w:打开文件写入,默认值
- w+:打开文件进行读写,如果不存在则创建文件
- r:打开文件读取,读取时的默认值
- r+:打开文件进行读写,如果不存在那么抛出异常
- a:打开要写入的文件,将流放在文件末尾。如果不存在则创建文件
- a+:打开文件以进行读写,将流放在文件末尾。如果不存在则创建文件
fs.Dirent
说明: 表示文件或目录的信息
当使用 fs.readdir() 函数的 withFileTypes 选项时,返回的数组中的每个元素都是 fs.Dirent 对象,其中包含文件或目录的信息。
常用属性:
- dirent.name:文件或目录的名称
常用方法:
- dirent.isFile():见dirent.isFile()
- dirent.isDirectory():见 dirent.isDirectory()
示例:
const fs = require('fs')
fs.readdir('path/to/directory', { withFileTypes: true }, (err, files) => {
if (err) {
console.error(err)
return
}
files.forEach((dirent) => {
;+console.log(`Name: ${dirent.name}`)
console.log('---')
})
})fs.FileHandle
说明: FileHandle 对象表示一个打开的文件句柄。它提供了与文件描述符相同的功能,可以使用它的方法进行文件的读写和关闭操作。
常用属性:
- filehandle.fd:
integer,获取到与之关联的文件描述符
常用方法:
- filehandle.read(buffer, offset?, length?, position?):``,异步地从文件中读取数据
- filehandle.write(buffer, offset?, length?, position?):``,异步地向文件中写入数据
- filehandle.appendFile(data, options?):``,异步地将指定的数据追加到文件末尾,如果文件不存在,则会创建文件
- filehandle.close():``,关闭文件句柄,释放资源
FileHandle VS 文件描述符:
关系:
FileHandle类是基于文件描述符的封装,提供了更方便的异步操作语法。- 可以通过
FileHandle对象的.fd属性获取到与之关联的文件描述符。
区别:
- 当使用
fs.open()或fs.openSync()方法打开一个文件时,会返回一个文件描述符。 - 使用
fs.promises.open()方法打开文件时,会返回一个FileHandle对象,而不是文件描述符。
文件、目录信息
fs.stat()
说明: 获取文件或目录的详细信息
语法:
fs.stat(path, options?, callback)参数:
- path:
string | Buffer | URL,要获取信息的文件或目录的路径 - options?:
{ bigint },- bigint:
boolean(false),返回的 fs.Stats对象中的数字值是否使用 bigint
- bigint:
- callback:
(err, stats) => {},- err:
Error,判断是否发生了错误 - stats:
fs.Stats,通过 fs.Stats对象获取各种有关文件或目录的信息
- err:
返回值: undefined
示例:
// 方式二:异步回调函数
const res = fs.stat('./file/d03.txt', (err, stats) => {
console.log('是否为文件:', stats.isFile())
console.log('是否为目录:', stats.isDirectory())
console.log('修改时间:', stats.mtime)
console.log('创建时间:', stats.ctime)
console.log('文件大小:', stats.size)
})
console.log(res) // undefined
console.log('后续代码执行')fs.promises.stat()
说明: 获取文件或目录的详细信息
语法:
fs.promises.stat(path, options?)参数:
- path:
string | Buffer | URL,要获取信息的文件或目录的路径 - options?:
{ bigint },- bigint:
boolean(false),返回的 fs.Stats对象中的数字值是否使用 bigint
- bigint:
返回值:
- Promise:
.then((stats) => {}),.catch((err) => {})- err:
Error,判断是否发生了错误 - stats:
fs.Stats,通过 fs.Stats对象获取各种有关文件或目录的信息
- err:
示例:
// 方式三:异步Promise
fs.promises.stat('./file/d03.txt').then((stats) => {
console.log('异步Promise', stats)
})
console.log('后续代码执行')fs.statSync()
说明: 获取文件或目录的详细信息
语法:
const stats = fs.statSync(path, options?)参数:
- path:
string | Buffer | URL,要获取信息的文件或目录的路径 - options?:
{ bigint },- bigint:
boolean(false),返回的 fs.Stats对象中的数字值是否使用 bigint - throwIfNoEntry:
boolean(true),如果没有文件不存在,则抛出异常
- bigint:
返回值:
- stats:
fs.Stats,通过 fs.Stats对象获取各种有关文件或目录的信息
示例:
// 方式一:同步
const stats = fs.statSync('./file/d03.txt')
console.log(stats)
console.log('后续代码执行')fs.fstat()
说明: 通过 fd 获取文件或目录的详细信息
语法:
fs.fstat(fd, options?, callback)参数:
- fd:
number,要获取信息的文件或目录的文件描述符 - options?:
{ bigint },- bigint:
boolean(false),返回的 fs.Stats对象中的数字值是否使用 bigint
- bigint:
- callback:
(err, stats) => {},- err:
Error,判断是否发生了错误 - stats:
fs.Stats,通过 fs.Stats对象获取各种有关文件或目录的信息
- err:
返回值: undefined
注意: 通过文件描述符打开的文件,默认不会自动关闭,需要通过fs.close()手动关闭
示例:
const fs = require('fs')
fs.open('file.txt', 'r', (err, fd) => {
if (err) {
console.error(err)
} else {
;+fs.fstat(fd, (err, stats) => {
if (err) {
console.error(err)
} else {
console.log(`是否为文件:${stats.isFile()}`)
console.log(`是否为目录:${stats.isDirectory()}`)
console.log(`文件大小:${stats.size} 字节`)
console.log(`最后修改时间:${stats.mtime}`)
console.log(`创建时间:${stats.ctime}`)
}
fs.closeSync(fd) // 关闭文件描述符
})
}
})文件、目录重命名
fs.rename()
说明: 重命名文件或目录
语法:
fs.rename(oldPath, newPath, callback)参数:
- oldPath:
string | Buffer | URL,需要重命名或移动的文件路径 - newPath:
string | Buffer | URL,目标文件的路径,即要将文件重命名或移动到的位置 - callback:
(err) => {},当文件重命名或移动完成后调用的回调函数,该函数接收一个错误参数- err:
Error,错误
- err:
返回值: undefined
示例:
// 将文件从 oldPath 重命名为 newPath
fs.rename('oldPath/file.txt', 'newPath/file_renamed.txt', (err) => {
if (err) {
console.error(err)
} else {
console.log('文件重命名成功!')
}
})fs.promises.rename()【
fs.renameSync()【
打开文件
fs.open()
说明: 异步打开文件
语法:
fs.open(path, flags?, mode?, callback)参数:
- path:
string | Buffer | URL,要打开的文件路径 - flags?:
string | number,D: r,打开文件的方式,见flags模式 - mode?:
string | integer,D: 0O666(readable and writable),指定文件打开模式 - callback:
(err, fd) => {},当文件打开完成后调用的回调函数- err:
Error,错误 - fd:
integer,打开的文件描述符
- err:
返回值: undefined
注意:
- 通过
open()打开的文件,在完成操作之后建议手动使用fs.close()关闭文件 - 获取到文件描述符
fd之后,可以用来读取文件、写入文件、读取文件信息fs.fstat()
示例:
const fs = require('fs')
// 打开文件并获取文件描述符
fs.open('path/to/file.txt', 'r', (err, fd) => {
if (err) {
console.error(err)
} else {
console.log('文件打开成功,文件描述符为:', fd)
// 在这里可以进行对文件的读取或写入操作
// ...
// 关闭文件
fs.close(fd, (err) => {
if (err) {
console.error(err)
} else {
console.log('文件关闭成功!')
}
})
}
})fs.promises.open()
**说明:**异步 Promise 打开文件
语法:
const promise = fs.promises.open(path, flags?, mode?)参数:
- path:
string | Buffer | URL,要打开的文件路径 - flags?:
string | number,D: r,打开文件的方式,见flags模式 - mode?:
string | integer,D: 0O666(readable and writable),指定文件打开模式
返回值:
- promise:
Promise,then(fileHandle),catch(err),当文件成功打开时,该对象将被解析为一个 fs.FileHandle 对象,可以通过该对象进行对文件的读取、写入等操作。
示例:
const fs =
require('fs').promises +
fs.promises
.open('path/to/file.txt', 'r')
.then((fileHandle) => {
const buffer = Buffer.alloc(1024) // 创建一个缓冲区用于存储读取的数据
return fileHandle.read(buffer, 0, buffer.length, 0).then(({ bytesRead }) => {
console.log(`Read ${bytesRead} bytes from the file.`)
console.log(buffer.toString('utf8', 0, bytesRead))
return fileHandle.close() // 关闭文件
})
})
.catch((error) => {
console.error(error)
})fs.openSync()
说明: 同步方式打开文件并返回一个文件描述符
语法:
const fd = fs.openSync(path, flags?, mode?)参数:
- path:
string | Buffer | URL,要打开的文件路径 - flags?:
string | number,D: r,打开文件的方式,见flags模式 - mode?:
string | integer,D: 0O666(readable and writable),指定文件打开模式
返回值:
- fd:
integer,返回文件描述符,表示打开的文件
示例:
const fs = require('fs')
try {
+ const fileDescriptor = fs.openSync('path/to/file.txt', 'r')
const buffer = Buffer.alloc(1024) // 创建一个缓冲区用于存储读取的数据
const bytesRead = fs.readSync(fileDescriptor, buffer, 0, buffer.length, 0)
console.log(`Read ${bytesRead} bytes from the file.`)
console.log(buffer.toString('utf8', 0, bytesRead))
fs.closeSync(fileDescriptor) // 关闭文件
} catch (error) {
console.error(error)
}读取文件
fs.readFile()
说明: 异步地从文件中读取数据
语法:
fs.readFile(path, options?, callback)参数:
- path:
string | Buffer | URL | integer,要读取的文件的路径(可以是路径地址或文件描述符) - options?:
Object | string,用于指定读取选项,比如编码方式和文件打开模式等- encoding?:
string | null,D:null,指定编码方式,默认为null,即返回原始的Buffer数据 - flag?:
string,D: r,指定文件的打开模式,,见flags模式 - signal?:
AbortSignal,
- encoding?:
- callback:
(err, data) => {},回调函数,用于处理读取文件后的结果- err:
Error | AggregateError,错误 - data:
string | Buffer,读取到的文件内容,如果指定了encoding,则以字符串形式返回,否则返回Buffer对象。
- err:
返回值: undefined
示例:
const fs = require('fs')
fs.readFile('path/to/file.txt', { encoding: 'utf8' }, (err, data) => {
if (err) {
console.error(err)
return
}
console.log(data)
})fs.promises.readFile()【
fs.readFileSync()【
写入文件
fs.writeFile()
说明: 异步地写入数据到文件中
语法:
fs.writeFile(file, data, options?, callback)参数:
- file:
string | Buffer | URL | integer,要写入的文件的路径(可以是路径地址或文件描述符) - data:
string | Buffer | TypedArray |DataView,要写入的数据,可以是字符串、Buffer对象或 Uint8Array 等类型。 - options?:
Object |string,指定写入选项,比如编码方式和文件打开模式等- encoding?:
string | null,D:utf8,指定编码方式 - mode?:
integer,D: 0O666(readable and writable),指定文件打开模式 - flag?:
string,D: w,指定文件的打开模式,,见flags模式 - flush?:
boolean,D: false, - signal?:
AbortSignal,
- encoding?:
- callback:
(err) => {},回调函数,用于处理写入数据后的结果- err:
Error | AggregateError,错误
- err:
返回值: undefined
示例:
const fs = require('fs')
fs.writeFile('path/to/file.txt', 'Hello, world!', (err) => {
if (err) {
console.error(err)
return
}
console.log('File written successfully!')
})fs.promises.writeFile()【
fs.writeFileSync()【
关闭文件
fs.close()
说明: 关闭一个已经打开的文件
语法:
fs.close(fd, callback?)参数:
- fd:
integer,已经打开的文件描述符(file descriptor),可以通过fs.open()函数获取 - callback?:
(err) => {},回调函数,用于处理操作完成后的结果- err:
Error,错误
- err:
返回值: undefined
示例:
const fs = require('fs')
// 打开文件
fs.open('path/to/file.txt', 'r', (err, fd) => {
if (err) {
console.error(err)
return
}
console.log(`File opened with file descriptor ${fd}.`) +
// 关闭文件
fs.close(fd, (err) => {
if (err) {
console.error(err)
return
}
console.log(`File closed successfully.`)
})
})判断文件
dirent.isFile()
说明: 检查当前目录项(dirent)是否是一个文件
语法:
const isFile = dirent.isFile()参数: void
返回值:
- isFile:
boolean,是否是一个文件
示例:
const fs = require('fs')
// 遍历目录
fs.readdir('/path/to/directory', { withFileTypes: true }, (err, files) => {
if (err) {
console.error(err)
return
}
// 遍历目录项
files.forEach((file) => {
+ if (file.isFile()) {
console.log(`${file.name} is a file.`)
} else {
console.log(`${file.name} is not a file.`)
}
})
})创建目录
fs.mkdir()
说明: 创建一个新的目录
语法:
fs.mkdir(path, options?, callback)参数:
- path:
string | Buffer | URL,要创建的目录路径 - options?:
Object | integer,指定创建目录的选项- recursive?:
boolean,D: false,如果设置为true,则会递归地创建父级目录(如果父级目录不存在) - mode?:
string | ineteger,D: 0o777,指定目录的权限
- recursive?:
- callback:
(err, path?) => {},回调函数,用于处理操作完成后的结果- err:
Error,错误 - path?:
string | undefined,返回创建成功的目录的路径。仅在创建目录时将recursive设置为true时出现。
- err:
返回值: undefined
示例:
const fs = require('fs')
fs.mkdir('path/to/newdir', { recursive: true }, (err, path) => {
if (err) {
console.error(err)
return
}
console.log(`Directory created successfully at ${path}!`)
})读取目录中的文件
fs.readdir()
说明: 读取指定目录中的所有文件和子目录
语法:
fs.readdir(path, options?, callback)参数:
- path:
string | Buffer | URL,要读取的目录路径 - options?:
Object | string,指定读取目录的选项- encoding?:
string,D: utf8,指定返回的文件名的字符编码 - withFileTypes?:
boolean,D: false,如果设置为true,则返回的数组中将包含fs.Dirent对象(代表文件或子目录)而不是字符串 - recursive?:
boolean,D: false,是否递归变量所有子文件和目录
- encoding?:
- callback:
(err, files) => {},回调函数,用于处理操作完成后的结果- err:
Error,错误 - files:
string[] | Buffer[] | fs.Dirent[],读取到的文件名和子目录名
- err:
返回值: undefined
示例:
const fs =
require('fs') +
fs.readdir('path/to/directory', { withFileTypes: true }, (err, files) => {
if (err) {
console.error(err)
return
}
files.forEach((file) => {
console.log(file.name)
})
})使用: 递归读取文件夹
// 递归读取文件夹
function readFolders(folder) {
fs.readdir(folder, { withFileTypes: true }, (err, files) => {
files.forEach((file) => {
if (file.isDirectory()) {
const newFolder = path.resolve(dirname, file.name)
readFolders(newFolder)
} else {
console.log(file.name)
}
})
})
}
readFolders(dirname)判断目录
dirent.isDirectory()
说明: 检查当前对象是否是一个目录
语法:
const isDirectory = dirent.isDirectory()参数: void
返回值:
- isDirectory:
boolean,如果是目录,则返回true,否则返回false
示例:
const fs = require('fs')
fs.readdir('path/to/directory', { withFileTypes: true }, (err, files) => {
if (err) {
console.error(err)
return
}
files.forEach((file) => {
+ if (file.isDirectory()) {
console.log(`${file.name} is a directory`)
} else {
console.log(`${file.name} is a file`)
}
})
})events
概述
作用: events提供了用于处理事件的基本功能
基本使用
Node 中的核心 API 都是基于异步事件驱动的:
- 在这个体系中,某些对象(发射器(Emitters))发出某一个事件;
- 我们可以监听这个事件(监听器 Listeners),并且传入的回调函数,这个回调函数会在监听到事件时调用;
发出事件和监听事件都是通过 EventEmitter 类来完成的,它们都属于 events 对象。
emitter.on(eventName, listener):监听事件,也可以使用addListener;emitter.off(eventName, listener):移除事件监听,也可以使用removeListener;emitter.emit(eventName[, ...args]):发出事件,可以携带一些参数;
const EventEmmiter = require('events')
// 监听事件
const bus = new EventEmmiter()
function clickHanlde(args) {
console.log('监听到click事件', args)
}
bus.on('click', clickHanlde)
setTimeout(() => {
bus.emit('click', 'coderwhy')
bus.off('click', clickHanlde)
bus.emit('click', 'kobe')
}, 2000)API
EventEmitter【
常用方法
emitter.on()【
emitter.off()【
emitter.emit()【
emitter.once()【
emitter.removeAllListeners()【
其他方法
emitter.prependListener()【
emitter.prependOnceListener()【
emitter.eventNames()【
emitter.getMaxListenters()【
emitter.setMaxListeners()【
emitter.listenerCount()【
emitter.listeners()【
常见的属性
EventEmitter 的实例有一些属性,可以记录一些信息:
emitter.eventNames():返回当前EventEmitter对象注册的事件字符串数组;emitter.getMaxListeners():返回当前EventEmitter对象的最大监听器数量,可以通过setMaxListeners()来修改,默认是 10;emitter.listenerCount(事件名称):返回当前EventEmitter对象某一个事件名称,监听器的个数;emitter.listeners(事件名称):返回当前EventEmitter对象某个事件监听器上所有的监听器数组;
console.log(bus.eventNames())
console.log(bus.getMaxListeners())
console.log(bus.listenerCount('click'))
console.log(bus.listeners('click'))方法的补充
emitter.once(eventName, listener):事件监听一次
const EventEmitter = require('events')
const emitter = new EventEmitter()
emitter.once('click', (args) => {
console.log('监听到事件', args)
})
setTimeout(() => {
emitter.emit('click', 'coderwhy')
emitter.emit('click', 'coderwhy')
}, 2000)emitter.prependListener():将监听事件添加到最前面
emitter.on('click', (args) => {
console.log('a监听到事件', args)
})
// b监听事件会被放到前面
emitter.prependListener('click', (args) => {
console.log('b监听到事件', args)
})emitter.prependOnceListener():将监听事件添加到最前面,但是只监听一次
emitter.prependOnceListener('click', (args) => {
console.log('c监听到事件', args)
})emitter.removeAllListeners([eventName]):移除所有的监听器
// 移除emitter上的所有事件监听
emitter.removeAllListeners()
// 移除emitter上的click事件监听
emitter.removeAllListeners('click')buffer
二进制
计算机中所有的内容:文字、数字、图片、音频、视频最终都会使用二进制来表示。
JavaScript 可以直接去处理非常直观的数据:比如字符串,我们通常展示给用户的也是这些内容。
不对啊,JavaScript 不是也可以处理图片吗?
- 事实上在网页端,图片我们一直是交给浏览器来处理的;
- JavaScript 或者 HTML,只是负责告诉浏览器一个图片的地址;
- 浏览器负责获取这个图片,并且最终将这个图片渲染出来;
但是对于服务器来说是不一样的:
- 服务器要处理的本地文件类型相对较多;
- 比如某一个保存文本的文件并不是使用
utf-8进行编码的,而是用GBK,那么我们必须读取到他们的二进制数据,再通过 GKB 转换成对应的文字; - 比如我们需要读取的是一张图片数据(二进制),再通过某些手段对图片数据进行二次的处理(裁剪、格式转换、旋转、添加滤镜),Node 中有一个 Sharp 的库,就是读取图片或者传入图片的 Buffer 对其再进行处理;
- 比如在 Node 中通过 TCP 建立长连接,TCP 传输的是字节流,我们需要将数据转成字节再进行传入,并且需要知道传输字节的大小(客服端需要根据大小来判断读取多少内容);
我们会发现,对于前端开发来说,通常很少会和二进制打交道,但是对于服务器端为了做很多的功能,我们必须直接去操作其二进制的数据;
所以 Node 为了可以方便开发者完成更多功能,提供给了我们一个类 Buffer,并且它是全局的。
概述
Buffer 和二进制
我们前面说过,Buffer 中存储的是二进制数据,那么到底是如何存储呢?
- 我们可以将 Buffer 看成是一个存储二进制的数组;
- 这个数组中的每一项,可以保存 8 位二进制:
00000000
为什么是 8 位呢?
- 在计算机中,很少的情况我们会直接操作一位二进制,因为一位二进制存储的数据是非常有限的;
- 所以通常会将 8 位合在一起作为一个单元,这个单元称之为一个字节(byte);
- 也就是说
1byte = 8bit,1kb=1024byte,1M=1024kb; - 比如很多编程语言中的 int 类型是 4 个字节,long 类型是 8 个字节;
- 比如 TCP 传输的是字节流,在写入和读取时都需要说明字节的个数;
- 比如 RGB 的值分别都是 255,所以本质上在计算机中都是用一个字节存储的;
Buffer 和字符串
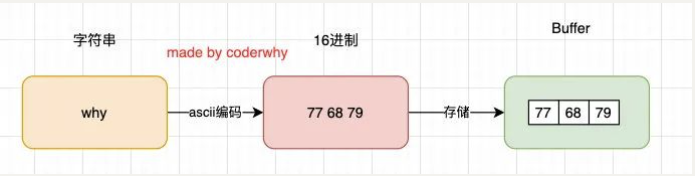
也就是说,Buffer 相当于是一个字节的数组,数组中的每一项对应一个字节的大小:
如果我们希望将一个字符串放入到 Buffer 中,是怎么样的过程呢?
const buffer01 = new Buffer('why')
console.log(buffer01)字符串存储 buffer 的过程
当然目前已经不希望我们这样来做了:
VSCode 的警告

那么我们可以通过另外一个创建方法:
const buffer2 = Buffer.from('why')
console.log(buffer2)如果是中文呢?
const buffer3 = Buffer.from('王红元')
console.log(buffer3)
// <Buffer e7 8e 8b e7 ba a2 e5 85 83>
const str = buffer3.toString()
console.log(str)
// 王红元如果编码和解码不同:会显示乱码
const buffer3 = Buffer.from('王红元', 'utf16le')
console.log(buffer3)
const str = buffer3.toString('utf8')
console.log(str) // �s�~CQ基本使用
创建 Buffer
Buffer 的创建方式有很多:
buffer 的创建

来看一下Buffer.alloc:
- 我们会发现创建了一个 8 位长度的 Buffer,里面所有的数据默认为 00;
const buffer01 = Buffer.alloc(8)
console.log(buffer01) // <Buffer 00 00 00 00 00 00 00 00>我们也可以对其进行操作:
buffer01[0] = 'w'.charCodeAt()
buffer01[1] = 100
buffer01[2] = 0x66
console.log(buffer01)也可以使用相同的方式来获取:
console.log(buffer01[0])
console.log(buffer01[0].toString(16))Buffer 文件读取
文本文件的读取:
const fs = require('fs')
fs.readFile('./test.txt', (err, data) => {
console.log(data) // <Buffer 48 65 6c 6c 6f 20 57 6f 72 6c 64>
console.log(data.toString()) // Hello World
})图片文件的读取:
fs.readFile('./zznh.jpg', (err, data) => {
console.log(data) // <Buffer ff d8 ff e0 ... 40418 more bytes>
})图片文件的读取和转换:
- 将读取的某一张图片,转换成一张 200x200 的图片;
- 这里我们可以借助于
sharp库来完成;
const sharp = require('sharp')
const fs = require('fs')
sharp('./test.png')
.resize(1000, 1000)
.toBuffer()
.then((data) => {
fs.writeFileSync('./test_copy.png', data)
})Buffer 内存分配
事实上我们创建 Buffer 时,并不会频繁的向操作系统申请内存,它会默认先申请一个 8 * 1024 个字节大小的内存,也就是 8kb
node 源码:
// node/lib/buffer.js:135行
Buffer.poolSize = 8 * 1024
let poolSize, poolOffset, allocPool
const encodingsMap = ObjectCreate(null)
for (let i = 0; i < encodings.length; ++i) encodingsMap[encodings[i]] = i
function createPool() {
poolSize = Buffer.poolSize
allocPool = createUnsafeBuffer(poolSize).buffer
markAsUntransferable(allocPool)
poolOffset = 0
}
createPool()假如我们调用 Buffer.from 申请 Buffer:
这里我们以从字符串创建为例
// node/lib/buffer.js:290行
Buffer.from = function from(value, encodingOrOffset, length) {
if (typeof value === 'string') return fromString(value, encodingOrOffset)
// 如果是对象,另外一种处理情况
// ...
}我们查看 fromString 的调用:
// node/lib/buffer.js:428行
function fromString(string, encoding) {
let ops
if (typeof encoding !== 'string' || encoding.length === 0) {
if (string.length === 0) return new FastBuffer()
ops = encodingOps.utf8
encoding = undefined
} else {
ops = getEncodingOps(encoding)
if (ops === undefined) throw new ERR_UNKNOWN_ENCODING(encoding)
if (string.length === 0) return new FastBuffer()
}
return fromStringFast(string, ops)
}接着我们查看 fromStringFast:
- 这里做的事情是判断剩余的长度是否还足够填充这个字符串;
- 如果不足够,那么就要通过
createPool创建新的空间; - 如果够就直接使用,但是之后要进行
poolOffset的偏移变化;
// node/lib/buffer.js:428行
function fromStringFast(string, ops) {
const length = ops.byteLength(string)
if (length >= Buffer.poolSize >>> 1) return createFromString(string, ops.encodingVal)
if (length > poolSize - poolOffset) createPool()
let b = new FastBuffer(allocPool, poolOffset, length)
const actual = ops.write(b, string, 0, length)
if (actual !== length) {
// byteLength() may overestimate. That's a rare case, though.
b = new FastBuffer(allocPool, poolOffset, actual)
}
poolOffset += actual
alignPool()
return b
}API
- Buffer.alloc(size[, fill[, encoding]])
- Buffer.from(string[, encoding])
- Buffer.isBuffer(obj)
- Buffer.poolSize
- buf[index]
- buf.toString([encoding[, start[, end]]])
stream
概述
定义:
- Stream 是一种处理流式数据的抽象接口
- Stream 可以将数据分成小块并逐个地进行处理,而无需等待整个数据集到达内存中
- Stream 可以用于处理各种类型的数据,包括文本、二进制、音频和视频等
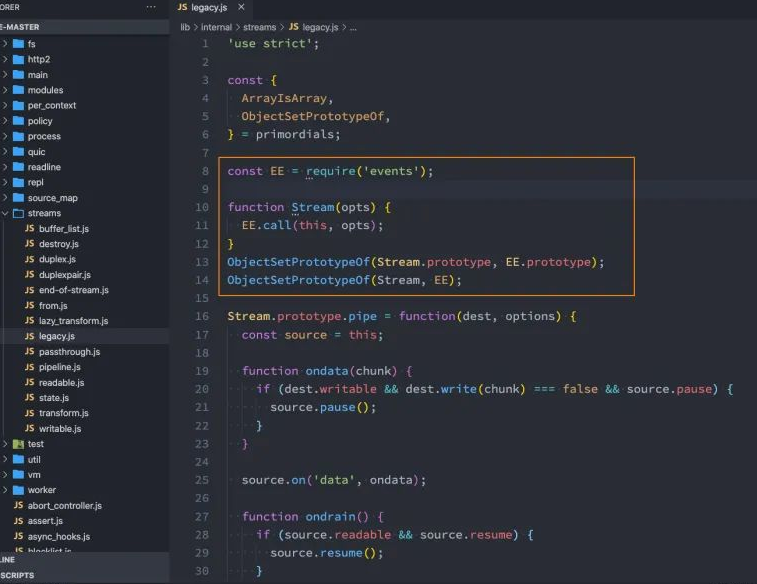
注意: 所有的流都是 EventEmitter 的实例
作用: 通过 stream 读写文件可以控制细节
- 从什么位置开始读、读到什么位置、一次性读取多少个字节
- 暂停读取、恢复读取
- 文件很大时,通过 stream 分批次写入
应用: 基于流实现的对象
- http 模块的 Request、Response 对象
- process.stdout 对象
流(Stream)的分类:
- Writable:可以向其写入数据的流(例如
fs.createWriteStream())。 - Readable:可以从中读取数据的流(例如
fs.createReadStream())。 - Duplex:同时为
Readable和的流Writable(例如net.Socket)。 - Transform:
Duplex可以在写入和读取数据时修改或转换数据的流(例如zlib.createDeflate())。
Stream 和 EventEmitter 关系:
Readable
一次性读取
之前我们读取一个文件的信息:
fs.readFile('./foo.txt', (err, data) => {
console.log(data)
})这种方式是一次性将一个文件中所有的内容都读取到程序(内存)中
问题:文件过大、读取的位置、结束的位置、一次读取的大小;
流式读取
这个时候,我们可以使用 createReadStream(),我们来看几个参数,更多参数可以参考官网:
- start:文件读取开始的位置;
- end:文件读取结束的位置;
- highWaterMark:一次性读取字节的长度,默认是 64kb;
基本使用
1、创建读取流
const read = fs.createReadStream('./foo.txt', {
start: 3,
end: 8,
highWaterMark: 4
})2、监听 data 事件,获取读取到的数据
read.on('data', (data) => {
console.log(data)
})监听其他的事件
read.on('open', (fd) => {
console.log('文件被打开')
})
read.on('end', () => {
console.log('文件读取结束')
})
read.on('close', () => {
console.log('文件被关闭')
})暂停和恢复读取
read.on('data', (data) => {
console.log(data)
read.pause()
setTimeout(() => {
read.resume()
}, 2000)
})Writable
一次性写入
之前我们写入一个文件的方式是这样的:
fs.writeFile('./foo.txt', '内容', (err) => {})这种方式相当于一次性将所有的内容写入到文件中
问题:无法一点点写入内容,精确每次写入的位置等
流式写入
这个时候,我们可以使用 createWriteStream(),我们来看几个参数,更多参数可以参考官网:
- flags:默认是
w,如果我们希望是追加写入,可以使用a或者a+; - start:写入的位置;
基本使用
我们进行一次简单的写入
const writer = fs.createWriteStream('./foo.txt', {
flags: 'a+',
start: 8
})
writer.write('你好啊', (err) => {
console.log('写入成功')
})另外一个非常常用的方法是 end:end方法相当于做了两步操作:write传入的数据和调用close方法;
writer.end('Hello World')监听其他事件
- open,监听文件打开事件
- finish:监听写入结束事件
- close:监听文件关闭事件
writer.on('open', () => {
console.log('文件打开')
})
writer.on('finish', () => {
console.log('文件写入结束')
})
writer.on('close', () => {
console.log('文件关闭')
})问题: 我们会发现,我们并不能监听到 close 事件
解决: 这是因为写入流在打开后是不会自动关闭的,我们必须手动关闭,来告诉 Node 已经写入结束了,并且会发出一个 finish 事件的
;+writer.close()
writer.on('finish', () => {
console.log('文件写入结束')
})
writer.on('close', () => {
console.log('文件关闭')
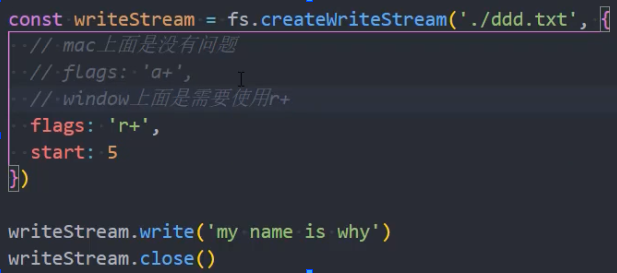
})问题: createWriteStream()中当 flags 为'a+'时,start 参数无效
分析: 在 mac 电脑中没有问题,但 windows 中存在该问题
解决: 在 windows 中的 flags 值设置为'r+'
pipe()
作用: 将一个可读流和一个可写流连接起来,使得从可读流中读取的数据可以自动写入到可写流中
语法:
readStream.pipe(dest, options?)一次性读取和写入
【TODO】
流式读取和写入
正常情况下,我们可以将读取到的 输入流,手动的放到 输出流中进行写入:
const fs = require('fs')
const { read } = require('fs/promises')
const reader = fs.createReadStream('./foo.txt')
const writer = fs.createWriteStream('./bar.txt')
reader.on('data', (data) => {
console.log(data)
writer.write(data, (err) => {
console.log(err)
})
})在可读、可写流之间建立管道
我们也可以通过 pipe 来完成这样的操作:
;+reader.pipe(writer)
writer.on('close', () => {
console.log('输出流关闭')
})API
继承-EventEmitter
Readable
fs.createReadStream()【
readable.on()【
readable.pause()【
readable.resume()【
readable.pipe()【
readable.setEncoding()【
Writable
fs.createWriteStream()【
writable.write()【
writable.on()【
writable.end()【
http
概述
web 服务器
~~概念:~~当应用程序(客户端)需要某一个资源时,可以向一个台服务器,通过 Http 请求获取到这个资源;提供资源的这个服务器,就是一个Web 服务器;

种类: 目前有很多开源的 Web 服务器:Nginx、Apache(静态)、Apache Tomcat(静态、动态)、Node.js
Node 中的 web 服务器: 在 Node 中,主要通过 http 模块实现 web 服务器
网络请求
【TODO】
基本使用
入门案例
创建一个 Web 服务器的初体验:
const http = require('http')
const HTTP_PORT = 8000
const server = http.createServer((req, res) => {
res.end('Hello World')
})
server.listen(8000, () => {
console.log(`🚀服务器在${HTTP_PORT}启动~`)
})1、创建服务器
创建服务器对象,我们是通过 createServer() 来完成的
http.createServer会返回服务器的对象;- 底层其实使用直接 new Server 对象。
function createServer(opts, requestListener) {
return new Server(opts, requestListener)
}那么,当然,我们也可以自己来创建这个对象:
const server2 = new http.Server((req, res) => {
res.end('Hello Server2')
})
server2.listen(9000, () => {
console.log('服务器启动成功~')
})上面我们已经看到,创建 Server 时会传入一个回调函数,这个回调函数在被调用时会传入两个参数:
- req:request 请求对象,包含请求相关的信息;
- res:response 响应对象,包含我们要发送给客户端的信息;
2、启动一个 HTTP 服务器并监听指定的端口
Server 通过 listen 方法来开启服务器,并且在某一个主机和端口上监听网络请求:
- 也就是当我们通过
ip:port的方式发送到我们监听的 Web 服务器上时; - 我们就可以对其进行相关的处理;
listen函数有三个参数:
- 端口 port: 可以不传, 系统会默认分配端, 后续项目中我们会写入到环境变量中;
- 主机 host: 通常可以传入 localhost、ip 地址 127.0.0.1、或者 ip 地址 0.0.0.0,默认是 0.0.0.0;
- localhost:本质上是一个域名,通常情况下会被解析成 127.0.0.1;
- 127.0.0.1:回环地址(Loop Back Address),表达的意思其实是我们主机自己发出去的包,直接被自己接收;
- 正常的数据库包经常 应用层 - 传输层 - 网络层 - 数据链路层 - 物理层 ;
- 而回环地址,是在网络层直接就被获取到了,是不会经常数据链路层和物理层的;
- 比如我们监听
127.0.0.1时,在同一个网段下的主机中,通过 ip 地址是不能访问的;
- 0.0.0.0:
- 监听 IPV4 上所有的地址,再根据端口找到不同的应用程序;
- 比如我们监听
0.0.0.0时,在同一个网段下的主机中,通过 ip 地址是可以访问的;
- 回调函数:服务器启动成功时的回调函数;
server.listen(() => {
console.log('服务器启动~🚀')
})request
注意: request 继承了IncomingMessage,Readable和EventEmitter
在向服务器发送请求时,我们会携带很多信息,比如:
- 本次请求的 URL,服务器需要根据不同的 URL 进行不同的处理;
- 本次请求的请求方式,比如 GET、POST 请求传入的参数和处理的方式是不同的;
- 本次请求的 headers 中也会携带一些信息,比如客户端信息、接受数据的格式、支持的编码格式等;
- 等等...
这些信息,Node 会帮助我们封装到一个 request 的对象中,我们可以直接来处理这个 request 对象:
const server = http.createServer((req, res) => {
// request对象
console.log(req.url)
console.log(req.method)
console.log(req.headers)
res.end('Hello World')
})url
http 请求参数方式:
- 查询字符串(query string):如
https://example.com/path?key1=value1&key2=value2 - 请求体(body):
- 表单提交:
Content-Type: application/x-www-form-urlencoded - json 提交:
Content-Type: application/json
- 表单提交:
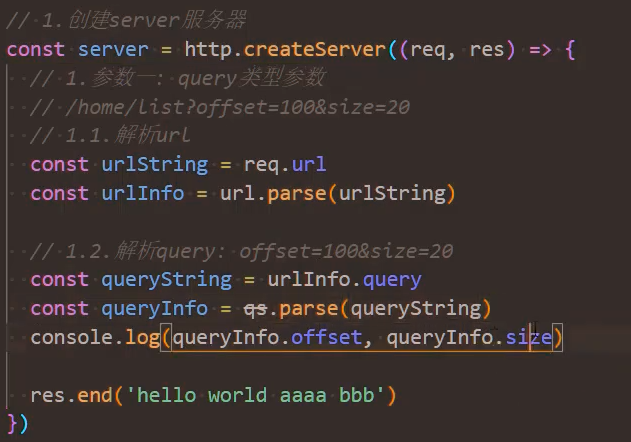
解析-query string
1、解析 url
服务器通过req.url获取请求的 url
客户端在发送请求时,会请求不同的数据,那么会传入不同的请求地址:
- 比如
http://localhost:8000/login; - 比如
http://localhost:8000/products;
服务器端需要根据不同的请求地址,作出不同的响应:
const server = http.createServer((req, res) => {
+ const url = req.url
console.log(url)
if (url === '/login') {
res.end('welcome Back~')
} else if (url === '/products') {
res.end('products')
} else {
res.end('error message')
}
})那么如果用户发送的地址中还携带一些额外的参数呢?
http://localhost:8000/login?name=why&password=123;- 这个时候,url 的值是
/login?name=why&password=123;
我们如何对它进行解析呢?使用内置模块 url;
- url.parse():
const url = require('url')
// 解析请求
const parseInfo = url.parse(req.url)
console.log(parseInfo)解析结果:
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: '?name=why&password=123',
query: 'name=why&password=123',
pathname: '/login',
path: '/login?name=why&password=123',
href: '/login?name=why&password=123'
}2、解析 query
我们会发现 pathname就是我们想要的结果。
但是 query 信息如何可以获取呢?
- 方式一:截取字符串;
- 方式二:使用 querystring 内置模块;
const { pathname, query } = url.parse(req.url)
const queryObj = qs.parse(query)
console.log(queryObj.name)
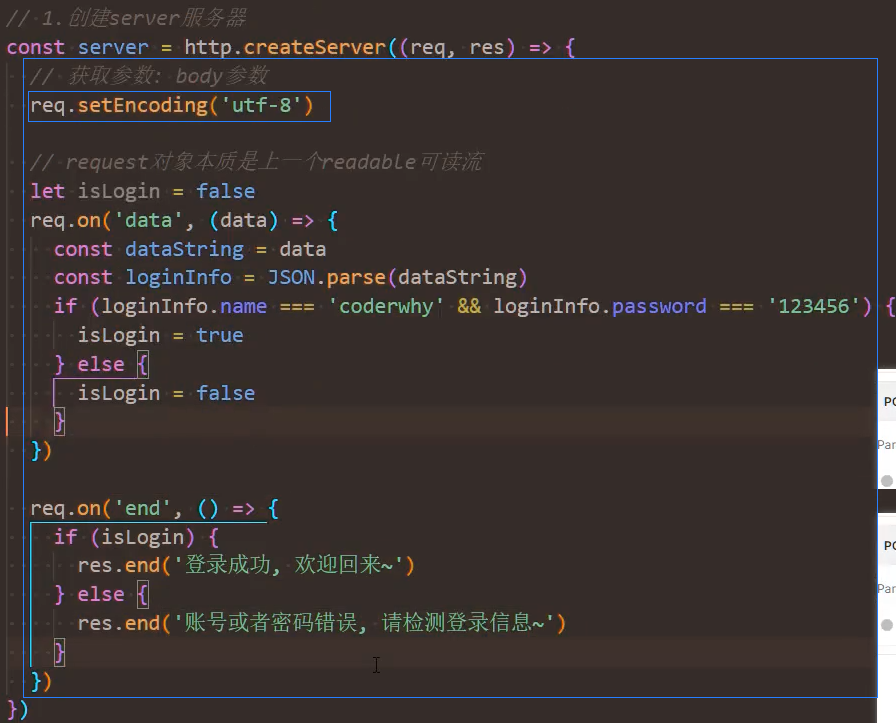
console.log(queryObj.password)解析-body
method
请求方式:
在 Restful 规范(设计风格)中,我们对于数据的增删改查应该通过不同的请求方式:
- GET:查询数据
- POST:新建数据
- PATCH:更新数据
- DELETE:删除数据
- PUT:
所以,我们可以通过判断不同的请求方式进行不同的处理。
比如创建一个用户:
- 请求接口为
/users; - 请求方式为
POST请求; - 携带数据
username和password;
创建用户请求
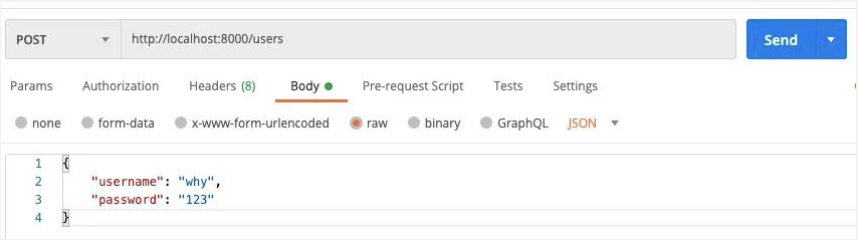
在我们程序中如何进行判断以及获取对应的数据呢?
- 这里我们需要判断接口是
/users,并且请求方式是 POST 方法去获取传入的数据; - 获取这种 body 携带的数据,我们需要通过监听 req 的
data事件来获取;
if (req.url.indexOf('/users') !== -1) {
if (req.method === 'POST') {
// 可以设置编码,也可以在下方通过 data.toString() 获取字符串格式
req.setEncoding('utf-8')
req.on('data', (data) => {
const { username, password } = JSON.parse(data)
console.log(username, password)
})
res.end('create user success')
} else {
res.end('users list')
}
} else {
res.end('error message')
}将 JSON 字符串格式转成对象类型,通过JSON.parse方法即可。
headers
常见 headers:
- content-type:``,这次请求携带的数据的类型
- application/json:``,json 类型
- application/x-www-form-urlencoded:``,表单类型
- text/plain:``,文本类型
- application/xml:``,xml 类型
- multipart/form-data:``,上传文件
- content-length:``,文件的大小和长度
- connection: 'keep-alive':``,保持连接,默认 5s
- accept:
,客户端可接受文件的格式类型,默认*/* - accept-encoding:
,客户端支持的文件压缩格式,默认gzip, deflate, br - user-agent:``,客户端相关的信息
- authorization:``,自定义 token
在 request 对象的 header 中也包含很多有用的信息:
const server = http.createServer((req, res) => {
console.log(req.headers)
res.end('Hello Header')
})浏览器会默认传递过来一些信息:
{
"content-type": "application/json",
"user-agent": "PostmanRuntime/7.26.5",
"accept": "*/*",
"postman-token": "afe4b8fe-67e3-49cc-bd6f-f61c95c4367b",
"host": "localhost:8000",
"accept-encoding": "gzip, deflate, br",
"connection": "keep-alive",
"content-length": "48"
}response
注意: response 继承了IncomingMessage,Writable和EventEmitter
响应结果
如果我们希望给客户端响应的结果数据,可以通过两种方式:
- response.end():写出数据,并关闭流
- response.write():写出数据,不关闭流
const http = require('http')
const server = http.createServer((req, res) => {
// 响应数据的方式有两个:
res.write('Hello World')
res.write('Hello Response')
res.end('message end')
})
server.listen(8000, () => {
console.log('服务器启动🚀~')
})如果我们没有调用 end和close,客户端将会一直等待结果,所以客户端在发送网络请求时,都会设置超时时间。
响应状态码
设置状态码
- response.statusCode:``,设置 HTTP 状态码
- response.writeHead():``,设置 HTTP 状态码
常见状态码
- 200:
OK,客户端请求成功 - 201:
Created,POST 请求,创建新的资源 - 301:
Moved Permanently,请求资源的 URL 已永久更改。在响应中给出了新的 URL。 - 400:
Bad Request,客户端错误,服务器无法或不会处理请求 - 401:
Unauthorized,未授权的错误,必须携带请求的身份信息 - 403:
Forbidden,客户端没有权限访问,被拒接 - 404:
Not Found,服务器找不到请求的资源 - 500:
Internal Server Error,服务器遇到了不知道如何处理的情况 - 503:
Bad Gateway,服务器不可用,可能处理维护或者重载状态,暂时无法访问
响应 Header
设置响应 Header
- res.setHeader():单独设置某个 Header
- res.writeHead():和状态码一起设置
res.setHeader('Content-Type', 'application/json;charset=utf8')
res.writeHead(200, {
'Content-Type': 'application/json;charset=utf8'
})Content-Type 作用:
Header 设置 Content-Type有什么作用呢?
- 默认客户端接收到的是字符串,客户端会按照自己默认的方式进行处理;
比如,我们返回的是一段 HTML,但是没有指定格式:
res.end('<h2>Hello World</h2>')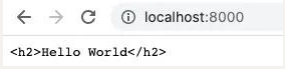
但是,如果我们指定了格式:
res.setHeader('Content-Type', 'text/html;charset=utf8')
res.end('<h2>Hello World</h2>')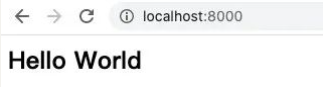
如果我们希望返回一段 JSON 数据,应该怎么做呢?
res.writeHead(200, {
'Content-Type': 'application/json;charset=utf8'
})
const data = {
name: '王红元',
age: 18,
height: 1.88
}
res.end(JSON.stringify(data))网络请求
axios 实现原理
axios 库可以在浏览器中使用,也可以在 Node 中使用
- 浏览器:通过封装 XHR 和 fetch 实现的网络请求
- Node:通过封装 http 模块实现的网络请求
http.get()
发送 get 请求:
http.get('http://localhost:8000', (res) => {
res.on('data', (data) => {
console.log(data.toString())
console.log(JSON.parse(data.toString()))
})
})http.request()
发送 post 请求:
注意: 必须调用req.end(),表示写入内容完成
const req = http.request(
{
method: 'POST',
hostname: 'localhost',
port: 8000
},
(res) => {
res.on('data', (data) => {
console.log(data.toString())
console.log(JSON.parse(data.toString()))
})
}
)
req.on('error', (err) => {
console.log(err)
}) + req.end()文件上传
上传图片
注意:
- 文件上传必须是 POST 请求
- 文件上传 body 格式必须是 multipart/form-data
postman 上传
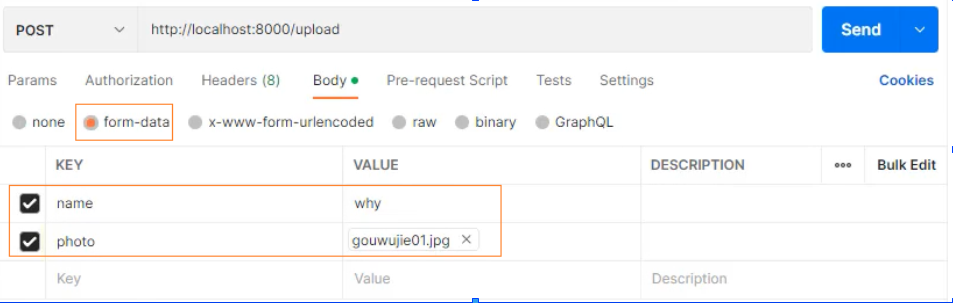
浏览器上传
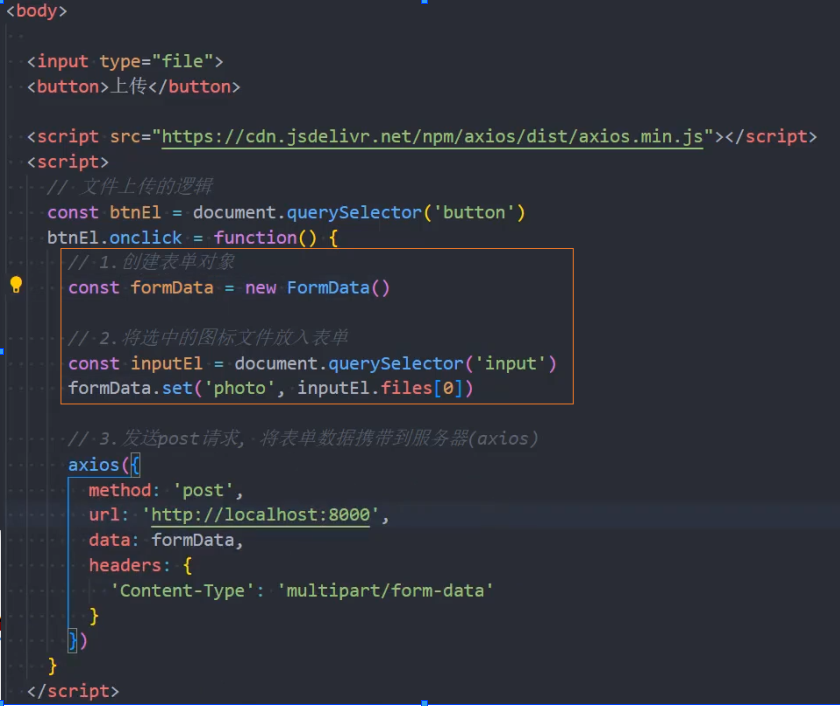
接收图片
错误的做法
如果是一个很大的文件需要上传到服务器端,服务器端进行保存应该如何操作呢?
const server = http.createServer((req, res) => {
if (req.url === '/upload') {
if (req.method === 'POST') {
const fileWriter = fs.createWriteStream('./foo.png')
req.pipe(fileWriter)
const fileSize = req.headers['content-length']
let curSize = 0
console.log(fileSize)
req.on('data', (data) => {
curSize += data.length
console.log(curSize)
res.write(`文件上传进度: ${(curSize / fileSize) * 100}%\n`)
})
req.on('end', () => {
res.end('文件上传完成~')
})
}
} else {
res.end('error message')
}
})正确的做法
这个时候我们发现文件上传成功了,但是文件却打不开:
- 这是因为我们写入的数据,里面包含一些特殊的信息;
- 这些信息打开的软件并不能很好的解析;
const server = http.createServer((req, res) => {
if (req.url === '/upload') {
if (req.method === 'POST') {
// 图片文件必须设置为二进制的
req.setEncoding('binary')
// 获取content-type中的boundary的值
var boundary = req.headers['content-type'].split('; ')[1].replace('boundary=', '')
// 记录当前数据的信息
const fileSize = req.headers['content-length']
let curSize = 0
let body = ''
// 监听当前的数据
req.on('data', (data) => {
curSize += data.length
res.write(`文件上传进度: ${(curSize / fileSize) * 100}%\n`)
body += data
})
// 数据结构
req.on('end', () => {
// 切割数据
const payload = qs.parse(body, '\r\n', ':')
// 获取最后的类型(image/png)
const fileType = payload['Content-Type'].substring(1)
// 获取要截取的长度
const fileTypePosition = body.indexOf(fileType) + fileType.length
let binaryData = body.substring(fileTypePosition)
binaryData = binaryData.replace(/^\s\s*/, '')
// binaryData = binaryData.replaceAll('\r\n', '');
const finalData = binaryData.substring(0, binaryData.indexOf('--' + boundary + '--'))
fs.writeFile('./boo.png', finalData, 'binary', (err) => {
console.log(err)
res.end('文件上传完成~')
})
})
}
} else {
res.end('error message')
}
})API
http
http.createServer()【
http.get()【
http.request()【
http.Server
server.listen()【
http.ClientRequest
继承-IncomingMessage
request.url【
request.method【
request.headers【
继承-Readable
request.setEncoding()【
继承-EventEmitter
request.on()【
http.ServerResponse
继承-outgoingMessage
继承-Writable
response.write()【
response.end()【
继承-EventEmitter
response.on()【
url
API
URL
- new URL():
( input, base? ),用于创建一个新的 URL 对象,可以用来解析、构建和处理 URL。- input:``,(),表示要创建的 URL 字符串,可以是绝对 URL 或相对 URL。
- base?:``,(),表示基础 URL,用于解析相对 URL。如果省略该参数,则将相对 URL 视为绝对 URL。
- 返回值:
- urlObject:
URL,(),返回一个 URL 对象,该对象包含以下属性:href:完整的原始 URL。protocol:URL 的协议部分,末尾包含冒号。slashes:如果协议后面跟着两个斜杠(//),则为true。host:完整的主机名,包括端口号(如果有)。auth:URL 中的认证信息,通常是用户名和密码。hostname:主机名,不包括端口号。port:端口号(如果有)。pathname:URL 的路径部分。search:查询字符串部分,以问号开头。path:路径和查询字符串的组合。query:查询字符串,未解析的字符串或解析后的对象(取决于parseQueryString参数)。hash:片段标识符部分,以井号开头。
URLSearchParams
- new URLSearchParams():
( | string | object | iterable ),用于处理 URL 查询字符串的实用工具。无参数:,(),创建一个空的URLSearchParams实例。string:,(),传入一个查询字符串来初始化。如果字符串以?开头,?会被忽略。object:``,(),传入一个简单的键值对对象。每个键值对会被加入到查询字符串中。iterable:``,(),传入一个可迭代对象,如二维数组。每个子数组都应包含两个元素:键和值。- 返回值:
- params:
URLSearchParams,(),返回一个URLSearchParams实例对象
- :``,
综合
- fileURLToPath():
( url ),用于将 file 协议的 URL 转换为对应的文件系统路径。- url:
,(),一个表示文件 URL 的字符串或者是一个URL对象。如:file:///C:/path/to/file.txt - 返回值: 返回一个字符串,表示转换后的文件系统路径。如:
C:\path\to\file.txt
- url:
- url.parse():
(urlString, parseQueryString?, slashesDenoteHost?),(废弃),用于解析 URL 字符串,并返回一个包含各个组成部分的 URL 对象。- urlString:
string,要被解析的 URL 字符串。 - parseQueryString?:
true |false,true:(),query属性会被解析并转换成一个对象。false:(默认),query属性会保持为一个未解析的字符串。
- slashesDenoteHost?:
true |false,true:(),第一个双斜杠之后直到下一个斜杠之前的字符串会被解析为hostfalse:(默认),
- 返回值:
- urlObject:
URL,(),返回一个 URL 对象,该对象包含以下属性:href:完整的原始 URL。protocol:URL 的协议部分,末尾包含冒号。slashes:如果协议后面跟着两个斜杠(//),则为true。host:完整的主机名,包括端口号(如果有)。auth:URL 中的认证信息,通常是用户名和密码。hostname:主机名,不包括端口号。port:端口号(如果有)。pathname:URL 的路径部分。search:查询字符串部分,以问号开头。path:路径和查询字符串的组合。query:查询字符串,未解析的字符串或解析后的对象(取决于parseQueryString参数)。hash:片段标识符部分,以井号开头。
- urlString:
- :``,
URL
new URL()
new URL():( input, base? ),用于创建一个新的 URL 对象,可以用来解析、构建和处理 URL。
- input:``,(),表示要创建的 URL 字符串,可以是绝对 URL 或相对 URL。
- base?:``,(),表示基础 URL,用于解析相对 URL。如果省略该参数,则将相对 URL 视为绝对 URL。
- 返回值:
- urlObject:
URL,(),返回一个 URL 对象,该对象包含以下属性:href:完整的原始 URL。protocol:URL 的协议部分,末尾包含冒号。slashes:如果协议后面跟着两个斜杠(//),则为true。host:完整的主机名,包括端口号(如果有)。auth:URL 中的认证信息,通常是用户名和密码。hostname:主机名,不包括端口号。port:端口号(如果有)。pathname:URL 的路径部分。search:查询字符串部分,以问号开头。path:路径和查询字符串的组合。query:查询字符串,未解析的字符串或解析后的对象(取决于parseQueryString参数)。hash:片段标识符部分,以井号开头。
URLSearchParams
new URLSearchParams()
new URLSearchParams():( | string | object | iterable ),用于处理 URL 查询字符串的实用工具。
无参数:,(),创建一个空的URLSearchParams实例。string:,(),传入一个查询字符串来初始化。如果字符串以?开头,?会被忽略。object:``,(),传入一个简单的键值对对象。每个键值对会被加入到查询字符串中。iterable:``,(),传入一个可迭代对象,如二维数组。每个子数组都应包含两个元素:键和值。- 返回值:
- params:
URLSearchParams,(),返回一个URLSearchParams实例对象
综合
url.parse()
url.parse():(urlString, parseQueryString?, slashesDenoteHost?),(废弃),用于解析 URL 字符串,并返回一个包含各个组成部分的 URL 对象。
- urlString:
string,要被解析的 URL 字符串。 - parseQueryString?:
true |false,true:(),query属性会被解析并转换成一个对象。false:(默认),query属性会保持为一个未解析的字符串。
- slashesDenoteHost?:
true |false,true:(),第一个双斜杠之后直到下一个斜杠之前的字符串会被解析为hostfalse:(默认),
- 返回值:
- urlObject:
URL,(),返回一个 URL 对象,该对象包含以下属性:href:完整的原始 URL。protocol:URL 的协议部分,末尾包含冒号。slashes:如果协议后面跟着两个斜杠(//),则为true。host:完整的主机名,包括端口号(如果有)。auth:URL 中的认证信息,通常是用户名和密码。hostname:主机名,不包括端口号。port:端口号(如果有)。pathname:URL 的路径部分。search:查询字符串部分,以问号开头。path:路径和查询字符串的组合。query:查询字符串,未解析的字符串或解析后的对象(取决于parseQueryString参数)。hash:片段标识符部分,以井号开头。
fileURLToPath()
fileURLToPath():( url ),用于将 file 协议的 URL 转换为对应的文件系统路径。
- url:
,(),一个表示文件 URL 的字符串或者是一个URL对象。如:file:///C:/path/to/file.txt - 返回值: 返回一个字符串,表示转换后的文件系统路径。如:
C:\path\to\file.txt
querystring
API
qs.parse()【
process
API
process.argv:
,提供命令行参数数组。返回:
args:
string[],包含命令行参数的数组。第一个元素是node的可执行路径,第二个元素是脚本文件的路径,从第三个元素开始是用户传入的参数。- js
// node example.js arg1 arg2 console.log(process.argv); // Output: [ '/path/to/node', '/path/to/example.js', 'arg1', 'arg2' ]
process.env:
,获取或设置环境变量。返回:
env:
object,一个包含所有环境变量的对象。你可以通过该对象访问或修改环境变量。- js
console.log(process.env.PATH); // 获取 PATH 环境变量 process.env.NEW_VAR = 'some value'; // 设置环境变量
process.on():
(event, listener),用于注册事件监听器,以响应 Node.js 进程中的各种事件。event:
string,指定要监听的事件类型,例如'exit'、'uncaughtException'、'SIGINT'等。- 事件类型:
exit:('exit', (code) => void),进程即将退出时触发。beforeExit:('exit', (code) => void),进程退出前触发。uncaughtException:('exit', (err) => void),未捕获的异常发生时触发。SIGINT:('exit', () => void),收到中断信号(通常是 Ctrl+C)时触发。可以用于在进程终止前执行清理操作。SIGTERM:('exit', () => void),收到终止信号时触发。通常用于进程终止时的清理操作。warning:('exit', (warning) => void),发出警告时触发
listener:
(args?) => void,当指定事件发生时执行的回调函数。- args?:``,参数取决于事件类型。
- js
process.on('exit', (code) => { console.log(`Process exiting with code: ${code}`); });
process.cwd():
(),用于获取当前工作目录的绝对路径。通常用于构造相对于当前工作目录的文件路径。返回:
currentWorkingDirectory:
string,返回当前工作目录的绝对路径。注意: 返回的是 Node.js 进程的当前工作目录,而不是脚本文件所在的目录。
- js
// 构造相对于当前工作目录的文件路径 const filePath = path.join(process.cwd(), 'data', 'config.json');
process.platform:
,用于获取当前操作系统的平台标识符。返回:
platform:
string,表示操作系统的标识符- 标识符:
win32:Windowslinux:Linuxdarwin:macOS- ...
- js
switch (process.platform) { case 'win32': console.log('Running on Windows'); break; case 'darwin': console.log('Running on macOS'); break; case 'linux': console.log('Running on Linux'); break; default: console.log('Running on an unknown platform'); }
process.stdout:
,【TODO】- :``,
- :``,
- 返回:
- :``,
process.stdin:
,【TODO】- :``,
- :``,
- 返回:
- :``,
child_process
API
- spawn():
(cmd, args?, options?),【TODO】- :``,
- :``,
- :``,
- 返回:
- :``,
- exec():
(cmd, opitons?, callback?),【TODO】- :``,
- :``,
- :``,
- 返回:
- :``,
- :
(),- :``,
- :``,
- 返回:
- :``,
util
API
promisify():
(originalFunction),用于将遵循回调模式的异步函数转换为返回Promise的函数。originalFunction:
function,需要被转换为返回Promise的函数。这个函数必须遵循回调模式。返回:
fn:
(args?) => Promise,回一个新的函数,这个函数返回一个Promise。- js
const { promisify } = require('util'); const fs = require('fs'); // 将 fs.readFile 转换为返回 Promise 的函数 const readFileAsync = promisify(fs.readFile); readFileAsync('example.txt', 'utf8') .then(data => { console.log(data); }) .catch(err => { console.error('Error:', err); });
glob
概述
glob: 是一个用于文件路径匹配的 Node.js 库,其主要 API 用于查找与指定模式匹配的文件。
安装: glob不是node内置的库,需要另外安装
pnpm i globglob VS require.context():
glob: 适用于任何Node.js环境,是一个用于匹配文件路径模式的库,通常在构建时使用,比如在Node.js环境下进行文件查找;require.context(): 是Webpack特有的功能,用于动态导入模块,适用于在Webpack打包时提供更直接的模块导入方式。
API
glob():
(pattern, options?, callback),(异步),查找与指定模式匹配的文件pattern:
string | reg,需要匹配的路径模式(字符串),可以包含通配符。options?:
{cwd,ignore,nodir,matchBase,realpath,followSymlinks},配置匹配行为。可以是对象或布尔值(true表示默认设置)。- cwd: 工作目录,默认为当前目录。
- ignore: 要忽略的模式数组。
- nodir: 如果设置为
true,不返回目录。 - matchBase: 仅根据文件名进行匹配。
- realpath: 如果设置为
true,返回绝对路径。 - followSymlinks: 是否跟随符号链接。
callback:
(err, files) => void,回调函数。- err:
Error,错误信息 - files:
string[],匹配到的文件路径数组。
- err:
- js
const glob = require('glob'); glob('src/**/*.js', { ignore: 'node_modules/**' }, (err, files) => { if (err) throw err; console.log(files); });
glob.sync():
(pattern, options?),(同步),查找与指定模式匹配的文件。pattern:
string | reg,需要匹配的路径模式(字符串),可以包含通配符。options?:
{cwd,ignore,nodir,matchBase,realpath,followSymlinks},配置匹配行为。可以是对象或布尔值(true表示默认设置)。- cwd: 工作目录,默认为当前目录。
- ignore: 要忽略的模式数组。
- nodir: 如果设置为
true,不返回目录。 - matchBase: 仅根据文件名进行匹配。
- realpath: 如果设置为
true,返回绝对路径。 - followSymlinks: 是否跟随符号链接。
返回:
files:
array,默认:,匹配的文件路径数组。- js
const glob = require('glob'); const files = glob.sync('src/**/*.js', { ignore: 'node_modules/**' }); console.log(files);
glob匹配规则
*:匹配任意数量的字符,但不包括/。js*.js**:匹配任意数量的字符,包括/。通常用于匹配目录下的文件。jsscripts/**/*.js?:匹配一个字符,但不包括/。jsscripts/**/*.jsx?!:取反,用于排除不匹配的文件或目录。相当于glob第二个参数options.ignore由于 glob 匹配时是按照每个 glob 在数组中的位置依次进行匹配操作的;
所以 glob 数组中的取反(negative)glob 必须跟在一个非取反(non-negative)的 glob 后面;
第一个 glob 匹配到一组匹配项,然后后面的取反 glob 删除这些匹配项中的一部分;
js// 表示匹配scripts目录下的所有js文件,但排除scripts/vendor/目录下的文件 ['scripts/**/*.js', '!scripts/vendor/']
示例:glob() 匹配src目录下的所有文件(包括子目录中的文件)
const glob = require('glob');
glob('src/**/*', (err, files) => {
if (err) {
console.error(err);
return;
}
console.log(files);
});示例:glob() 匹配src目录下的所有文件(不包括目录)
const glob = require('glob');
glob('src/**/*', { nodir: true }, (err, files) => {
if (err) {
console.error(err);
return;
}
console.log(files);
});示例:glob.sync() 同步匹配所有js文件
const glob = require('glob');
const files = glob.sync('**/*.js');
console.log(files);