S17-01 数据结构与算法
[TOC]
基础
概述
在前面的课程中我不断的强调一个编程的真相:编程的最终目的只有一个:对数据进行操作和处理。
- 评判编程能力、水平的高低,要看你是否可以更好的操作和处理数据。
- 在之前的很多课程中,我经常和同学们强调一个事实:所以的编程(无论是前端、后端、算法、人工智能、区块链,也不论 是什么语言 JavaScript、Java、C++等等)最终的目的都是为了处理数据。
当你拿到这些数据时,以什么样的方式存储和处理会更加方便、高效,也是评判一个开发人员能力的重要指标(甚至是唯一的指标)。
虽然目前很多的系统、框架已经给我们提供了足够多好用的 API,对于大多数时候我们只需要调用这些 API 即可。
但是如何更好的组织数据和代码,以及当数据变得复杂时,以什么方式处理这些数据依然非常重要。
只有可以更好的处理数据,你才是一个真正的开发工程师,而不只是一个 API 调用程序员。
以前端、后端为例:
前端从后端获取数据,对数据进行处理、展示;
和用户进行交互产生新的数据,传递给后端,后端进行处理、保存到数据库,以便后续读取、操作、展示等等;
数据结构与算法的本质:
数据结构与算法的本质就是一门专门研究数据如何组织、存储和操作的科目。
算法+数据结构=程序(Algorithm+Data Structures=Programs)
数据结构与算法事实上是程序的核心,是我们编写的所有程序的灵魂。
只有掌握了扎实的数据结构与算法,我们才能更好的理解编程,编写扎实、高效的程序。
包括对于程序的理解不再停留于表面,甚至在学习其他的系统或者编程语言时,也可以做到高屋建瓴、势如破竹。
应用
无论是操作系统(Windows、Mac OS)本身,还是我们所使用的编程语言(JavaScript、Java、C++、Python 等等),还是 我们在平时应用程序中用到的框架(Vue、React、Spring、Flask 等等),它们的底层实现到处都是数据结构与算法,所以你 要想学习一些底层的知识或者某一个框架的源码(比如 Vue、React 的源码)是必须要掌握数据结构与算法的。
以前端为例:框架中大量使用到了栈结构、队列结构等来解决问题(比如之前看框架源码时经常看到这些数据结构,Vue 源码、 React 源码、Webpack 源码中可以看到队列、栈结构、树结构等等,Webpack 中还可以看到很多 Graph 图结构);
实现语言或者引擎本身也需要大量的数据结构:哈希表结构、队列结构(微任务队列、宏任务队列),前端无处不在的数据 结构:DOM Tree(树结构)、AST(抽象语法树)。
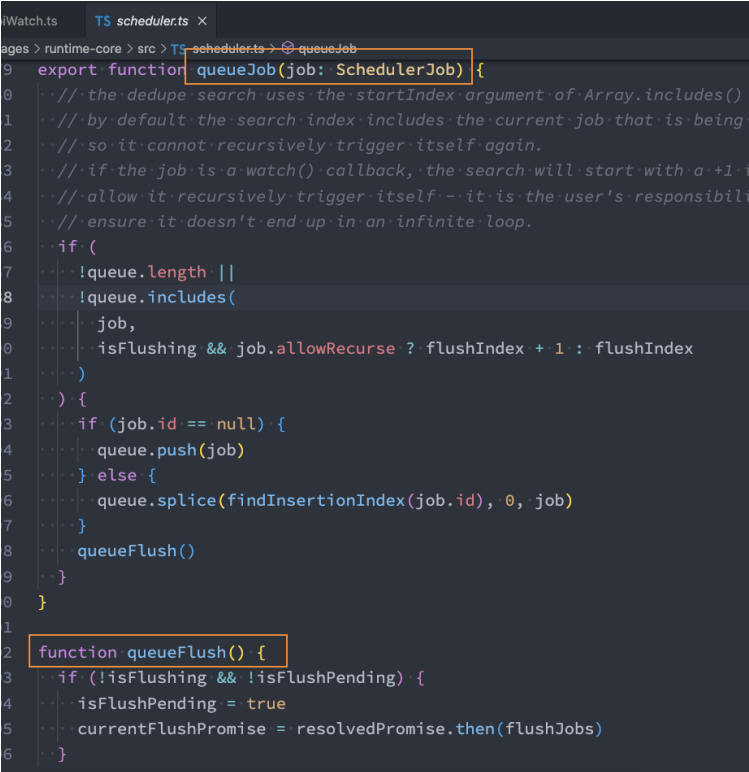
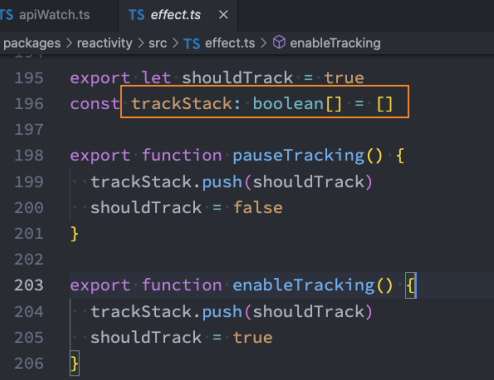
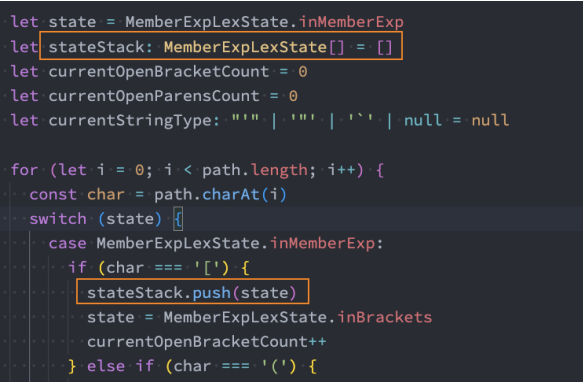
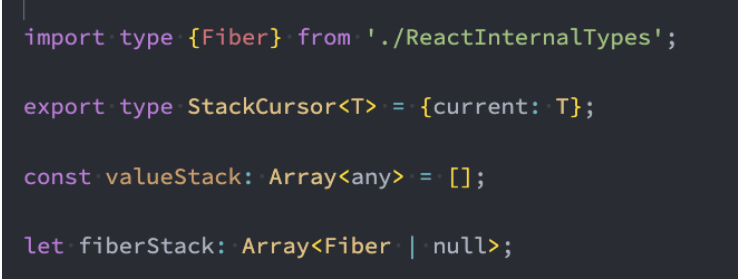
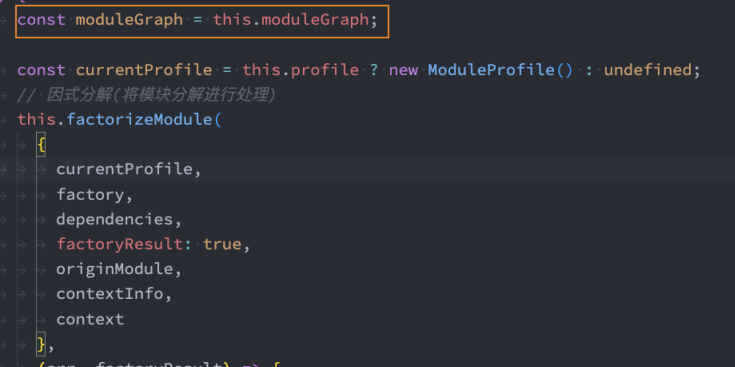
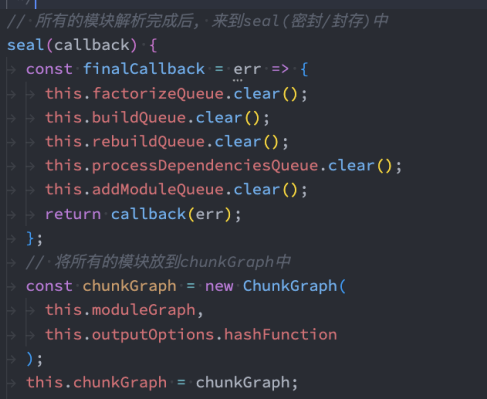
Vue 源码中的数据结构:
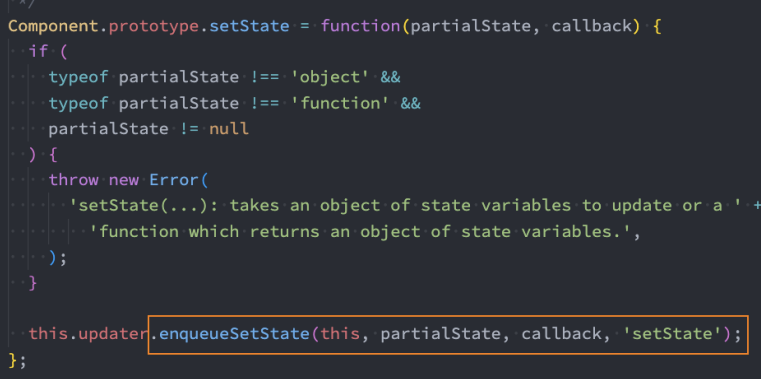
React、Webpack 源码中的数据结构:
面试要求
互联网大厂、高级岗位面试都会要求 必须要掌握一定的数据结构与算法:
因为对于很多企业来说,想要短时间考察一个人的能力以及未来的潜力,数据结构与算法是非常重要指标,也会成为它们的硬性条件。
- 对于可以将数据结构与算法掌握很好的开发人员来说,通常对于业务的把握肯定是没有问题的。
- 并且对于系统的设计也会更加合理,可以写出更加高效的代码。
对于想要进入大厂的同学,经常会刷leetcode:
- 但是对于大多数同学来说,leetcode 上的题目晦涩难懂,代码无从下手,不会解题。
- 只有系统的掌握了数据结构与算法,才能将这些题目融会贯通,面试遇到相关的题目就可以对答如流。
逻辑思维、代码能力提升离不开对于数据的处理:
- 我们已经强调了所有的编程最终的目的都是为了处理数据。
- 而数据结构与算法就是一门专为讲解数据应该如何存储、组织、操作的课程。
- 所以学习数据结构与算法可以更好的锻炼我们的逻辑思维能力和代码编程能力,帮助我们平时在处理一些复杂数据时,可以更好的编 写代码,写出更高效的程序。
并且掌握数据结构与算法后,如果想要转向其他的领域(比如从前端转到后端、算法工程师等)也会更加容易:
- 因为所有的编程思想都是想通的,只是换了一种语言来处理数据而已。
- 对于未来更多的领域,比如人工智能、区块链,数据结构与算法也是它们的基石,是必须要掌握的一门课程。
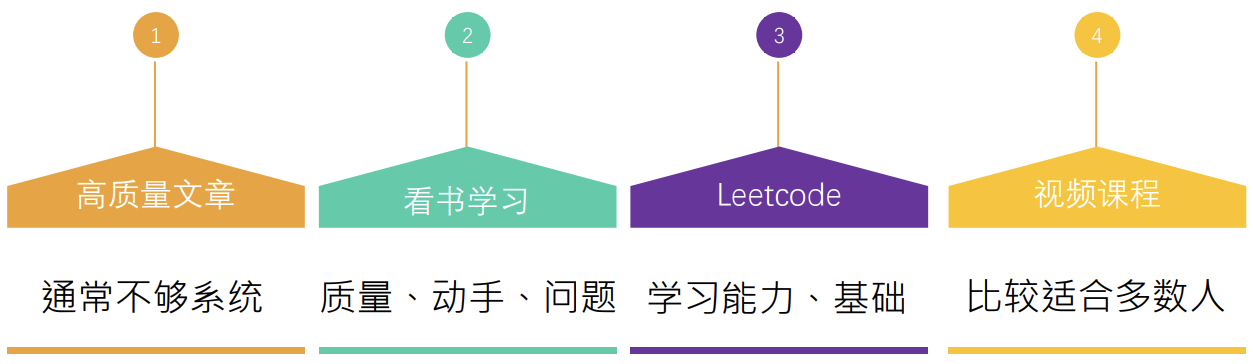
学习方法
数据结构与算法通常被认为 晦涩难懂、复杂抽象,对于大多数人来说学习起来是比较困难的。
那么通常学习数据结构与算法有哪些方式呢?
TS 常见数据结构与算法
数据结构
概念
数据结构(Data Structure): 数据结构是计算机中用于组织和存储数据的方式。它涉及到如何将数据以及相互之间的关系组织起来,以便能够高效地访问和处理数据。常见的数据结构有数组、链表、栈、队列、树、图等。
常见数据结构

在计算机中对于数据的组织和存储结构也会影响我们的效率。
常见的数据结构较多
- 每一种都有其对应的应用场景,不同的数据结构 的 不同操作 性能是不同的。
- 有的查询性能很快,有的插入速度很快,有的是插入头和尾速度很快。
- 有的做范围查找很快,有的允许元素重复,有的不允许重复等等。
- 在开发中如何选择,要根据具体的需求来选择。
注意: 数据结构和语言无关,常见的编程语言都有 直接或者间接 的使用上述常见的数据结构
为什么之前学习 JavaScript 没有接触过数据结构呢? 好像只见过数组。
- 这是因为很多数据结构是需要在进行高阶开发(比如设计框架源码)时才会用到的。
- 甚至某些数据结构在 JavaScript 中本身是没有的,我们需要从零去实现的。
你可能会想:老师,我觉得不多呀,赶紧给我们讲讲怎么用的就行了。
- 我们不是要讲这些数据结构如何用,用是 API 程序员的思考方式,我们要讲的是这些数据结构如何实现,再如何使用。
- 了解真相,你才能获得真正的自由。
算法
算法(Algorithm): 算法是解决问题的一种方法或步骤。常见的算法包括排序算法(如冒泡排序、快速排序、归并排序等)、查找算法(如顺序查找、二分查找等)、图形算法(如最短路径算法、最小生成树算法等)等等。
在之前的学习中,我们可能学习过几种排序算法,并且知道不同的算法,执行效率是不一样的。
解决问题的过程中,不仅仅数据的存储方式会影响效率,算法的优劣也会影响着效率。
数据结构的实现,离不开算法。
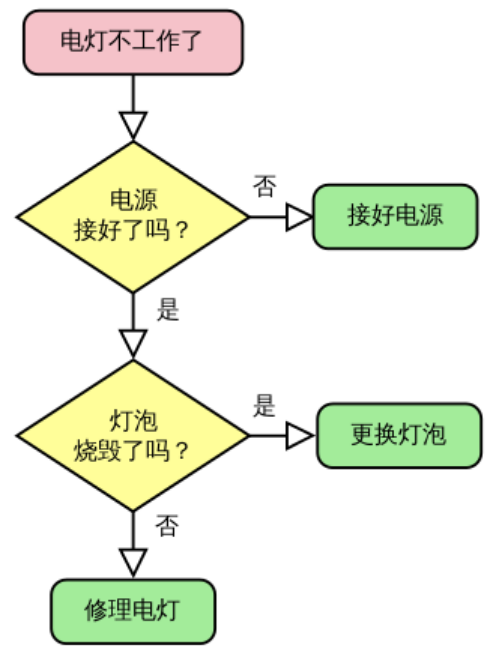
举例: 电灯不工作的解决算法
线性结构
线性结构(Linear List): 由 n(n≥0)个数据元素(节点,a[0],a[1],a[2]…,a[n-1])组成的有限序列。
其中:
- 数据元素的个数 n 定义为表的长度 = “list”.length() (“list”.length() = 0(表里没有一个元素)时称为空表)。
- 将非空的线性表(n>=1)记作:(a[0],a[1],a[2],…,a[n-1])。
- 数据元素 a[i](0≤i≤n-1)只是个抽象符号,其具体含义在不同情况下可以不同。
上面是维基百科对于线性结构的定义,有一点点抽象,其实我们只需要记住几个常见的线性结构即可

数组结构(Array)
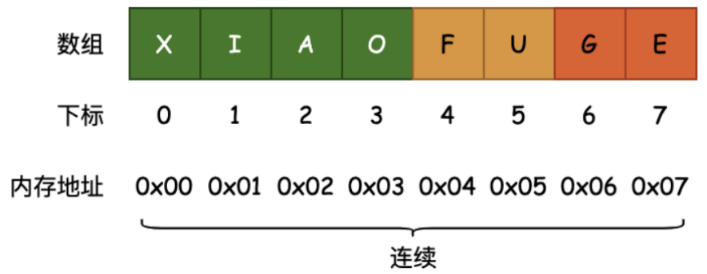
▸ 数组(Array): 是一种线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的索引(index)。
▸ 数组(Array)结构是一种重要的数据结构。几乎是每种编程语言都会提供的一种原生数据结构(语言自带的)。并且我们可以借助于数组结构来实现其他的数据结构,比如栈(Stack)、队列(Queue)、堆(Heap);
▸ 数组的主要概念和存储方式:
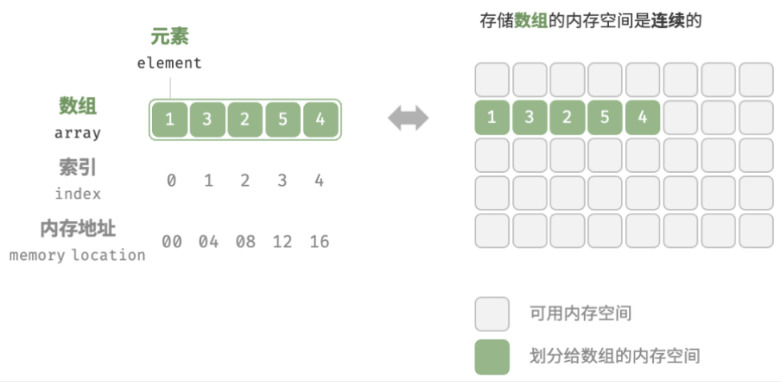
▸ 通常数组的内存是连续的,所以数组在知道下标值的情况下,访问效率是非常高的
这里我们不再详细讲解 TypeScript 中数组的各种用法,和 JavaScript 是一致的
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Array
后续我们在讨论数组和链表的关系区别时,还会通过大 O 表示法来分析数组操作元素的时间复杂度问题。
栈(Stack)
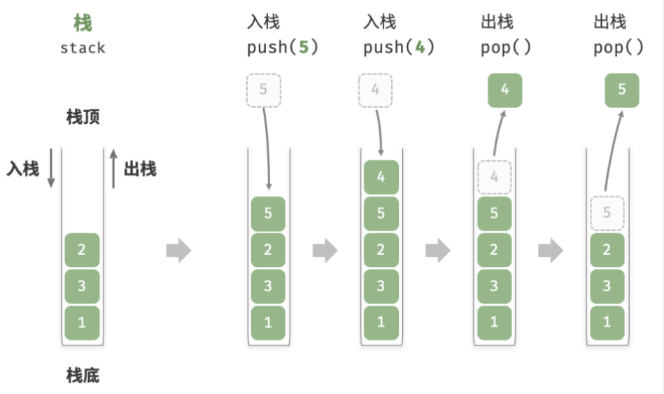
▸ 栈(Stack): 是一种遵循先入后出逻辑的线性数据结构。
我们可以将栈类比为桌面上的一摞盘子,如果想取出底部的盘子,则需要先将上面的盘子依次移走。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈这种数据结构。
▸ 我们把堆叠元素的顶部称为“栈顶”,底部称为“栈底”。将把元素添加到栈顶的操作叫作“入栈”,删除栈顶元素的操作叫作“出栈”。
API
- push(el):
,O(1),添加一个新元素到栈顶位置- el:
any,默认:,栈中的元素
- el:
- pop():
,O(1),移除栈顶的元素,同时返回被移除的元素 - peek():
,O(1),返回栈顶的元素 - isEmpty():
,判断栈是否为空 - size():
,返回栈中元素的个数
▸ 通常情况下,我们可以直接使用编程语言内置的栈类。然而,某些语言可能没有专门提供栈类,这时我们可以将该语言的“数组”或“链表”当作栈来使用,并在程序逻辑上忽略与栈无关的操作。
/* 初始化栈 */
// TypeScript 没有内置的栈类,可以把 Array 当作栈来使用
const stack: number[] = []
/* 元素入栈 */
stack.push(1)
stack.push(3)
stack.push(2)
stack.push(5)
stack.push(4)
/* 访问栈顶元素 */
const peek = stack[stack.length - 1]
/* 元素出栈 */
const pop = stack.pop()
/* 获取栈的长度 */
const size = stack.length
/* 判断是否为空 */
const is_empty = stack.length === 0栈的实现
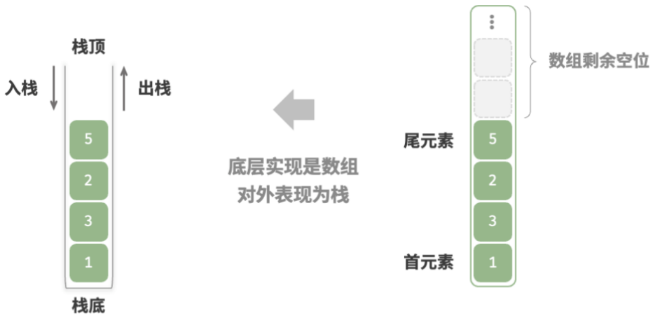
思路: 栈遵循先入后出的原则,因此我们只能在栈顶添加或删除元素。然而,数组和链表都可以在任意位置添加和删除元素,因此栈可以视为一种受限制的数组或链表。换句话说,我们可以“屏蔽”数组或链表的部分无关操作,使其对外表现的逻辑符合栈的特性。
数组实现
思路: 使用数组实现栈时,我们可以将数组的尾部作为栈顶。入栈与出栈操作分别对应在数组尾部添加元素与删除元素,时间复杂度都为 O(1) 。
由于入栈的元素可能会源源不断地增加,因此我们可以使用动态数组,这样就无须自行处理数组扩容问题。
/* 基于数组实现的栈 */
class ArrayStack<T = any> {
// 定义一个数组,用于存储元素。注意:必须是private属性
private stack: T[] = [];
/* 获取栈的长度 */
size(): number {
+ return this.stack.length;
}
/* 判断栈是否为空 */
isEmpty(): boolean {
+ return this.stack.length === 0;
}
/* 入栈 */
push(el: T): void {
+ this.stack.push(el);
}
/* 出栈 */
pop(): T | undefined {
+ if (this.isEmpty()) throw new Error('栈为空');
+ return this.stack.pop();
}
/* 访问栈顶元素 */
peek(): T | undefined {
++ if (this.isEmpty()) throw new Error('栈为空');
return this.stack[this.stack.length - 1];
}
/* 返回 Array */
toArray() {
return this.stack;
}
}
const stack1 = new ArrayStack<string>()
const stack2 = new ArrayStack<number>()测试
链表实现
使用链表实现栈时,我们可以将链表的头节点视为栈顶,尾节点视为栈底。
对于入栈操作,我们只需将元素插入链表头部,这种节点插入方法被称为“头插法”。而对于出栈操作,只需将头节点从链表中删除即可。
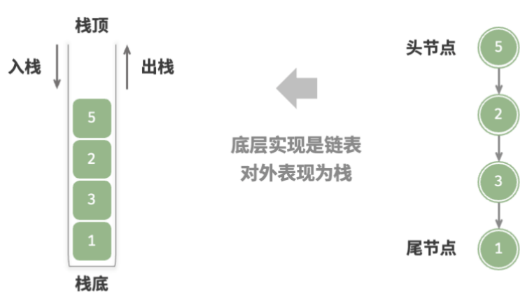
以下是基于链表实现栈的示例代码:
/* 基于链表实现的栈 */
class LinkedListStack {
private stackPeek: ListNode | null; // 将头节点作为栈顶
private stkSize: number = 0; // 栈的长度
constructor() {
this.stackPeek = null;
}
/* 获取栈的长度 */
get size(): number {
return this.stkSize;
}
/* 判断栈是否为空 */
isEmpty(): boolean {
return this.size === 0;
}
/* 入栈 */
push(num: number): void {
const node = new ListNode(num);
node.next = this.stackPeek;
this.stackPeek = node;
this.stkSize++;
}
/* 出栈 */
pop(): number {
const num = this.peek();
if (!this.stackPeek) throw new Error('栈为空');
this.stackPeek = this.stackPeek.next;
this.stkSize--;
return num;
}
/* 访问栈顶元素 */
peek(): number {
if (!this.stackPeek) throw new Error('栈为空');
return this.stackPeek.val;
}
/* 将链表转化为 Array 并返回 */
toArray(): number[] {
let node = this.stackPeek;
const res = new Array<number>(this.size);
for (let i = res.length - 1; i >= 0; i--) {
res[i] = node!.val;
node = node!.next;
}
return res;
}
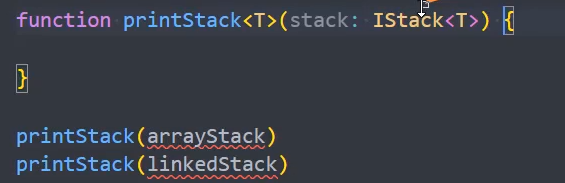
}抽象栈的接口
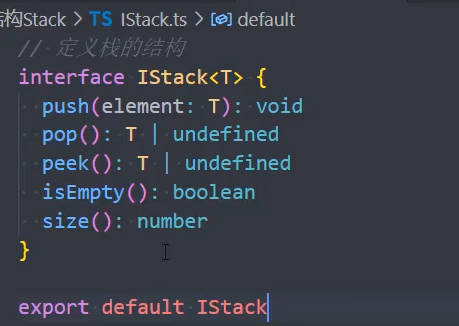
1、定义栈的接口 IStack
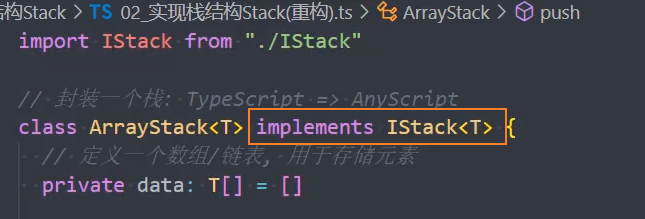
2、ArrayStack 实现栈接口
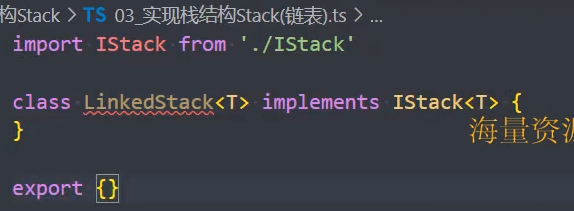
3、LinkedStack 实现栈接口
4、抽象接口是多态的基础
面试题
入栈、出栈顺序


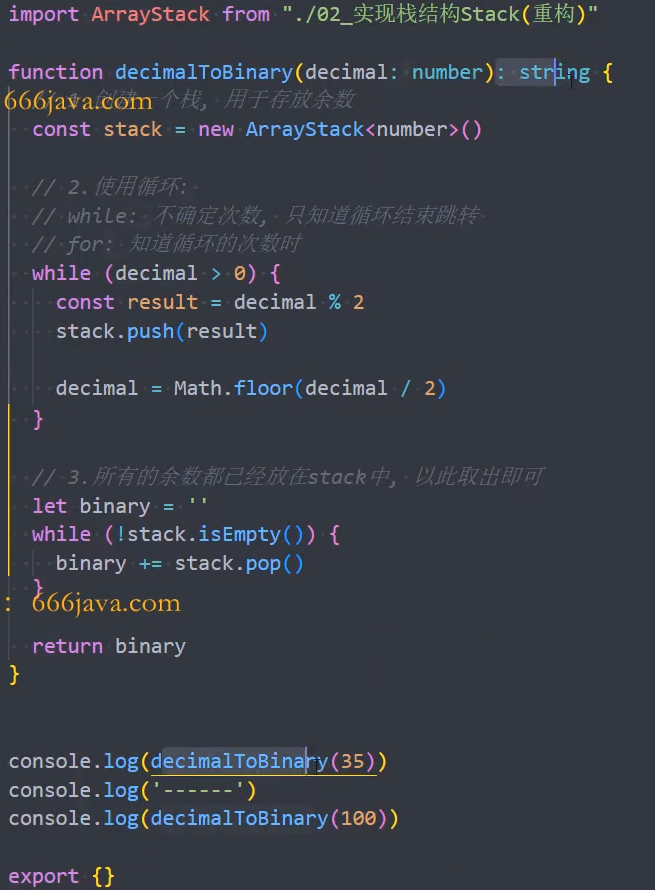
十进制转二进制
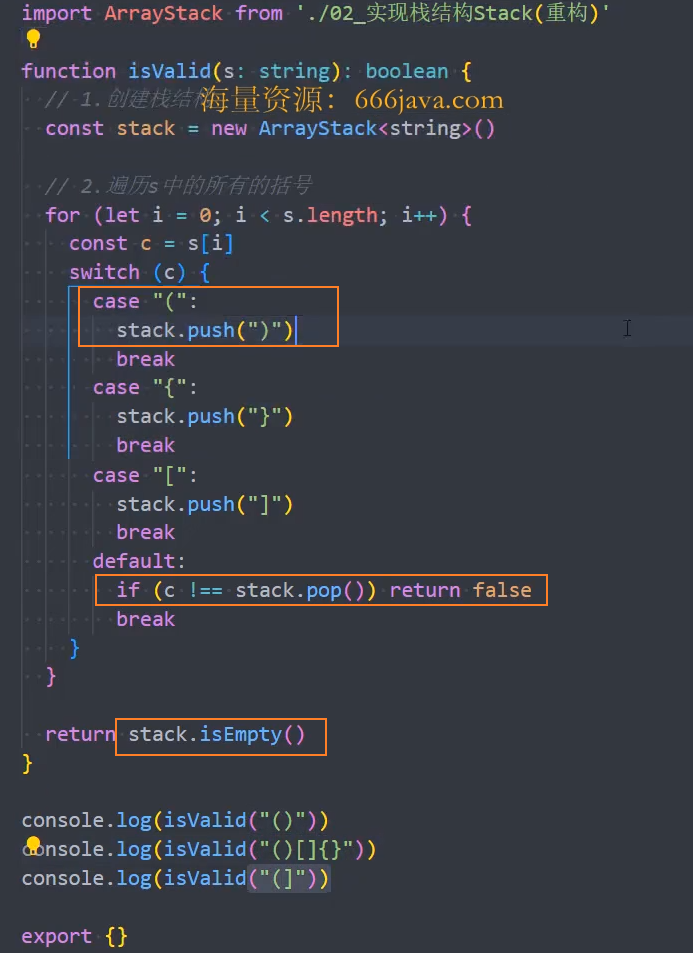
有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true示例 2:
输入:s = "()[]{}"
输出:true示例 3:
输入:s = "(]"
输出:false提示:
1 <= s.length <=10^4s仅由括号'()[]{}'组成
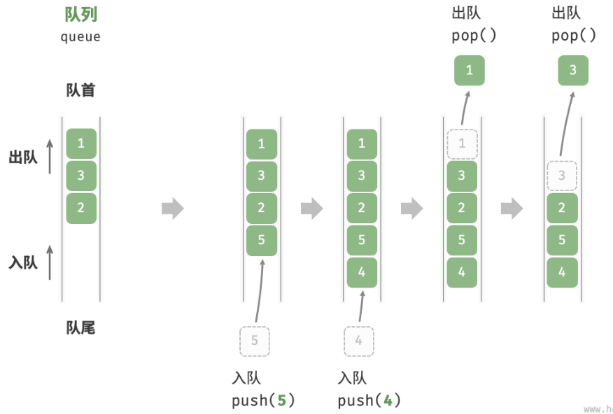
队列(Queue)
队列(queue): 是一种遵循先入先出规则的线性数据结构。顾名思义,队列模拟了排队现象,即新来的人不断加入队列尾部,而位于队列头部的人逐个离开。
队列头部称为“队首”,尾部称为“队尾”,将把元素加入队尾的操作称为“入队”,删除队首元素的操作称为“出队”。
生活中的队列:
生活中类似队列的场景就是非常多了
比如在电影院,商场,甚至是厕所排队。
优先排队的人,优先处理。 (买票,结账,WC)
开发中队列的应用:
打印队列:
有五份文档需要打印,这些文档会按照次序放入到打印队列中。
打印机会依次从队列中取出文档,优先放入的文档,优先被取出,并且对该文档进行打印。
以此类推,直到队列中不再有新的文档。
线程队列:
在开发中,为了让任务可以并行处理,通常会开启多个线程。
但是,我们不能让大量的线程同时运行处理任务。 (占用过多的资源)
这个时候,如果有需要开启线程处理任务的情况,我们就会使用线程队列。
线程队列会依照次序来启动线程,并且处理对应的任务。
当然队列还有很多其他应用,我们后续的很多算法中也会用到队列(比如二叉树的层序遍历)。
队列如何实现呢?
- 我们一起来研究一下队列的实现。
API
- enqueue(el):
,O(1),向队尾添加元素- el:
any,默认:,队列中的元素
- el:
- dequeue():
,O(1),移除队首元素,同时返回被移除的元素 - front()/peek():
,O(1),返回队首元素 - isEmpty():
,判断队列是否为空 - size():
,返回队列中元素的个数
队列的实现
队列的实现和栈一样,有两种方案:
基于数组实现
基于链表实现
我们需要创建自己的类,来表示一个队列
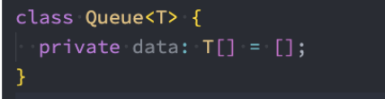
代码解析:
我们创建了一个 Queue 的类,用户创建队列的类,并且是一个泛型类。
在类中,定义了一个变量,这个变量可以用于保存当前队列对象中所有的元素。 (和创建栈非常相似)
这个变量是一个数组类型。
- 我们之后在队列中添加元素或者删除元素,都是在这个数组中完成的。
队列和栈一样,有一些相关的操作方法,通常无论是什么语言,操作都是比较类似的。
数组实现
1、定义抽象
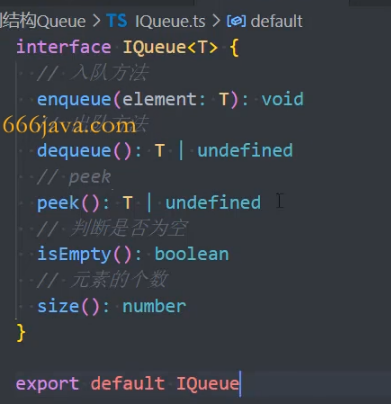
2、实现接口 IQueue
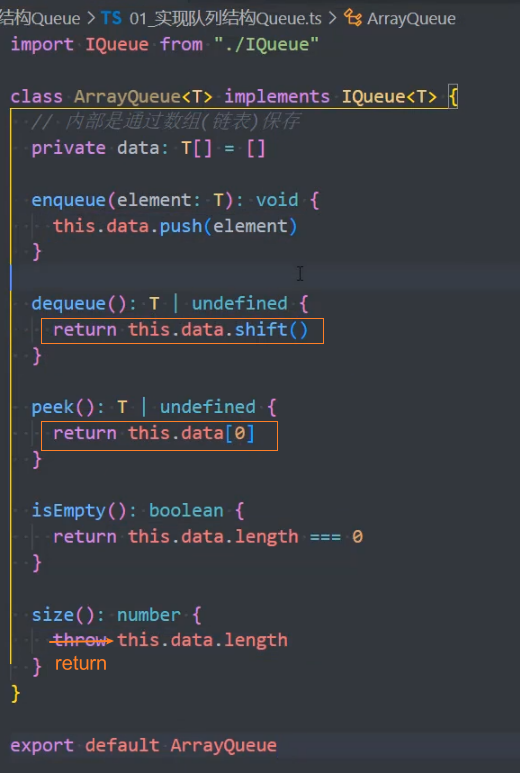
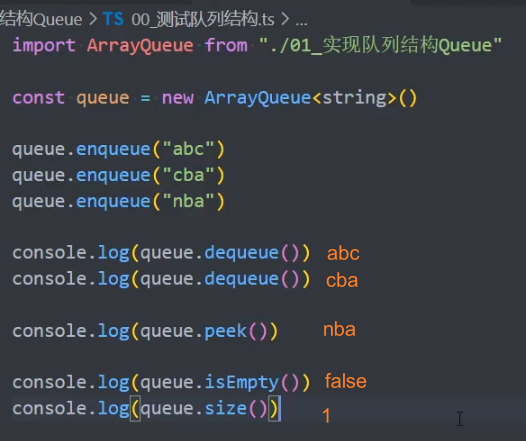
3、测试队列
优化: 使用 get 语法,可以将方法当做属性调用
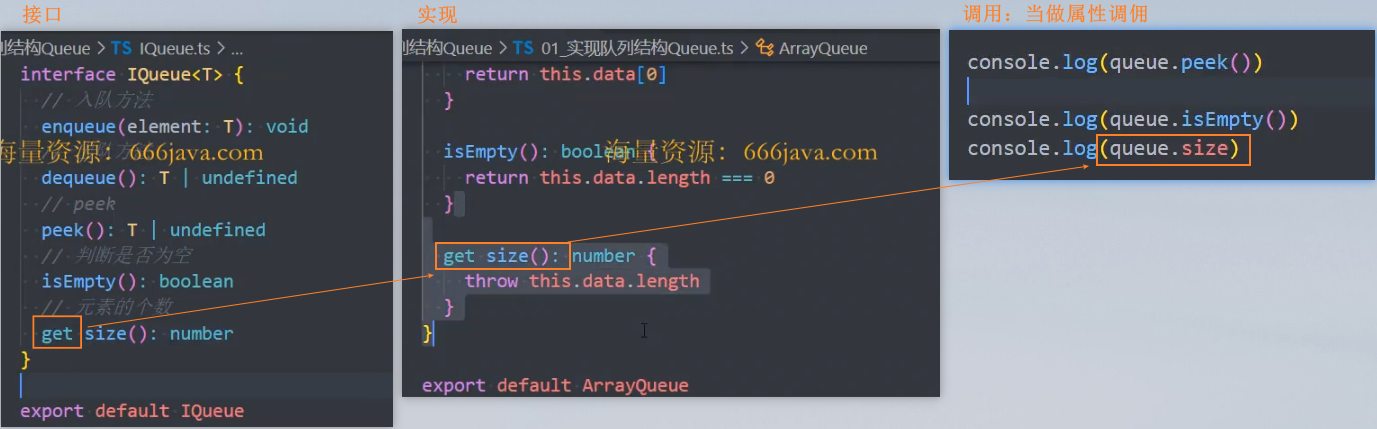
优化: 抽取接口
抽取相同的方法:
peek, isEmpty, size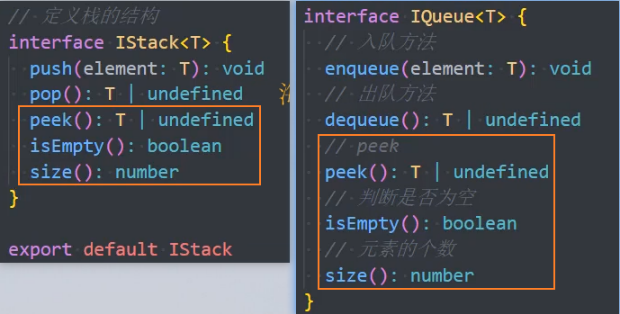
IQueue和IStack继承IList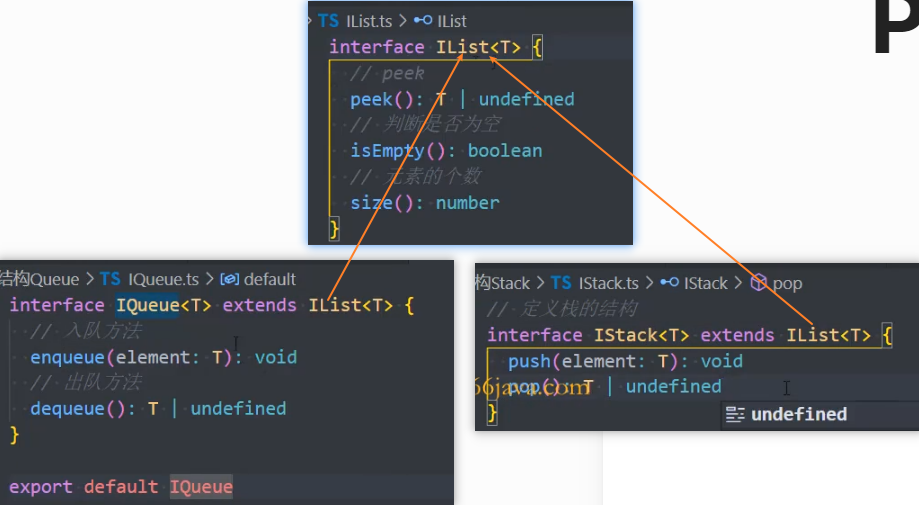
链表实现
面试题
击鼓传花
击鼓传花是一个常见的面试算法题: 使用队列可以非常方便的实现最终的结果。
原游戏规则:
班级中玩一个游戏,所有学生围成一圈,从某位同学手里开始向旁边的同学传一束花。
这个时候某个人(比如班长),在击鼓,鼓声停下的一颗,花落在谁手里,谁就出来表演节目。
修改游戏规则:
我们来修改一下这个游戏规则。
几个朋友一起玩一个游戏,围成一圈,开始数数,数到某个数字的人自动淘汰。
最后剩下的这个人会获得胜利,请问最后剩下的是原来在哪一个位置上的人?
封装一个基于队列的函数:
参数:所有参与人的姓名,基于的数字;
结果:最终剩下的一人的姓名;
击鼓传花的实现
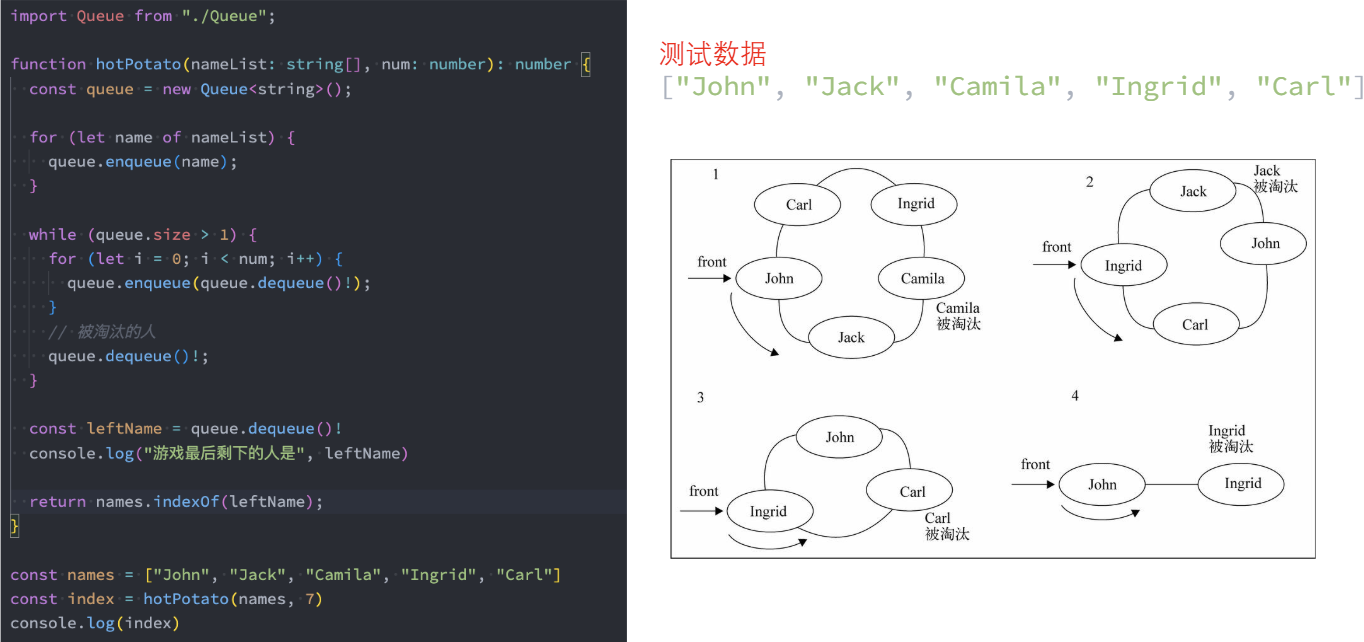
约瑟夫环
什么是约瑟夫环问题(历史)?
阿桥问题(有时也称为约瑟夫斯置换),是一个出现在计算机科学和数学中的问题。在计算机编程的算法中,类似问题又称为约瑟夫环。
人们站在一个等待被处决的圈子里。
计数从圆圈中的指定点开始,并沿指定方向围绕圆圈进行。
在跳过指定数量的人之后,处刑下一个人。
对剩下的人重复该过程,从下一个人开始,朝同一方向跳过相同数量的人,直到只剩下一个人,并被释放。
在给定数量的情况下,站在第几个位置可以避免被处决?
这个问题是弗拉维·奥约瑟夫命名的,他是 1 世纪的一名犹太历史学家。
他在自己的日记中写道,他和他的 40 个战友被罗马军队包围在洞中。
他们讨论是自杀还是被俘,最终决定自杀,并以抽签的方式决定谁杀掉谁。
约瑟夫环问题 – 字节、阿里、谷歌等面试题
击鼓传花和约瑟夫环其实是同一类问题,这种问题还会有其他解法(后续讲解)同样的题目在 Leetcode 上也有:
https://leetcode.cn/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof/
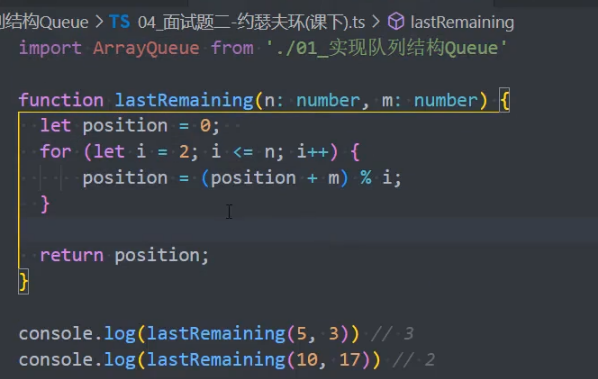
0,1,···,n-1 这 n 个数字排成一个圆圈,从数字 0 开始,每次从这个圆圈里删除第 m 个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4 这 5 个数字组成一个圆圈,从数字 0 开始每次删除第 3 个数字,则删除的前 4 个数字依次是 2、0、4、1,因此最后剩下的数字是 3。
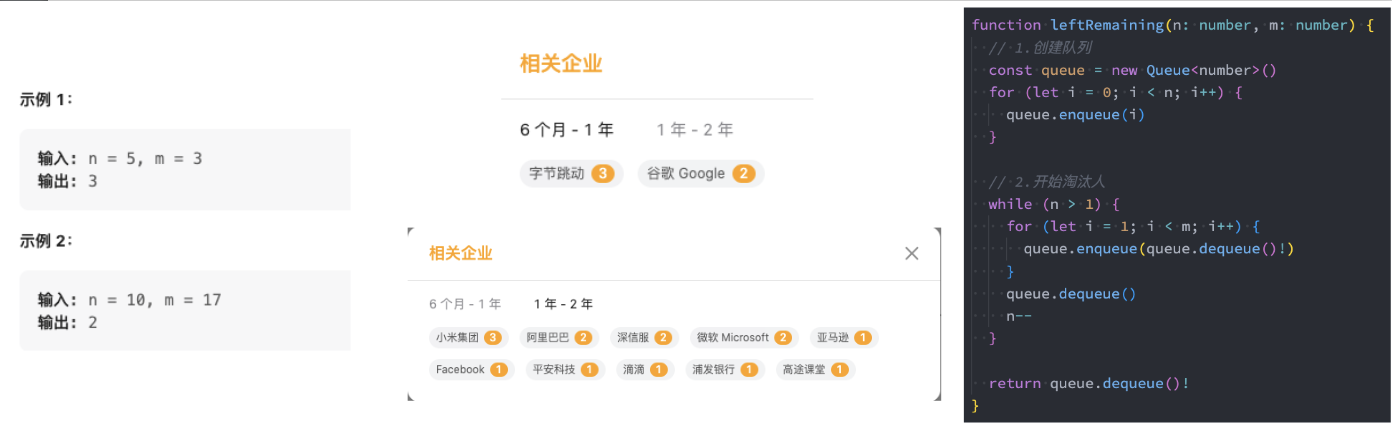
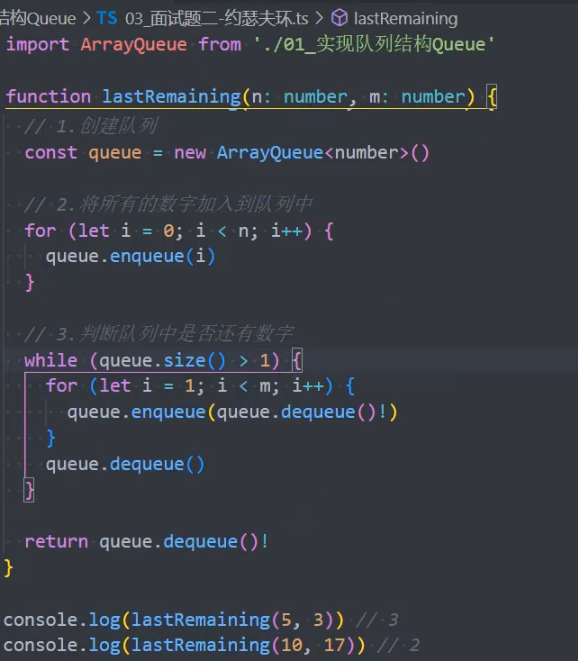
优化: 上述使用数组实现的队列来解决该面试题,性能并不高。使用 动态规划 的方法更优
链表结构(LinkedList)
链表以及数组的缺点
链表和数组一样,可以用于存储一系列的元素,但是链表和数组的实现机制完全不同。
这一章中,我们就来学习一下另外一种非常常见的用于存储数据的线性结构:链表。
数组:
- 要存储多个元素,数组(或选择链表)可能是最常用的数据结构。
- 我们之前说过,几乎每一种编程语言都有默认实现数组结构。
但是数组也有很多缺点:
- 数组的创建通常需要申请一段连续的内存空间(一整块的内存),并且大小是固定的(大多数编程语言数组都是固定的),所以当 当前数组不能满足容量需求时,需要扩容。 (一般情况下是申请一个更大的数组,比如2倍。 然后将原数组中的元素复制过去)
- 而且在数组开头或中间位置插入数据的成本很高,需要进行大量元素的位移。
- 尽管JavaScript的Array底层可以帮我们做这些事,但背后的原理依然是这样。
链表的优势
要存储多个元素,另外一个选择就是链表。
但不同于数组,链表中的元素在内存中不必是连续的空间。
- 链表的每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(有些语言称为指针或者链接)组成。
相对于数组,链表有一些优点:
- 内存空间不是必须连续的。
- 可以充分利用计算机的内存,实现灵活的内存动态管理。
- 链表不必在创建时就确定大小,并且大小可以无限的延伸下去。
- 链表在插入和删除数据时,时间复杂度可以达到O(1)。
- 相对数组效率高很多。
相对于数组,链表有一些缺点:
- 链表访问任何一个位置的元素时,都需要从头开始访问。(无法跳过第一个元素访问任何一个元素)。
- 无法通过下标直接访问元素,需要从头一个个访问,直到找到对应的元素。
链表到底是什么
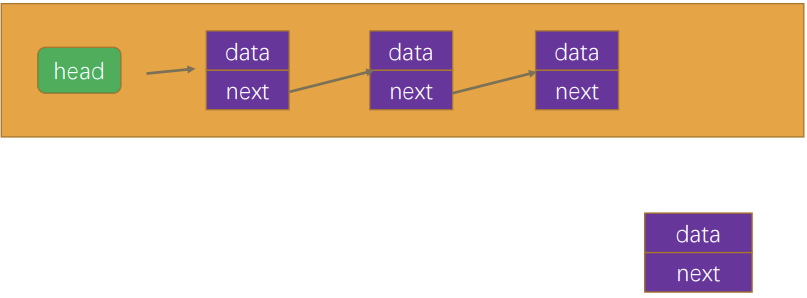
什么是链表呢?
- 其实上面我们已经简单的提过了链表的结构,我们这里更加详细的分析一下。
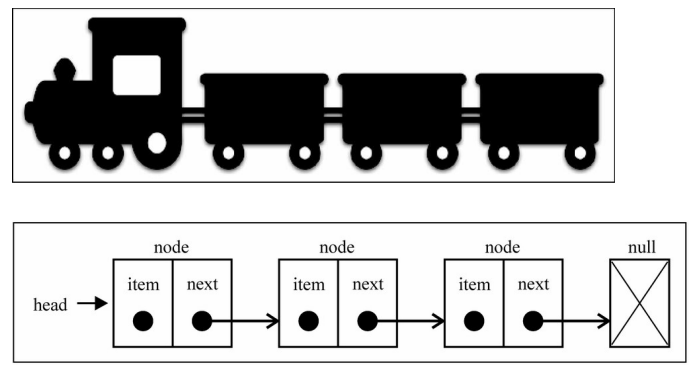
- 链表类似于火车:有一个火车头,火车头会连接一个节点,节点上有乘客(类似于数据),并且这个节点会连接下一个节点,以 此类推。
链表的火车结构:

链表结构的封装
我们先来创建一个链表类
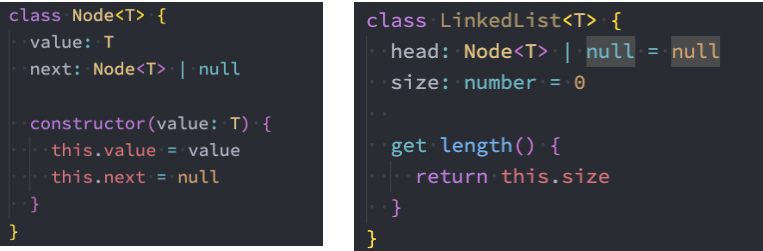
代码解析:
- 封装一个Node类,用于封装每一个节点上的信息(包括值和指向下一个节点的引用),它是一个泛型类。
- 封装一个LinkedList类,用于表示我们的链表结构。 (和Java中的链表同名,不同Java中的这个类是一个双向链表,在第二阶 段中我们也会实现双向链表结构)。
- 链表中我们保存两个属性,一个是链表的长度,一个是链表中第一个节点。
- 当然,还有很多链表的操作方法。 我们放在下一节中学习。
链表图片准备
链表常见操作
我们先来认识一下,链表中应该有哪些常见的操作
- append(element):向链表尾部添加一个新的项
- insert(position,element):向链表的特定位置插入一个新的项。
- get(position) :获取对应位置的元素
- indexOf(element):返回元素在链表中的索引。如果链表中没有该元素则返回-1。
- update(position,element) :修改某个位置的元素
- removeAt(position):从链表的特定位置移除一项。
- remove(element):从链表中移除一项。
- isEmpty():如果链表中不包含任何元素,返回true,如果链表长度大于0则返回false。
- size():返回链表包含的元素个数。与数组的length属性类似。
整体你会发现操作方法和数组非常类似,因为链表本身就是一种可以代替数组的结构。
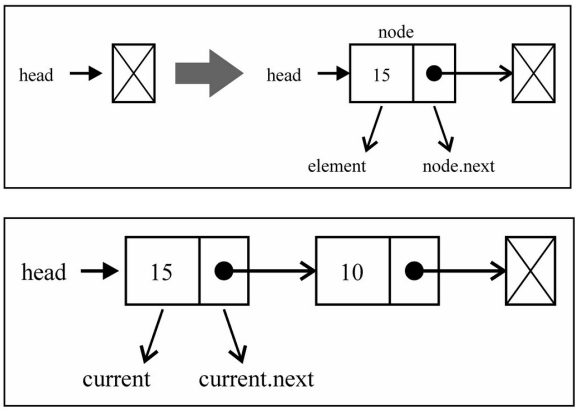
append方法
向链表尾部追加数据可能有两种情况:
- 链表本身为空,新添加的数据时唯一的节点。
- 链表不为空,需要向其他节点后面追加节点。
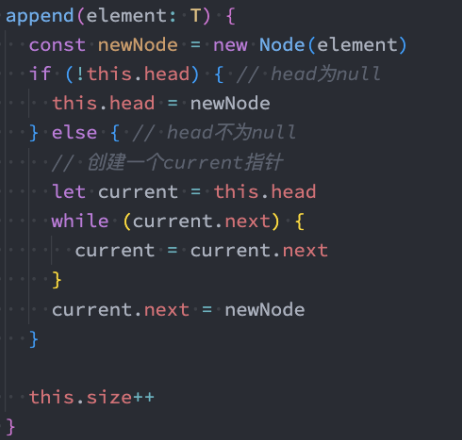
append追加方法
链表对象
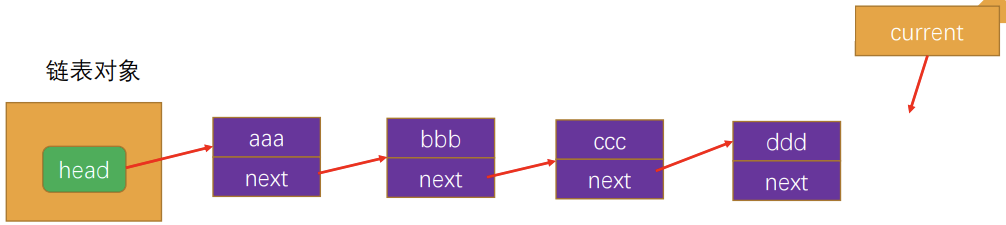
链表的遍历方法(traverse)
为了可以方便的看到链表上的每一个元素,我们实现一个遍历链表每一个元素的方法:
- 这个方法首先将当前结点设置为链表的头结点。
- 然后,在while循环中,我们遍历链表并打印当前结点的数据。
- 在每次迭代中,我们将当前结点设置为其下一个结点,直到遍历完整个链表。
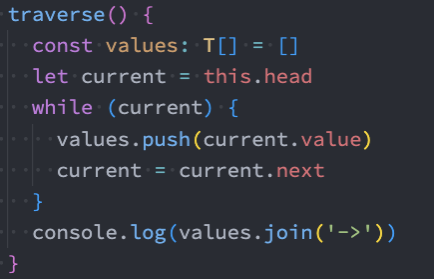
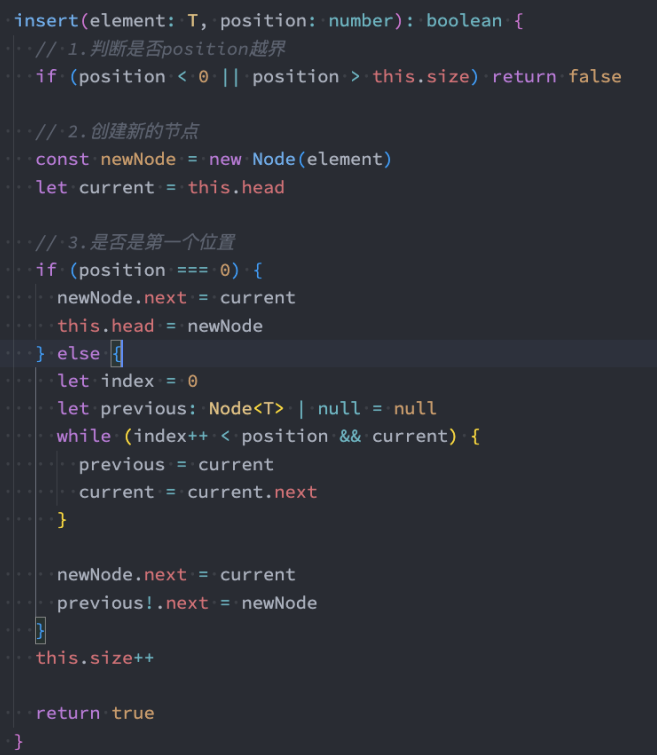
insert方法
接下来实现另外一个添加数据的方法:在任意位置插入数据。
添加到第一个位置:
- 添加到第一个位置,表示新添加的节点是头, 就需要将原来的头节点,作为新节点的next
- 另外这个时候的head应该指向新节点。
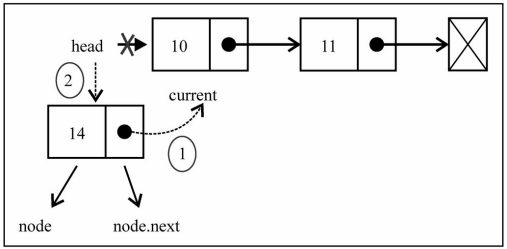
添加到其他位置:
- 如果是添加到其他位置,就需要先找到这个节点位置了。
- 我们通过while循环,一点点向下找。 并且在这个过程中保存上一个节 点和下一个节点。
- 找到正确的位置后,将新节点的next指向下一个节点,将上一个节点的 next指向新的节点。
insert方法的过程
链表对象
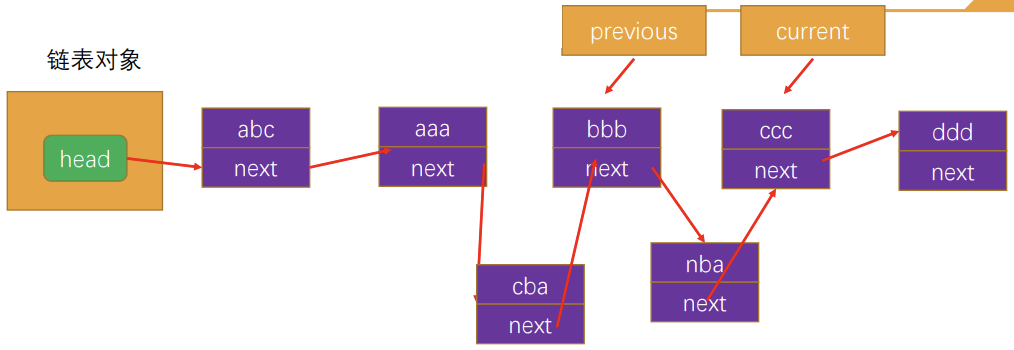
insert方法图解实现
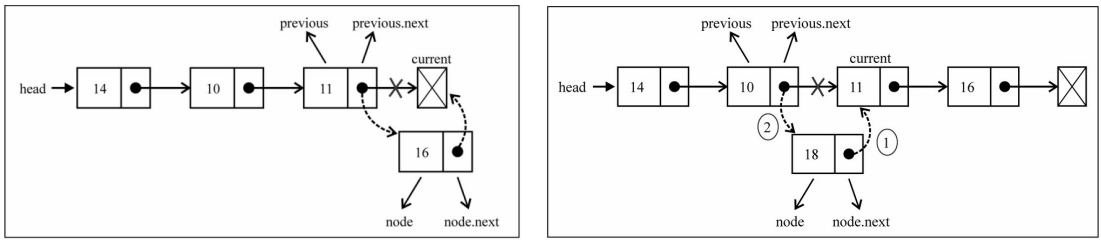
removeAt方法
移除数据有两种常见的方式:
- 根据位置移除对应的数据
- 根据数据,先找到对应的位置,再移除数据
移除第一项的信息:
- 移除第一项时,直接让head指向第二项信息就可以啦。
- 那么第一项信息没有引用指向,就在链表中不再有效,后 面会被回收掉。
移除其他项的信息:
- 移除其他项的信息操作方式是相同的。
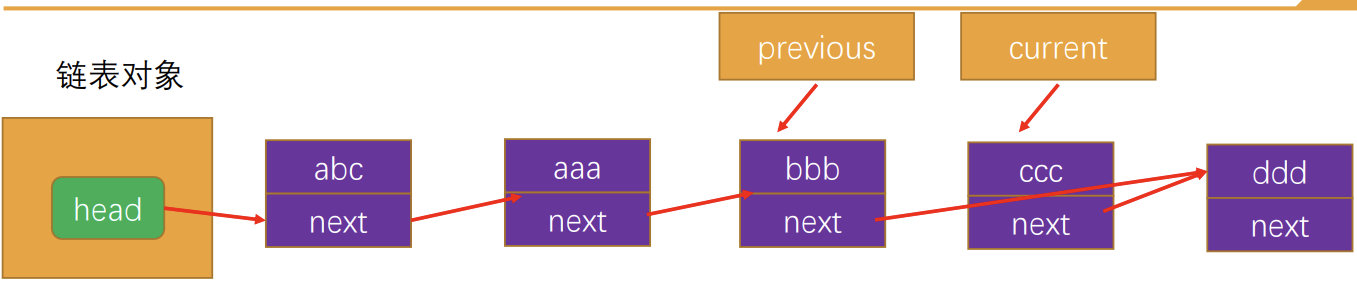
- 首先,我们需要通过while循环,找到正确的位置。
- 找到正确位置后,就可以直接将上一项的next指向current 项的next,这样中间的项就没有引用指向它,也就不再存 在于链表后,会面会被回收掉。

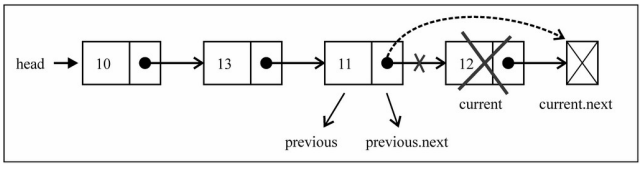
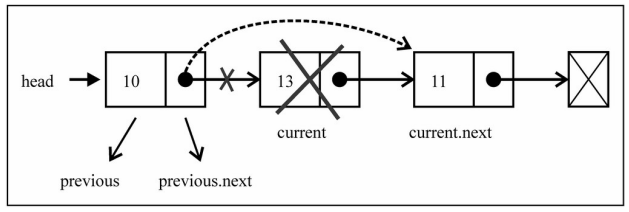
removeAt方法的过程
链表对象
removeAt方法图解实现
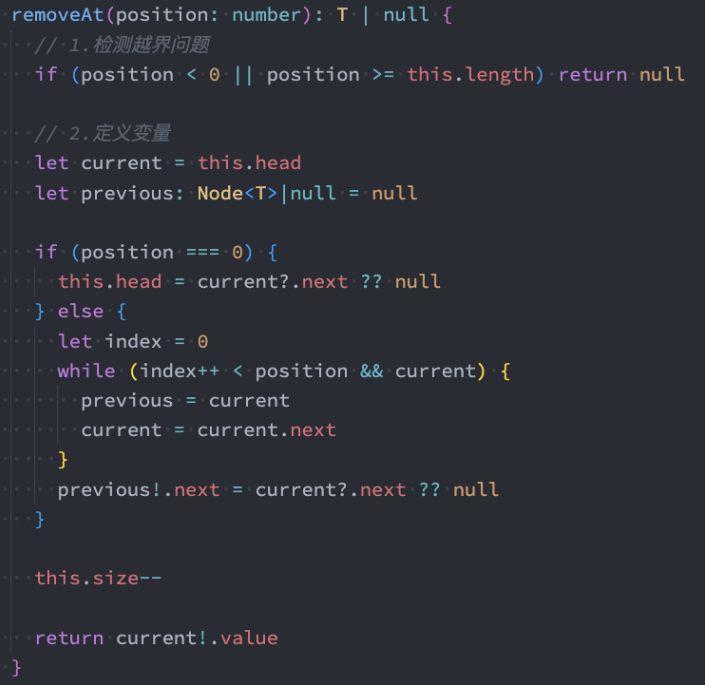
get方法
get(position) :获取对应位置的元素
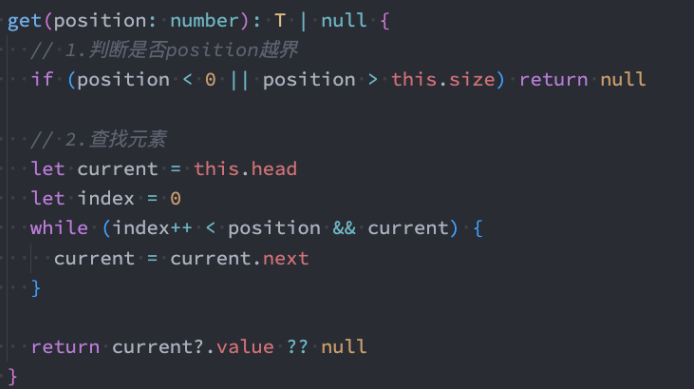
链表对象

遍历结点的操作重构
因为遍历结点的操作我们需要经常来做,所以可以进行如下的重构:
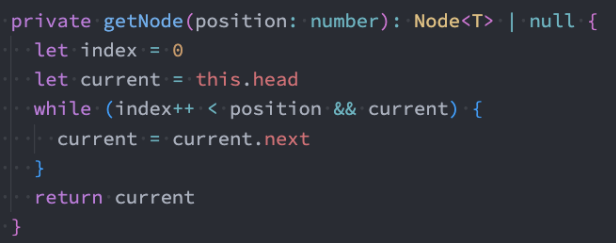
其他需要获取节点的,可以调用上面的方法,比如操作操作:
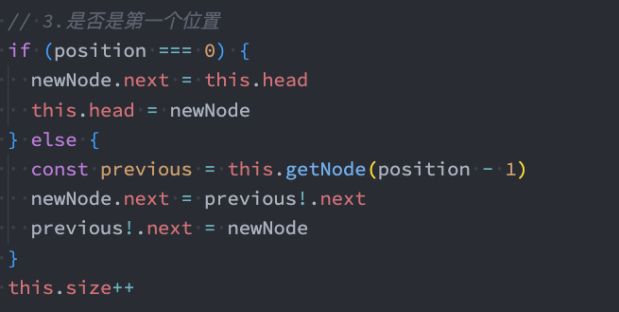
update方法
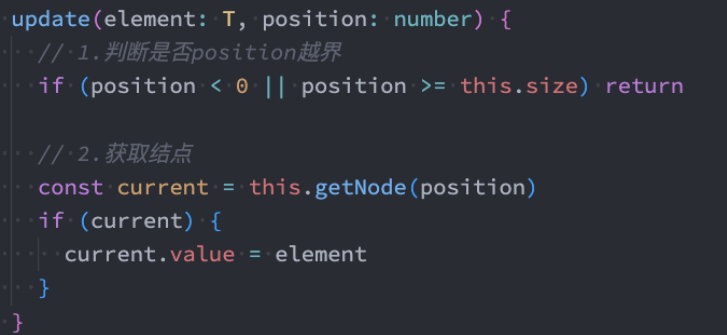
update(position,element) :修改某个位置的元素
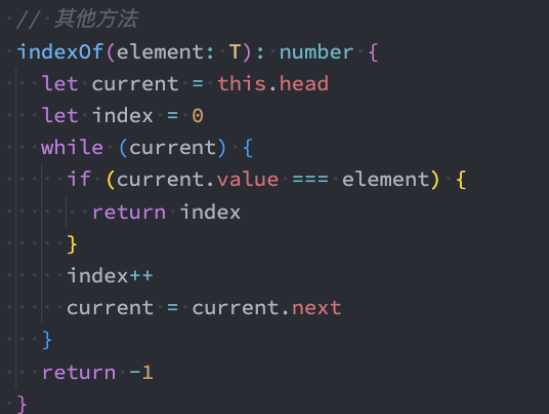
indexOf方法
我们来完成另一个功能:根据元素获取它在链表中的位置
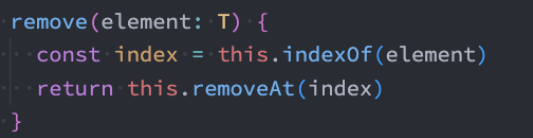
remove方法以及其他方法
有了上面的indexOf方法,我们可以非常方便实现根据元素来删除信息
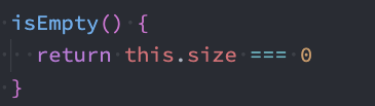
isEmpty方法
707. 设计链表 -字节、腾讯等公司面试题
- 设计链表
设计链表的实现。
- 您可以选择使用单链表或双链表。
- 单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。
- 如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能: • get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。 • addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。 • addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。 • addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到 链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 • deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
237. 删除链表中的节点 – 字节、阿里等公司面试题
- 删除链表中的节点

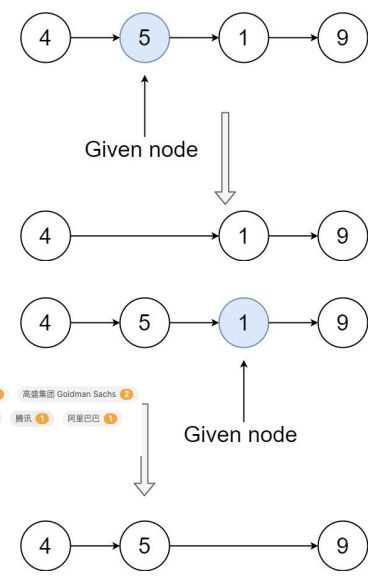
有一个单链表的 head,我们想删除它其中的一个节点 node。
- 给你一个需要删除的节点 node 。
- 你将 无法访问 第一个节点 head。
链表的所有值都是 唯一的,并且保证给定的节点 node 不是链表中的最后一个节点。
删除给定的节点。注意,删除节点并不是指从内存中删除它。这里的意思是: • 给定节点的值不应该存在于链表中。 • 链表中的节点数应该减少 1。 • node 前面的所有值顺序相同。 • node 后面的所有值顺序相同。

206. 反转链表 – 字节、谷歌等面试题
- 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
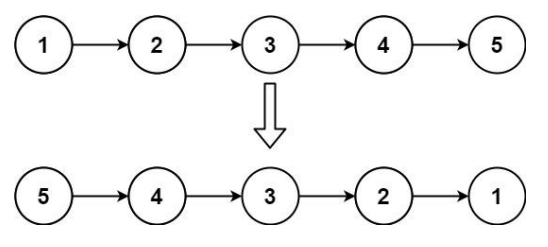
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
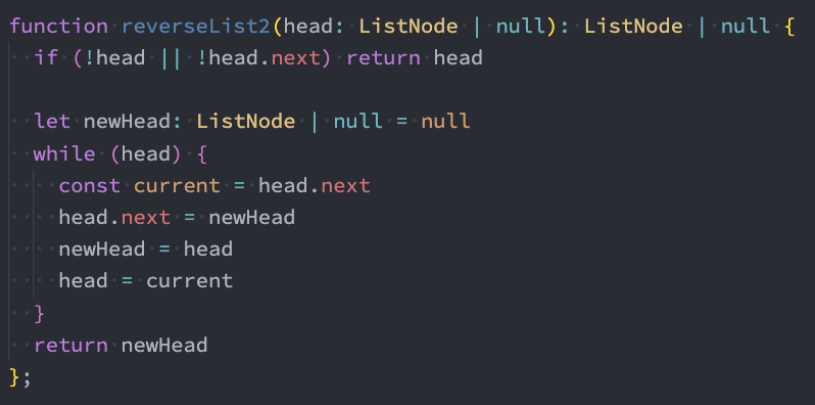
206. 反转链表(非递归)
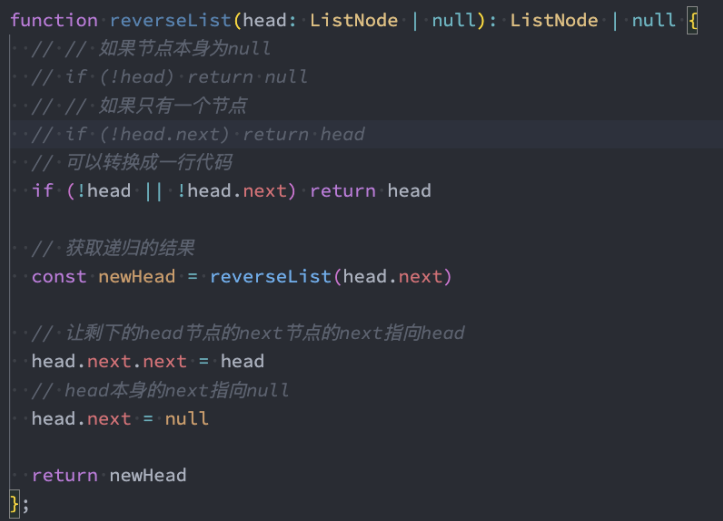
206. 反转链表(递归)
什么是算法复杂度(现实案例)
前面我们已经解释了什么是算法?其实就是解决问题的一系列步骤操作、逻辑。
对于同一个问题,我们往往其实有多种解决它的思路和方法,也就是可以采用不同的算法。
- 但是不同的算法,其实效率是不一样的。
举个例子(现实的例子):在一个庞大的图书馆中,我们需要找一本书。
- 在图书已经按照某种方式摆好的情况下(数据结构是固定的)

方式一:顺序查找
- 一本本找,直到找到想要的书;(累死)
方式二:先找分类,分类中找这本书
- 先找到分类,在分类中再顺序或者某种方式查找;
方式三:找到一台电脑,查找书的位置,直接找到;
- 图书馆通常有自己的图书管理系统;
- 利用图书管理系统先找到书的位置,再直接过去找到;
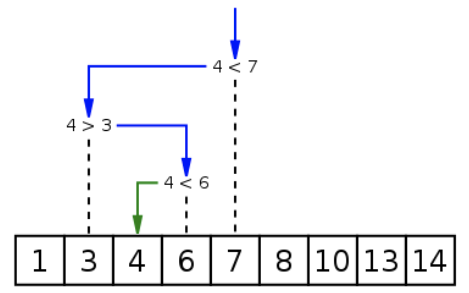
什么是算法复杂度(程序案例)
我们再具一个程序中的案例:让我们来比较两种不同算法在查找数组中(数组有序)给定元 素的时间复杂度。
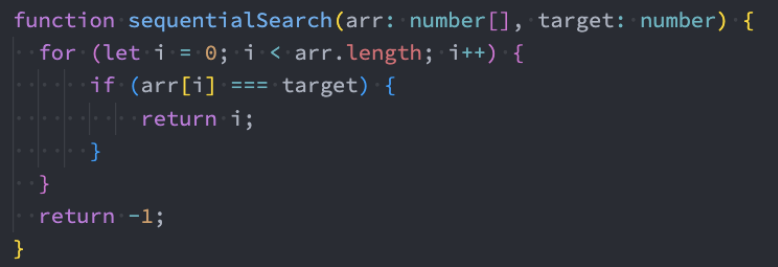
方式一: 顺序查找
- 这种算法从头到尾遍历整个数组,依次比较每个元素和给定元素的值。
- 如果找到相等的元素,则返回下标;如果遍历完整个数组都没找到,则返回-1。
方式二:二分查找
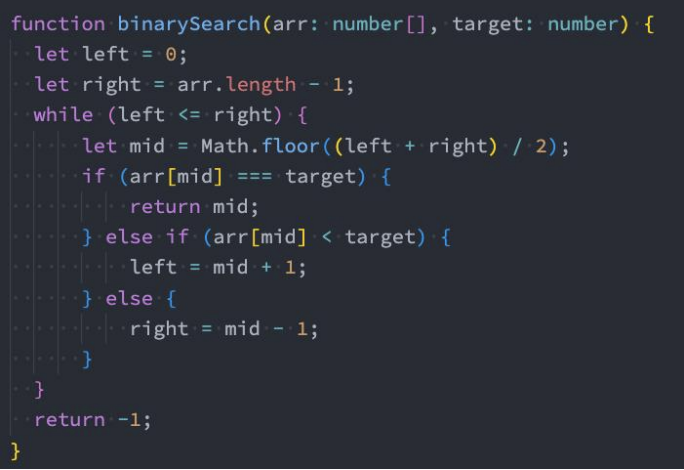
- 这种算法假设数组是有序的,每次选择数组中间的元素与给定元素进行比较。
- 如果相等,则返回下标;如果给定元素比中间元素小,则在数组的左半部分继续查找;
- 如果给定元素比中间元素大,则在数组的右半部分继续查找;
- 这样每次查找都会将查找范围减半,直到找到相等的元素或者查找范围为空;
顺序查找和二分查找的测试代码
顺序查找:
顺序查找算法的时间复杂度是O(n)

二分查找:

二分查找算法的时间复杂度是O(log n)

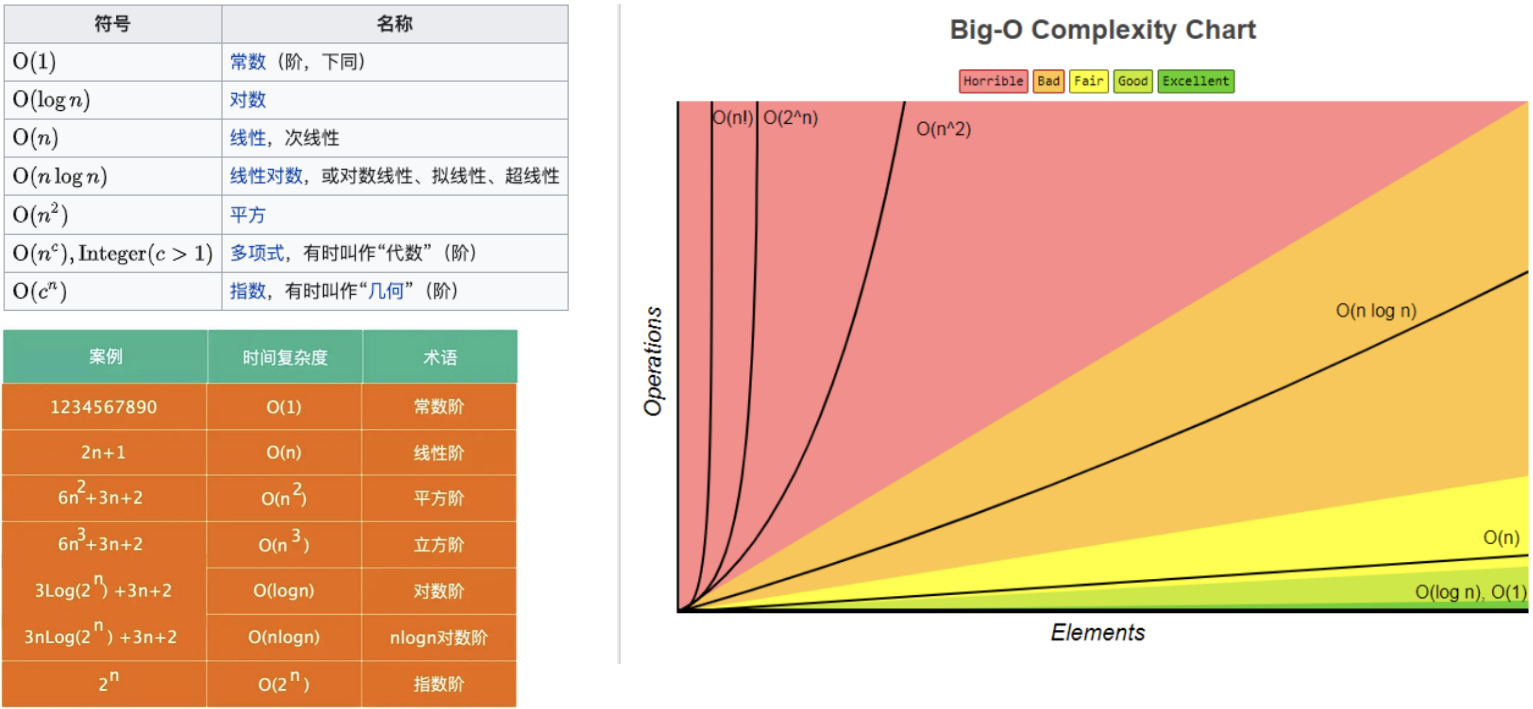
大O表示法(Big O notation)
大O表示法(Big O notation)英文翻译为大O符号(维基百科翻译),中文通常翻译为大O表示法(标记法)。
- 这个记号则是在德国数论学家爱德蒙·兰道的著作中才推广的,因此它有时又称为兰道符号(Landau symbols)。
- 代表“order of ...”(……阶)的大O,最初是一个大写希腊字母“Ο”(omicron),现今用的是大写拉丁字母“O”。
大O符号在分析算法效率的时候非常有用。
举个例子,解决一个规模为n的问题所花费的时间(或者所需步骤的数目)可以表示为:
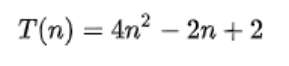
- 当n增大时,n²项开始占据主导地位,其他各项可以被忽略;
举例说明:当n=500
4n²项是2n项的1000倍大,因此在大多数场合下,省略后者对表达式的值的影响将是可以忽略不计的。
进一步看,如果我们与任一其他级的表达式比较,n²的系数也是无关紧要的。

我们就说该算法具有n²阶(平方阶)的时间复杂度,表示为O(n²)。
大O表示法 - 常见的对数结
常用的函数阶
空间复杂度
空间复杂度指的是程序运行过程中所需要的额外存储空间。
- 空间复杂度也可以用大O表示法来表示;
- 空间复杂度的计算方法与时间复杂度类似,通常需要分析程序中需要额外分配的内存空间,如数组、变量、对象、递归调用等。
举个栗子:
- 对于一个简单的递归算法来说,每次调用都会在内存中分配新的栈帧,这些栈帧占用了额外的空间。
- 因此,该算法的空间复杂度是O(n),其中n是递归深度。
- 而对于迭代算法来说,在每次迭代中不需要分配额外的空间,因此其空间复杂度为O(1)。
当空间复杂度很大时,可能会导致内存不足,程序崩溃。
在平时进行算法优化时,我们通常会进行如下的考虑:
- 使用尽量少的空间(优化空间复杂度);
- 使用尽量少的时间(优化时间复杂度);
- 特定情况下:使用空间换时间或使用时间换空间;
数组和链表的复杂度对比
接下来,我们使用大O表示法来对比一下数组和链表的时间复杂度:
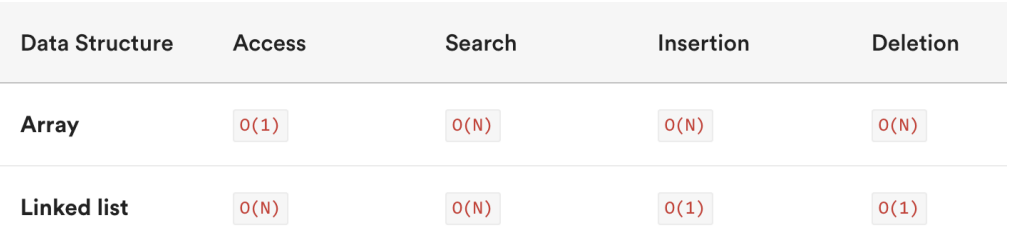
数组是一种连续的存储结构,通过下标可以直接访问数组中的任意元素。
- 时间复杂度:对于数组,随机访问时间复杂度为O(1),插入和删除操作时间复杂度为O(n)。
- 空间复杂度:数组需要连续的存储空间,空间复杂度为O(n)。
链表是一种链式存储结构,通过指针链接起来的节点组成,访问链表中元素需要从头结点开 始遍历。
- 时间复杂度:对于链表,随机访问时间复杂度为O(n),插入和删除操作时间复杂度为O(1)。
- 空间复杂度:链表需要为每个节点分配存储空间,空间复杂度为O(n)。 数组和链表的复杂度对比
在实际开发中,选择使用数组还是链表 需要根据具体应用场景来决定。
- 如果数据量不大,且需要频繁随机 访问元素,使用数组可能会更好。
- 如果数据量大,或者需要频繁插入 和删除元素,使用链表可能会更好。
哈希表(HashTable)
哈希表的介绍
哈希表是一种非常重要的数据结构,但是很多学习编程的人一直搞不懂哈希表到底是如何实现的。
- 在这一章节中,我们就一点点来实现一个自己的哈希表。
- 通过实现来理解哈希表背后的原理和它的优势。
几乎所有的编程语言都有直接或者间接的应用这种数据结构。
哈希表通常是基于数组进行实现的,但是相对于数组,它也很多的优势:
- 它可以提供非常快速的插入-删除-查找操作;
- 无论多少数据,插入和删除值都接近常量的时间:即O(1)的时间复杂度。实际上,只需要几个机器指令即可完成;
- 哈希表的速度比树还要快,基本可以瞬间查找到想要的元素;
- 哈希表相对于树来说编码要容易很多;
哈希表相对于数组的一些不足:
- 哈希表中的数据是没有顺序的,所以不能以一种固定的方式(比如从小到大)来遍历其中的元素(没有特殊处理情况下)。
- 通常情况下,哈希表中的key是不允许重复的,不能放置相同的key,用于保存不同的元素。
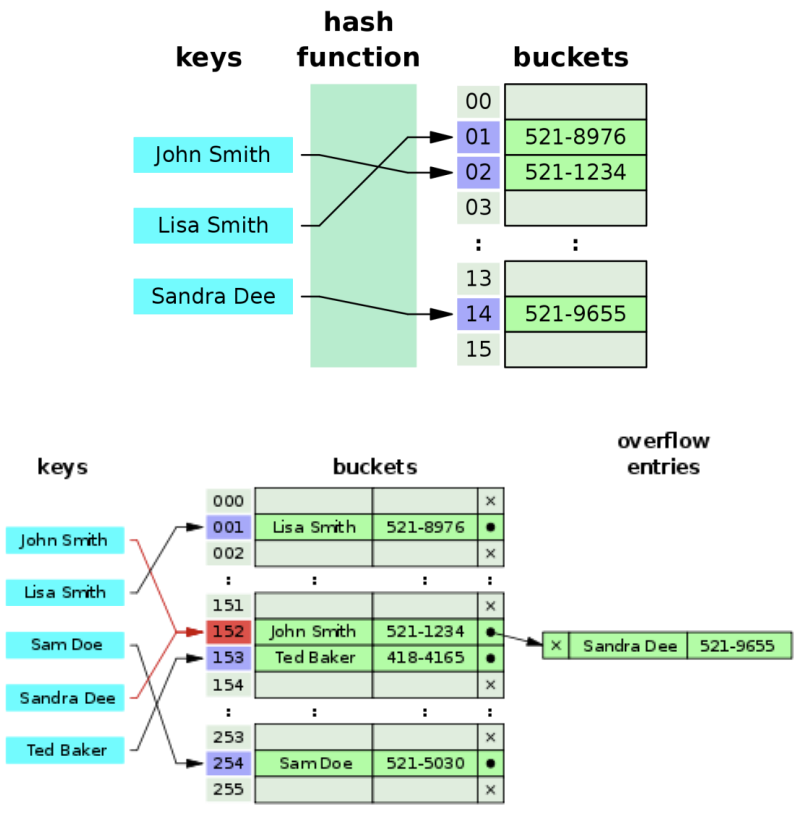
哈希表到底是什么呢
那么,哈希表到底是什么呢?
- 我们只是说了一下它的优势,似乎还是没有说它到底长什么样子?
- 这也是哈希表不好理解的地方,不像数组和链表,甚至是树一样直接 画出你就知道它的结构,甚至是原理了。
- 它的结构就是数组,但是它神奇的地方在于对数组下标值的一种变换, 这种变换我们可以使用哈希函数,通过哈希函数可以获取到 HashCode。
- 不着急,我们慢慢来认识它到底是什么。
我们通过二个案例,案例需要你挑选某种数据结构,而你会发现最好的 选择就是哈希表
- 案例一:公司使用一种数据结构来保存所有员工;
- 案例二:使用一种数据结构存储单词信息,比如有50000个单词。找 到单词后每个单词有自己的翻译&读音&应用等等;
案例一:公司员工存储
案例介绍:
- 假如一家公司有1000个员工,现在我们需要将这些员工的信息使用某种数据结构来保存起 来
- 你会采用什么数据结构呢?
方案一:数组
- 一种方案是按照顺序将所有的员工依次存入一个长度为1000的数组中。
- 每个员工的信息都保存在数组的某个位置上。
- 但是我们要查看某个具体员工的信息怎么办呢?一个个找吗?不太好找。
- 数组最大的优势是什么?通过下标值去获取信息。
- 所以为了可以通过数组快速定位到某个员工,最好给员工信息中添加一个员工编号(工号), 而编号对应的就是员工的下标值。
- 当查找某个员工的信息时,通过员工编号可以快速定位到员工的信息位置。
方案二:链表
- 链表对应插入和删除数据有一定的优势。
- 但是对于获取员工的信息,每次都必须从头遍历到尾,这种方式显然不是特别适合我们这里。
案例二:50000个单词的存储
案例介绍:
- 使用一种数据结构存储单词信息,比如有50000个单词。
- 找到单词后每个单词有自己的翻译&读音&应用等等
方案一:数组?
- 这个案例更加明显能感受到数组的缺陷。
- 我拿到一个单词 Iridescent,我想知道这个单词的翻译/读音/应用。
- 怎么可以从数组中查到这个单词的位置呢?
- 线性查找?50000次比较?
- 如果你使用数组来实现这个功能,效率会非常非常低,而且你一定没有学习过数据结构。
方案二:链表?
- 不需要考虑了吧?
方案三:有没有一种方案,可以将单词转成数组的下标值呢?
- 如果单词转成数组的下标,那么以后我们要查找某个单词的信息,直接按照下标值一步即可访问到想要的元素。
字母转数字的方案一
似乎所有的案例都指向了一目标:将字符串转成下标值
但是,怎样才能将一个字符串转成数组的下标值呢?
- 单词/字符串转下标值,其实就是字母/文字转数字
- 怎么转?
现在我们需要设计一种方案,可以将单词转成适当的下标值:
- 其实计算机中有很多的编码方案就是用数字代替单词的字符。就是 字符编码。(常见的字符编码?)
- 比如ASCII编码:a是97,b是98,依次类推122代表z
- 我们也可以设计一个自己的编码系统,比如a是1,b是2,c是3,依 次类推,z是26。
- 当然我们可以加上空格用0代替,就是27个字符(不考虑大写问题)
- 但是,有了编码系统后,一个单词如何转成数字呢?
方案一:数字相加
- 一种转换单词的简单方案就是把单词每个字符 的编码求和。
- 例如单词cats转成数字:3+1+20+19=43,那 么43就作为cats单词的下标存在数组中。
问题:按照这种方案有一个很明显的问题就是很多 单词最终的下标可能都是43。
- 比如was/tin/give/tend/moan/tick等等。
- 我们知道数组中一个下标值位置只能存储一个 数据
- 如果存入后来的数据,必然会造成数据的覆盖。
- 一个下标存储这么多单词显然是不合理的。
- 虽然后面的方案也会出现,但是要尽量避免。
字母转数字的方案二
方案二:幂的连乘
- 现在,我们想通过一种算法,让cats转成数字后不那么普通。
- 数字相加的方案就有些过于普通了。
- 有一种方案就是使用幂的连乘,什么是幂的连乘呢?
- 其实我们平时使用的大于10的数字,可以用一种幂的连乘来表示它的唯一性: 比如:7654 = 710³+610²+5*10+4
- 我们的单词也可以使用这种方案来表示:比如cats = 327³+127²+20*27+17= 60337
- 这样得到的数字可以基本保证它的唯一性,不会和别的单词重复。
问题:如果一个单词是zzzzzzzzzz(一般英文单词不会超过10个字符)。那么得到 的数字超过7000000000000。
- 数组可以表示这么大的下标值吗?
- 而且就算能创建这么大的数组,事实上有很多是无效的单词。
- 创建这么大的数组是没有意义的。
两种方案总结:
- 第一种方案(把数字相加求和)产生的数组 下标太少。
- 第二种方案(与27的幂相乘求和)产生的数 组下标又太多。
下标的压缩算法
现在需要一种压缩方法,把幂的连乘方案系统中得到的巨大整 数范围压缩到可接受的数组范围中。
对于英文词典,多大的数组才合适呢?
- 如果只有50000个单词,可能会定义一个长度为50000的 数组。
- 但是实际情况中,往往需要更大的空间来存储这些单词。 因为我们不能保证单词会映射到每一个位置。
- 比如两倍的大小:100000。
如何压缩呢?
- 现在,就找一种方法,把0到超过7000000000000的范围, 压缩为从0到100000。
- 有一种简单的方法就是使用取余操作符,它的作用是得到 一个数被另外一个数整除后的余数。
取余操作的实现:
- 为了看到这个方法如何工作,我们先来看一个小点的数字 范围压缩到一个小点的空间中。
- 假设把从0~199的数字,比如使用largeNumber代表, 压缩为从0到9的数字,比如使用smallRange代表。
- 下标值的结果:index = largeNumber % smallRange;
- 当一个数被10整除时,余数一定在0~9之间;
- 比如13%10=3,157%10=7。
- 当然,这中间还是会有重复,不过重复的数量明显变小了。因为我们的数组是100000,而只有50000个单词。
- 就好比,你在0~199中间选取5个数字,放在这个长度为 10的数组中,也会重复,但是重复的概率非常小。(后面 我们会讲到真的发生重复了应该怎么解决)
哈希表的一些概念
认识了上面的内容,相信你应该懂了哈希表的原理了,我们来看看几个概念:
- 哈希化:将大数字转化成数组范围内下标的过程,我们就称之为哈希化。
- 哈希函数:通常我们会将单词转成大数字,大数字在进行哈希化的代码实现放在一个函数中,这个函数我们称为哈希函数。
- 哈希表:最终将数据插入到的这个数组,对整个结构的封装,我们就称之为是一个哈希表。
但是,我们还有问题需要解决:
- 虽然,我们在一个100000的数组中,放50000个单词已经足够。
- 但是通过哈希化后的下标值依然可能会 重复,如何解决这种重复的问题呢?
什么是冲突
尽管50000个单词,我们使用了100000个位置来存 储,并且通过一种相对比较好的哈希函数来完成。但 是依然有可能会发生冲突。
- 比如melioration这个单词,通过哈希函数得到它 数组的下标值后,发现那个位置上已经存在一个 单词demystify
- 因为它经过哈希化后和melioration得到的下标实 现相同的。
这种情况我们成为冲突。
虽然我们不希望这种情况发生,当然更希望每个下标 对应一个数据项,但是通常这是不可能的。
冲突不可避免,我们只能解决冲突。

就像之前0~199的数字选取5个放在长度为10的单元格中
- 如果我们随机选出来的是33,82,11,45,90,那么最终它们的位置 会是3-2-1-5-0,没有发生冲突。
- 但是如果其中有一个33,还有一个73呢?还是发生了冲突。
我们需要针对 这种冲突 提出一些解决方案
- 虽然冲突的可能性比较小,你依然需要考虑到这种情况
- 以便发生的时候进行对应的处理代码。
如何解决这种冲突呢?常见的情况有两种方案。
- 链地址法。
- 开放地址法。
链地址法
链地址法是一种比较常见的解决冲突的方案。(也称为拉链法)
- 其实,如果你理解了为什么产生冲突,看到图后就可以立马理解链地址法是什么含义了。
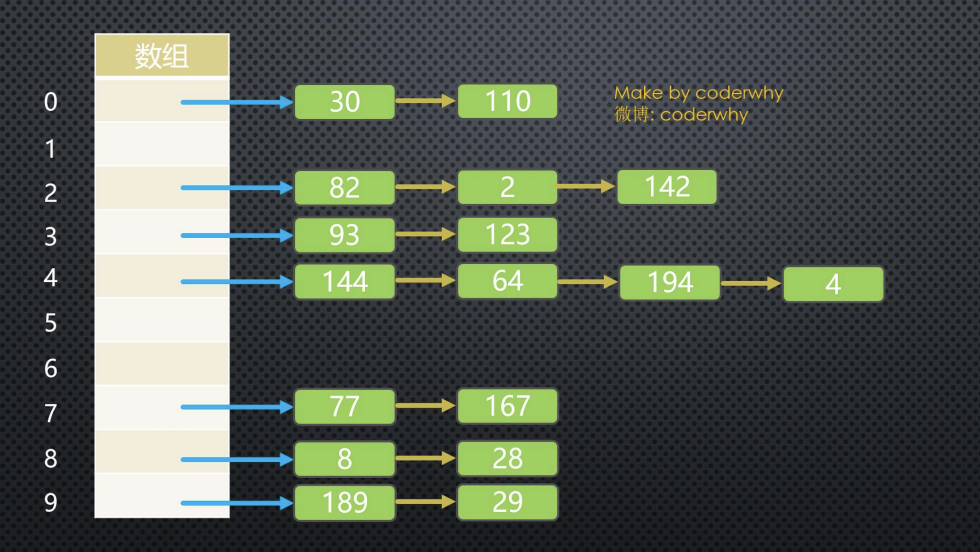
链地址法解析
图片解析:
- 从图片中我们可以看出,链地址法解决冲突的办法是每个数组单元中存储的不再是单个数据,而是一个链条。
- 这个链条使用什么数据结构呢?常见的是数组或者链表。
- 比如是链表,也就是每个数组单元中存储着一个链表。一旦发现重复,将重复的元素插入到链表的首端或者末端即可。
- 当查询时,先根据哈希化后的下标值找到对应的位置,再取出链表,依次查询找寻找的数据。
数组还是链表呢?
- 数组或者链表在这里其实都可以,效率上也差不多。
- 因为根据哈希化的index找出这个数组或者链表时,通常就会使用线性查找,这个时候数组和链表的效率是差不多的。
- 当然在某些实现中,会将新插入的数据放在数组或者链表的最前面,因为觉得新插入的数据用于取出的可能性更大。
- 这种情况最好采用链表,因为数组在首位插入数据是需要所有其他项后移的,链表就没有这样的问题。
- 当然,我觉得出于这个也看业务需求,不见得新的数据就访问次数会更多:比如我们微信新添加的好友,可能是刚认识的, 联系的频率不见得比我们的老朋友更多,甚至新加的只是聊一两句。
- 所以,这里个人觉得选择数组或者链表都是可以的。
开放地址法
开放地址法的主要工作方式是寻找空白的单元格来添加重复的数据。
我们还是通过图片来了解开放地址法的工作方式。

图片解析:
从图片的文字中我们可以了 解到
开放地址法其实就是要寻找 空白的位置来放置冲突的数 据项。
但是探索这个位置的方式不同, 有三种方法:
线性探测
二次探测
再哈希法
线性探测
线性探测非常好理解:线性的查找空白的单元。
插入的32:
- 经过哈希化得到的index=2,但是在插入的时候,发现该位置已经有了82。怎么办呢?
- 线性探测就是从index位置+1开始一点点查找合适的位置来放置32,什么是合适的位置呢?
- 空的位置就是合适的位置,在我们上面的例子中就是index=3的位置,这个时候32就会放在该位置。
查询32呢?
- 查询32和插入32比较相似。
- 首先经过哈希化得到index=2,比如2的位置结果和查询的数值是否相同,相同那么就直接返回。
- 不相同呢?线性查找,从index位置+1开始查找和32一样的。
- 这里有一个特别需要注意的地方:如果32的位置我们之前没有插入,是否将整个哈希表查询一遍来确定32存不存在吗?
- 当然不是,查询过程有一个约定,就是查询到空位置,就停止。
- 因为查询到这里有空位置,32之前不可能跳过空位置去其他的位置。
线性探测的问题
删除32呢?
- 删除操作和插入查询比较类似,但是也有一个特别注意点。
- 注意:删除操作一个数据项时,不可以将这个位置下标的内容设置为null,为什么呢?
- 因为将它设置为null可能会影响我们之后查询其他操作,所以通常删除一个位置的数据项时,我们可以将它进行特殊处理(比 如设置为-1)。
- 当我们之后看到-1位置的数据项时,就知道查询时要继续查询,但是插入时这个位置可以放置数据。
线性探测的问题:
- 线性探测有一个比较严重的问题,就是聚集。什么是聚集呢?
- 比如我在没有任何数据的时候,插入的是22-23-24-25-26,那么意味着下标值:2-3-4-5-6的位置都有元素。
- 这种一连串填充单元就叫做聚集。
- 聚集会影响哈希表的性能,无论是插入/查询/删除都会影响。
- 比如我们插入一个32,会发现连续的单元都不允许我们放置数据,并且在这个过程中我们需要探索多次。
- 二次探测可以解决一部分这个问题,我们一起来看一看。
二次探测
我们刚才谈到,线性探测存在的问题:
- 如果之前的数据是连续插入的,那么新插入的一个数据可能需要探测很长的距离。
二次探测在线性探测的基础上进行了优化:
- 二次探测主要优化的是探测时的步长,什么意思呢?
- 线性探测,我们可以看成是步长为1的探测,比如从下标值x开始,那么线性测试就是x+1,x+2,x+3依次探测。
- 二次探测,对步长做了优化,比如从下标值x开始,x+1²,x+2²,x+3²。
- 这样就可以一次性探测比较长的距离,比避免那些聚集带来的影响。
二次探测的问题:
- 但是二次探测依然存在问题,比如我们连续插入的是32-112-82-2-192,那么它们依次累加的时候步长的相同的。
- 也就是这种情况下会造成步长不一样的一种聚集。还是会影响效率。(当然这种可能性相对于连续的数字会小一些)
- 怎么根本解决这个问题呢?让每个人的步长不一样,一起来看看再哈希法吧。
再哈希法
为了消除线性探测和二次探测中无论步长+1还是步长+平法中存在的问题, 还有一种最常用的解决方案: 再哈希法.
再哈希法:
- 二次探测的算法产生的探测序列步长是固定的: 1, 4, 9, 16, 依次类推.
- 现在需要一种方法: 产生一种依赖关键字的探测序列, 而不是每个关键字都一样.
- 那么, 不同的关键字即使映射到相同的数组下标, 也可以使用不同的探测序列.
- 再哈希法的做法就是: 把关键字用另外一个哈希函数, 再做一次哈希化, 用这次哈希化的结果作为步长.
- 对于指定的关键字, 步长在整个探测中是不变的, 不过不同的关键字使用不同的步长.
第二次哈希化需要具备如下特点:
- 和第一个哈希函数不同. (不要再使用上一次的哈希函数了, 不然结果还是原来的位置)
- 不能输出为0(否则, 将没有步长. 每次探测都是原地踏步, 算法就进入了死循环)
其实, 我们不用费脑细胞来设计了, 计算机专家已经设计出一种工作很好的哈希函数:
- stepSize = constant - (key % constant)
- 其中constant是质数, 且小于数组的容量.
- 例如: stepSize = 5 - (key % 5), 满足需求, 并且结果不可能为0.
哈希化的效率
哈希表中执行插入和搜索操作效率是非常高的
- 如果没有产生冲突,那么效率就会更高。
- 如果发生冲突,存取时间就依赖后来的探测长度。
- 平均探测长度以及平均存取时间,取决于填装因子,随着填装因子变大,探测长度也越来越长。
- 随着填装因子变大,效率下降的情况,在不同开放地址法方案中比链地址法更严重,所以我们来对比一下他们的效率,再决 定我们选取的方案。
在分析效率之前,我们先了解一个概念:装填因子。
- 装填因子表示当前哈希表中已经包含的数据项和整个哈希表长度的比值。
- 装填因子 = 总数据项 / 哈希表长度。
- 开放地址法的装填因子最大是多少呢?1,因为它必须寻找到空白的单元才能将元素放入。
- 链地址法的装填因子呢?可以大于1,因为拉链法可以无限的延伸下去,只要你愿意。(当然后面效率就变低了)
线性探测效率
下面的等式显示了线性探测时,探测序列(P)和填装因子(L)的关系
公式来自于Knuth(算法分析领域的专家,现代计算机的先驱人物),这些公式的推导自己去看了一下,确实有些繁琐,这里不再 给出推导过程,仅仅说明它的效率。
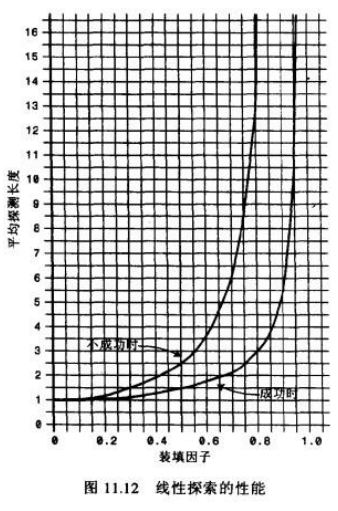
图片解析:
当填装因子是1/2时,成功的搜索需要1.5次比较,不成功的搜索需要2.5次
当填装因子为2/3时,分别需要2.0次和5.0次比较
如果填装因子更大,比较次数会非常大。
应该使填装因子保持在2/3以下,最好在1/2以下,另一方面,填装因子越低,对于给定数 量的数据项,就需要越多的空间。
实际情况中,最好的填装因子取决于存储效率和速度之间的平衡,随着填装因子变小,存储 效率下降,而速度上升。
二次探测和再哈希化
二次探测和再哈希法的性能相当。它们的性能比线性探测略好。
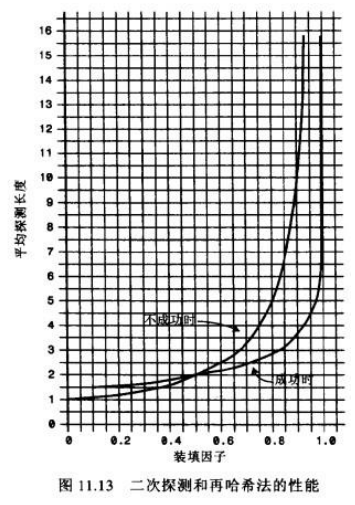
图片解析:
当填装因子是0.5时,成功和不成的查找平均需要2次比较
当填装因子为2/3时,分别需要2.37和3.0次比较
当填装因子为0.8时,分别需要2.9和5.0次
因此对于较高的填装因子,对比线性探测,二次探测和再哈希法还是可以忍受的。
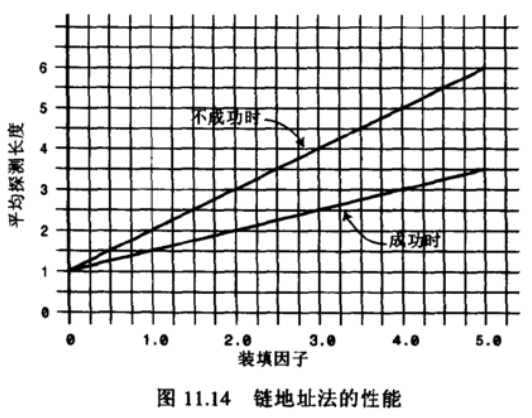
链地址法
链地址法的效率分析有些不同,一般来说比开放地址法简单。我们来分析一下这个公式应该是怎么样的。
- 假如哈希表包含arraySize个数据项,每个数据项有一个链表,在表中一共包含N个数据项。
- 那么,平均起来每个链表有多少个数据项呢?非常简单,N / arraySize。
- 有没有发现这个公式有点眼熟?其实就是装填因子。
OK,那么我们现在就可以求出查找成功和不成功的次数了
- 成功可能只需要查找链表的一半即可:1 + loadFactor/2
- 不成功呢?可能需要将整个链表查询完才知道不成功:1 + loadFactor。
经过上面的比较我们可以发现,链地址法相对来说效率是好于开放地址法的。
所以在真实开发中,使用链地址法的情况较多
- 因为它不会因为添加了某元素后性能急剧下降。
- 比如在Java的HashMap中使用的就是链地址法。
哈希函数
讲了很久的哈希表理论知识,你有没有发现在整个过程中,一个非常重要的东西:哈希函数呢?
好的哈希函数应该尽可能让计算的过程变得简单,提高计算的效率。
- 哈希表的主要优点是它的速度,所以在速度上不能满足,那么就达不到设计的目的了。
- 提高速度的一个办法就是让哈希函数中尽量少的有乘法和除法。因为它们的性能是比较低的。
设计好的哈希函数应该具备哪些优点呢?
- 快速的计算
- 哈希表的优势就在于效率,所以快速获取到对应的hashCode非常重要。
- 我们需要通过快速的计算来获取到元素对应的hashCode
- 均匀的分布
- 哈希表中,无论是链地址法还是开放地址法,当多个元素映射到同一个位置的时候,都会影响效率。
- 所以,优秀的哈希函数应该尽可能将元素映射到不同的位置,让元素在哈希表中均匀的分布。
快速计算:霍纳法则
在前面,我们计算哈希值的时候使用的方式
- cats = 327³+127²+20*27+17= 60337
这种方式是直观的计算结果,那么这种计算方式会进行 几次乘法几次加法呢?
- 当然,我们可能不止4项,可能有更多项
- 我们抽象一下,这个表达式其实是一个多项式:
- a(n)x^n+a(n-1)x^(n-1)+…+a(1)x+a(0)
现在问题就变成了多项式有多少次乘法和加法:
- 乘法次数:n+(n-1)+…+1=n(n+1)/2
- 加法次数:n次
- O(N²)
多项式的优化:霍纳法则
- 解决这类求值问题的高效算法--霍纳法则。在中国,霍纳法则 也被称为秦九韶算法。
通过如下变换我们可以得到一种快得多的算法,即
- Pn(x)= anx^n+a(n-1)x^(n-1)+…+a1x+a0=
- ((…(((anx +an-1)x+an-2)x+ an-3)…)x+a1)x+a0,
- 这种求值的方式我们称为霍纳法则。
变换后,我们需要多少次乘法,多少次加法呢?
- 乘法次数:N次
- 加法次数:N次。
如果使用大O表示时间复杂度的话,我们直接从O(N²)降到了 O(N)。
均匀分布
均匀的分布
- 在设计哈希表时,我们已经有办法处理映射到相同下标值的情况:链地址法或者开放地址法。
- 但是无论哪种方案,为了提供效率,最好的情况还是让数据在哈希表中均匀分布。
- 因此,我们需要在使用常量的地方,尽量使用质数。
- 哪些地方我们会使用到常量呢?
质数的使用:
- 哈希表的长度。
- N次幂的底数(我们之前使用的是27)
为什么他们使用质数,会让哈希表分布更加均匀呢?
- 质数和其他数相乘的结果相比于其他数字更容易产生唯一性的结果,减少哈希冲突。
- Java中的N次幂的底数选择的是31,是经过长期观察分布结果得出的;
Java中的HashMap
Java中的哈希表采用的是链地址法。
HashMap的初始长度是16,每次自动扩展(我们还没有聊到扩展的话题),长度必须是2的次幂。
- 这是为了服务于从Key映射到index的算法。60000000 % 100 = 数字。下标值
HashMap中为了提高效率,采用了位运算的方式。
- HashMap中index的计算公式:index = HashCode(Key) & (Length - 1)
- 比如计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001
- 假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111
- 把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9
但是,我个人发现JavaScript中进行较大数据的位运算时会出问题,所以我的代码实现中还是使用了取模。
- 另外,我这里为了方便代码之后向开放地址法中迁移,容量还是选择使用质数。
N次幂的底数
这里采用质数的原因是为了产生的数据不按照某种规律递增。
- 比如我们这里有一组数据是按照4进行递增的:0 4 8 12 16,将其映射到长度为8的哈希表中。
- 它们的位置是多少呢?0 - 4 - 0 - 4,依次类推。
- 如果我们哈希表本身不是质数,而我们递增的数量可以使用质数,比如5,那么 0 5 10 15 20
- 它们的位置是多少呢?0 - 5 - 2 - 7 - 4,依次类推。也可以尽量让数据均匀的分布。
- 我们之前使用的是27,这次可以使用一个接近的数,比如31/37/41等等。一个比较常用的数是31或37。
总之,质数是一个非常神奇的数字。
这里建议两处都使用质数:
- 哈希表中数组的长度。
- N次幂的底数。
哈希表的实现
现在,我们就给出哈希函数的实现:
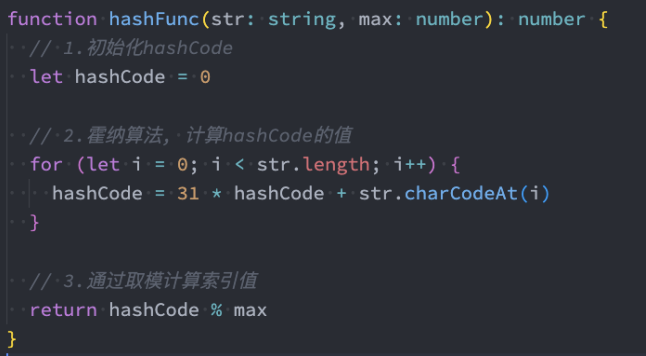
测试代码
创建哈希表
经过前面那么多内容的学习,我们现在可以真正实现自己的哈希表了。
- 可能你学到这里的时候,已经感觉到数据结构的一些复杂性;
- 但是如果你仔细品味,你也会发现它在设计时候的巧妙和优美;
- 当你爱上它的那一刻,你也真正爱上了编程,爱上数据结构;
我们这里采用链地址法来实现哈希表:
- 实现的哈希表(基于storage的数组)每个index对应的是一个数组(bucket)。(当然基于链表也可以。)
- bucket中存放什么呢?我们最好将key和value都放进去,我们继续使用一个数组。(其实其他语言使用元组更好)
- 最终我们的哈希表的数据格式是这样:[[ [k,v],[k,v],[k,v] ] ,[ [k,v],[k,v] ],[ [k,v] ] ]
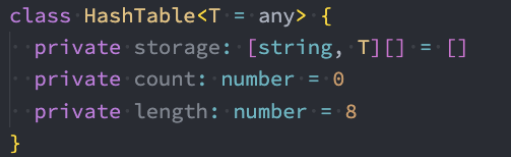
代码解析:
- 我们定义了三个属性:
- storage作为我们的数组,数组中存放相关的元素。
- count表示当前已经存在了多少数据。
- limit用于标记数组中一共可以存放多少个元素。
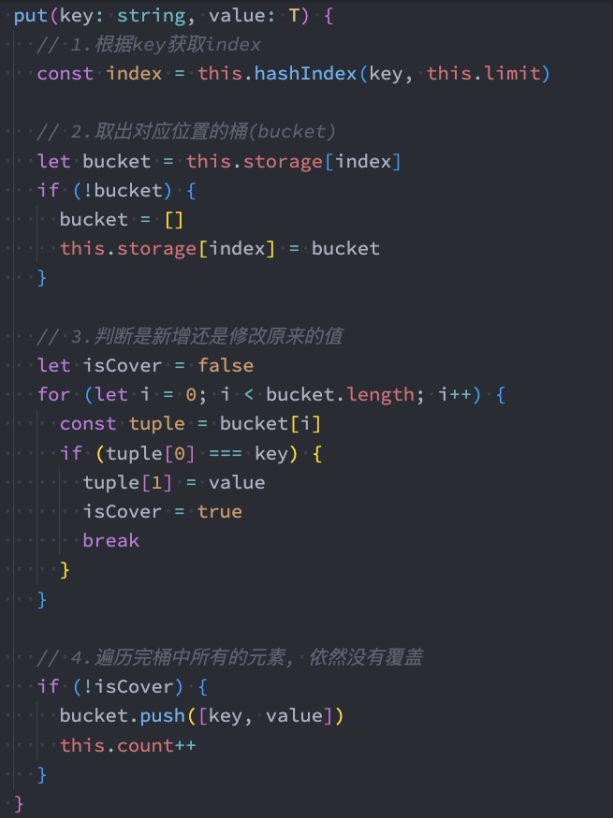
插入&修改数据
哈希表的插入和修改操作是同一个函数:
- 因为,当使用者传入一个
<Key,Value>时 - 如果原来不存该key,那么就是插入操作。
- 如果已经存在该key,那么就是修改操作。
代码解析:
步骤1:根据传入的key获取对应的hashCode,也就是数组的index
步骤2:从哈希表的index位置中取出桶(另外一个数组)
步骤3:查看上一步的bucket是否为null
- 为null,表示之前在该位置没有放置过任何的内容,那么就新建一个数组[]
步骤4:查看是否之前已经放置过key对应的value
- 如果放置过,那么就是依次替换操作,而不是插入新的数据。
- 我们使用一个变量override来记录是否是修改操作
步骤5:如果不是修改操作,那么插入新的数据。
- 在bucket中push新的[key,value]即可。
- 注意:这里需要将count+1,因为数据增加了一项。
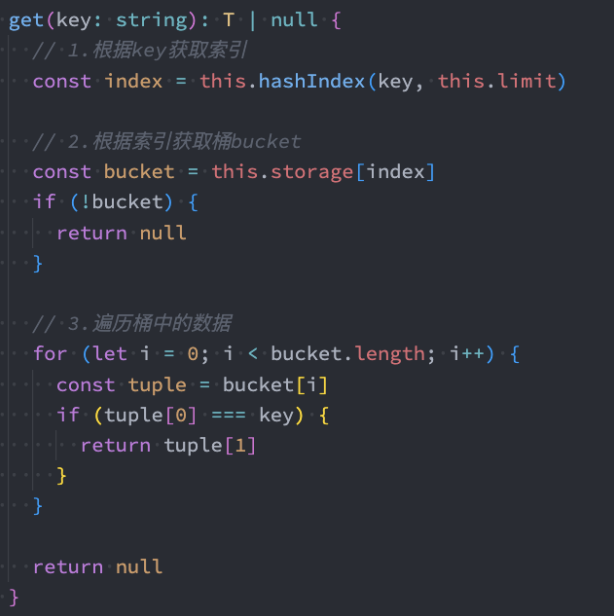
获取数据
获取数据:
- 根据key获取对应的value
代码解析:
- 步骤1:根据key获取hashCode(也就是index)
- 步骤2:根据index取出bucket。
- 步骤3:因为如果bucket都是null,那么说明这个位置之前并没有 插入过数据。
- 步骤4:有了bucket,就遍历,并且如果找到,就将对应的value 返回即可。
- 步骤5:没有找到,返回null
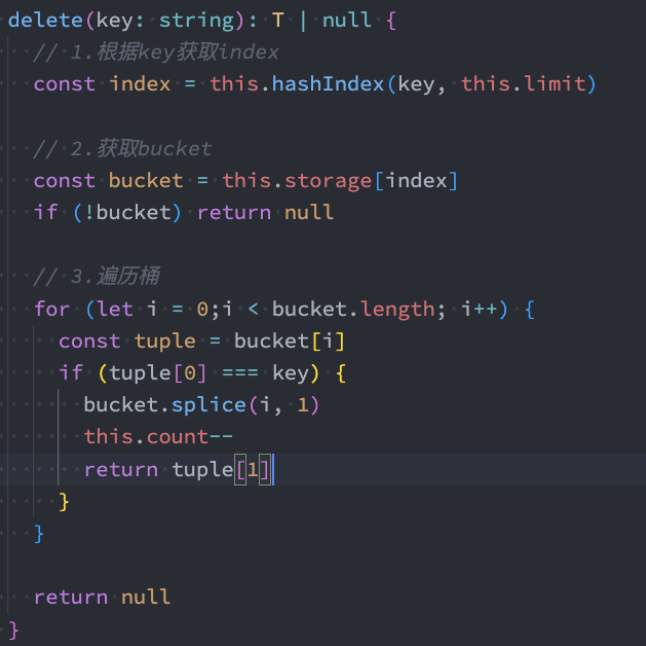
删除数据
删除数据:
- 我们根据对应的key,删除对应的key/value
代码解析:
- 思路和获取数据相似,不再给出解析
哈希表扩容的思想
为什么需要扩容?
- 目前,我们是将所有的数据项放在长度为7的数组中的。
- 因为我们使用的是链地址法,loadFactor可以大于1,所以这个哈希表可以无限制的插入新数据。
- 但是,随着数据量的增多,每一个index对应的bucket会越来越长,也就造成效率的降低。
- 所以,在合适的情况对数组进行扩容,比如扩容两倍。
如何进行扩容?
- 扩容可以简单的将容量增大两倍(不是质数吗?质数的问题后面再讨论)
- 但是这种情况下,所有的数据项一定要同时进行修改(重新调用哈希函数,来获取到不同的位置)
- 比如hashCode=12的数据项,在length=8的时候,index=4。在长度为16的时候呢?index=12。
- 这是一个耗时的过程,但是如果数组需要扩容,那么这个过程是必要的。
什么情况下扩容呢?
- 比较常见的情况是loadFactor>0.75的时候进行扩容。
- 比如Java的哈希表就是在装填因子大于0.75的时候,对哈希表进行扩容。
扩容函数
我们来实现一下扩容函数
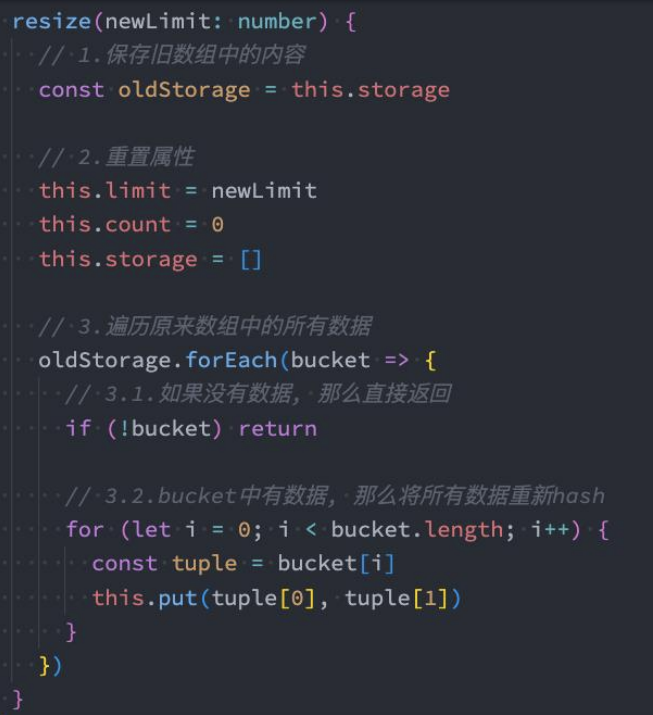
代码解析:
- 步骤1:先将之前数组保存起来,因为我们待会儿会将storeage = []
- 步骤2:之前的属性值需要重置。
- 步骤3:遍历所有的数据项,重新插入到哈希表中。
在什么时候调用扩容方法呢?
- 在每次添加完新的数据时,都进行判断。(也就是put方法中)
put/remove方法修改

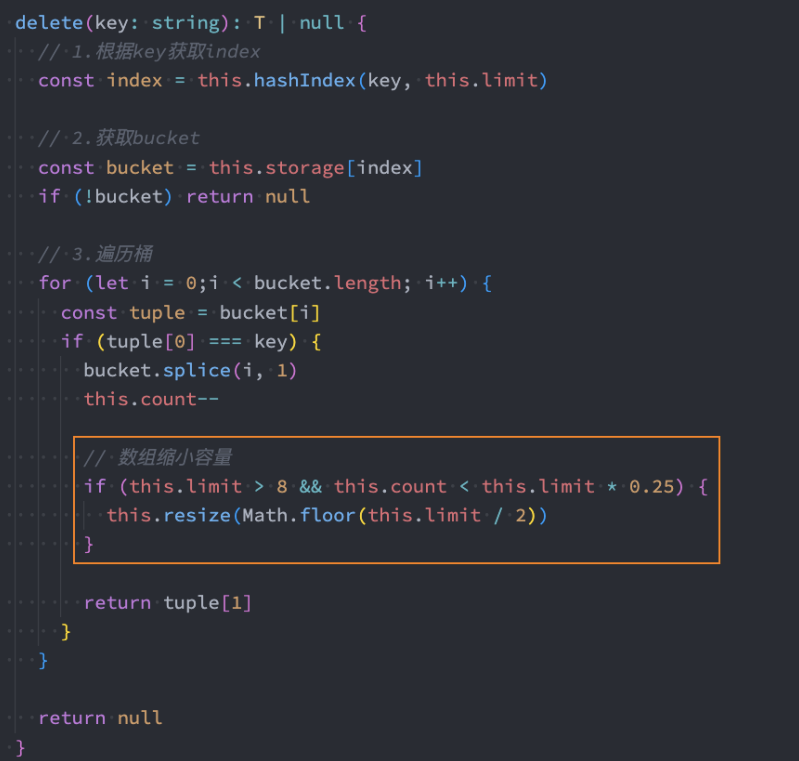
容量质数
我们前面提到过,容量最好是质数。
- 虽然在链地址法中将容量设置为质数,没有在开放地址法中重要,
- 但是其实链地址法中质数作为容量也更利于数据的均匀分布。所以,我们还是完成一下这个步骤。
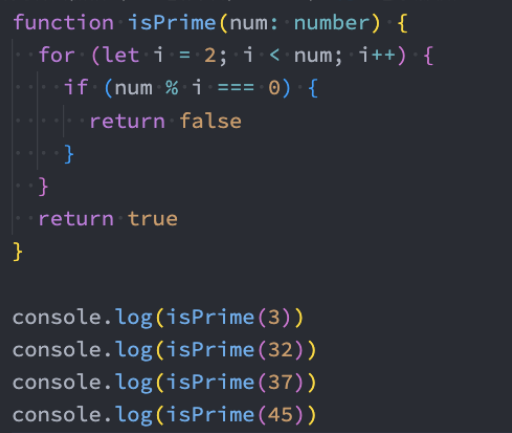
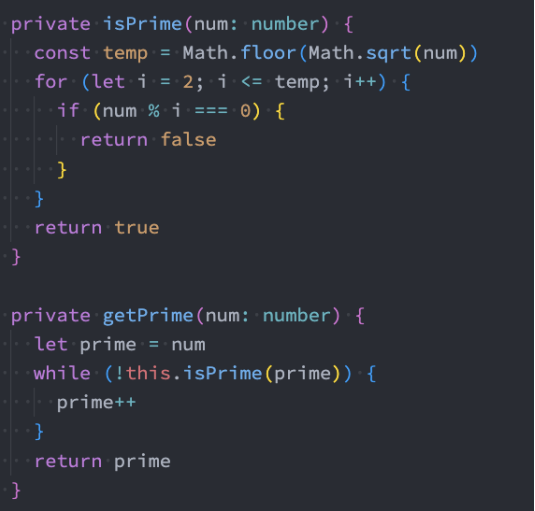
我们这里先讨论一个常见的面试题,判断一个数是质数。
质数的特点:
- 质数也称为素数。
- 质数表示大于1的自然数中,只能被1和自己整除的数。
OK,了解了这个特点,应该不难写出它的算法:
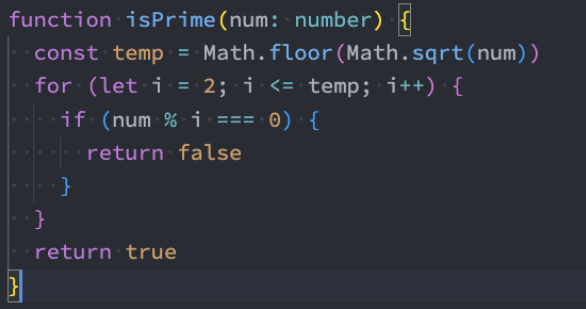
更高效的质数判断
但是,这种做法的效率并不高。为什么呢?
- 对于每个数n,其实并不需要从2判断到n-1
- 一个数若可以进行因数分解,那么分解时得到的两个数一定是一个小于等于sqrt(n),一个大于等于sqrt(n)。
- 注意: sqrt是square root的缩写,表示平方根;
- 比如16可以被分别。那么是28,2小于sqrt(16),也就是4,8大于4。而44都是等于sqrt(n)
- 所以其实我们遍历到等于sqrt(n)即可
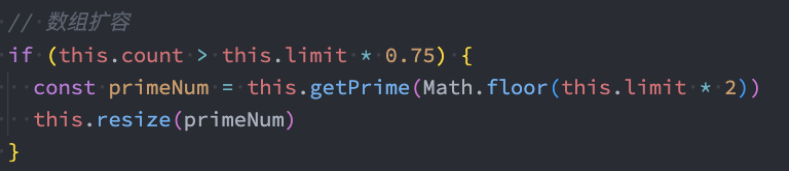
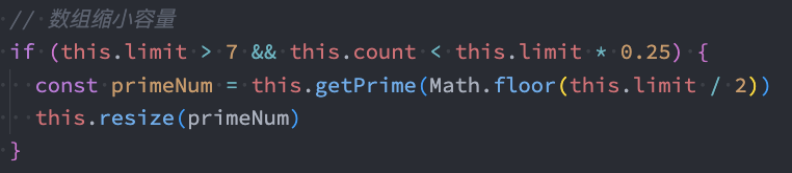
扩容的质数
首先,将初始的limit为8,改成7
前面,我们有对容量进行扩展,方式是:原来的容量 x 2
- 比如之前的容量是7,那么扩容后就是14。14还是一个质数吗?
- 显然不是,所以我们还需要一个方法,来实现一个新的容量为质数的算法。
那么我们可以封装获取新的容量的代码(质数)
树结构(Tree)
什么是树
真实的树:
- 相信每个人对现实生活中的树都会非常熟悉
我们来看一下树有什么特点?
- 树通常有一个根。连接着根的是树干。
- 树干到上面之后会进行分叉成树枝,树枝还会分叉成更小的树枝。
- 在树枝的最后是叶子。
树的抽象:
- 专家们对树的结构进行了抽象,发现树可以模拟生活中的很多场景。

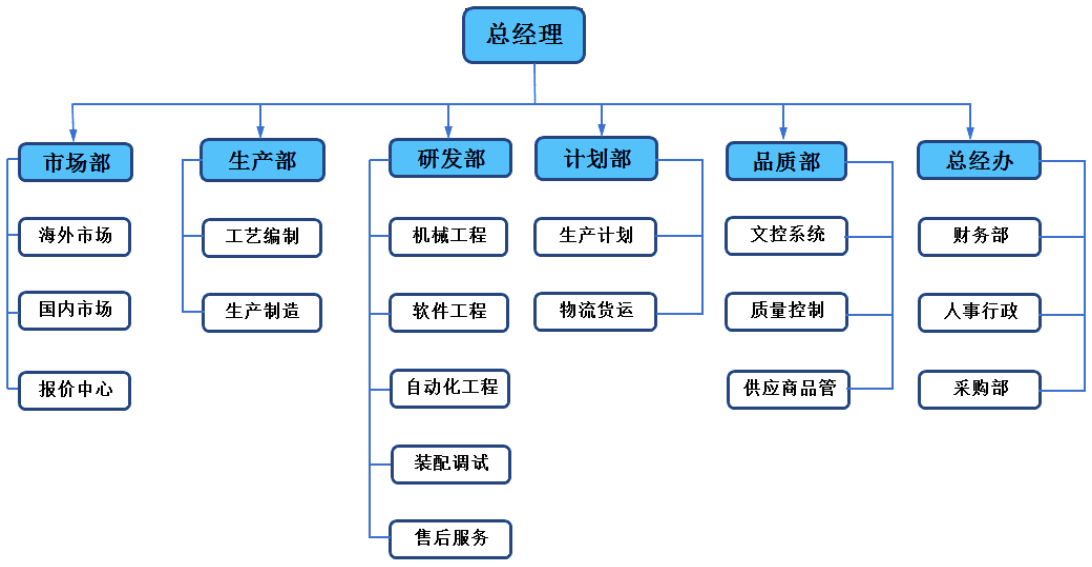
模拟树结构
公司组织架构:
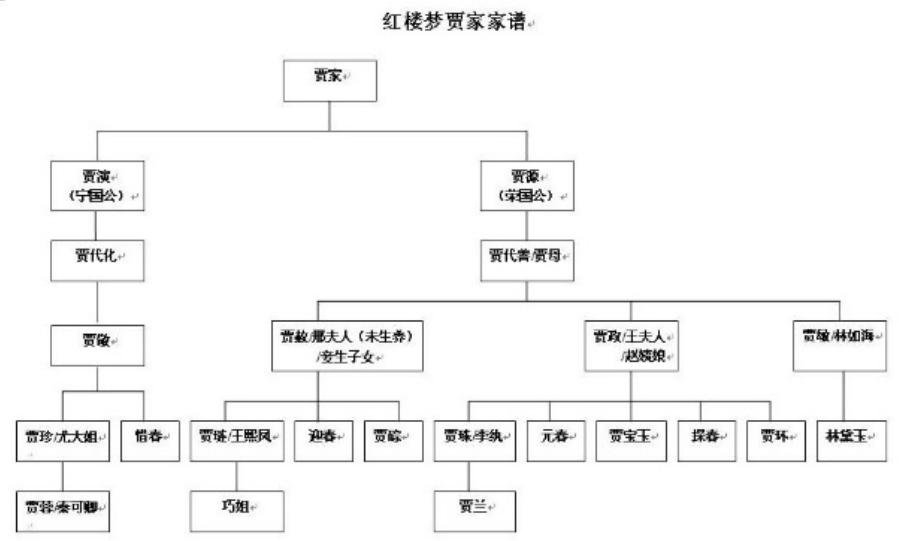
模拟树结构
红楼梦家谱
前端非常熟悉的 DOM Tree
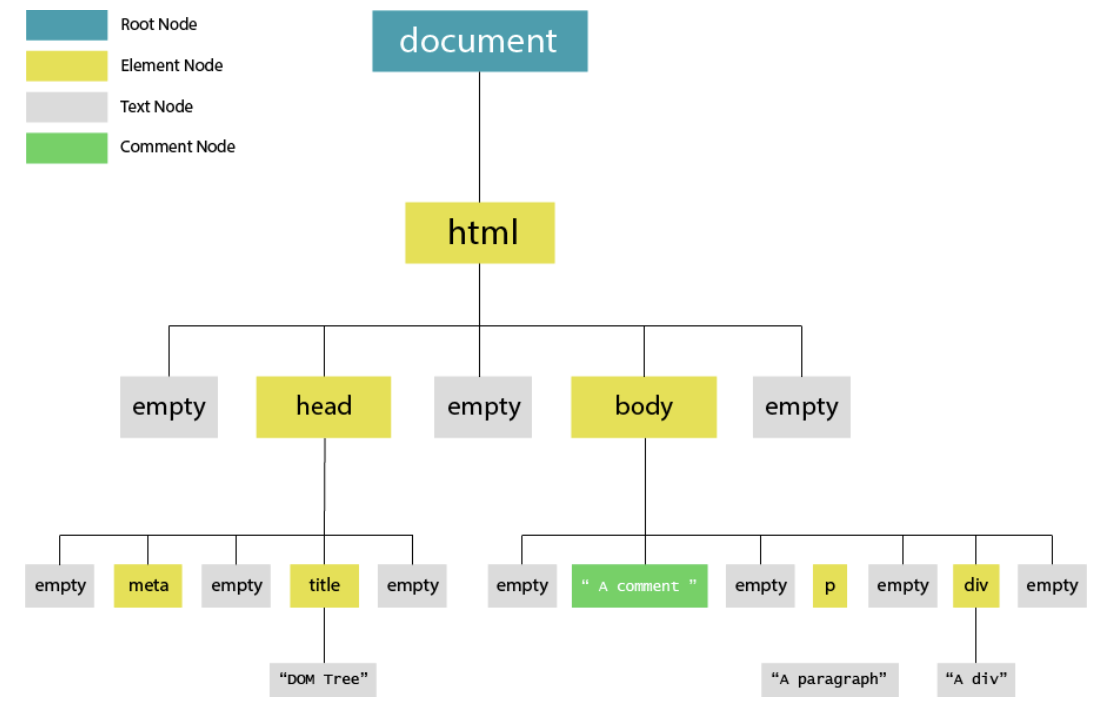
树结构的抽象
我们再将里面的数据移除,仅仅抽象出来结构,那么就是我们要学习的树结构
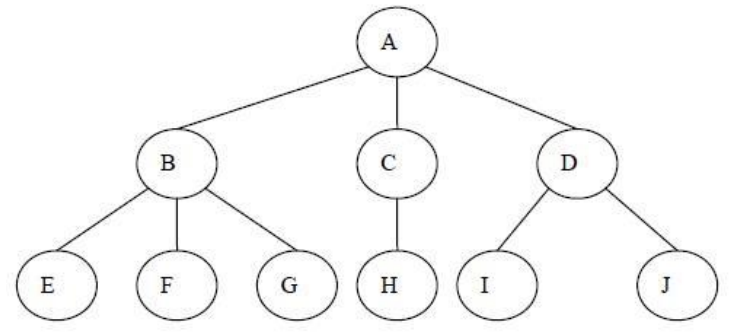
树的优点
我们之前已经学习了多种数据结构来保存数据,为什么要使用树结构来保存数据呢?
树结构和数组/链表/哈希表的对比有什么优点呢? 树的优点
数组:
优点:
- 数组的主要优点是根据下标值访问效率会很高。
- 但是如果我们希望根据元素来查找对应的位置呢?
- 比较好的方式是先对数组进行排序,再进行二分查找。
缺点:
- 需要先对数组进行排序,生成有序数组,才能提高查找效率。
- 另外数组在插入和删除数据时,需要有大量的位移操作(插入到首位或者中间位置的时候),效率很低。
链表:
优点:
- 链表的插入和删除操作效率都很高。
缺点:
- 查找效率很低,需要从头开始依次访问链表中的每个数据项,直到找到。
- 而且即使插入和删除操作效率很高,但是如果要插入和删除中间位置的数据,还是需要重头先找到对应的数据。
树的优点
哈希表:
优点:
- 我们学过哈希表后,已经发现了哈希表的插入/查询/删除效率都是非常高的。
- 但是哈希表也有很多缺点。
缺点:
- 空间利用率不高,底层使用的是数组,并且某些单元是没有被利用的。
- 哈希表中的元素是无序的,不能按照固定的顺序来遍历哈希表中的元素。
- 不能快速的找出哈希表中的最大值或者最小值这些特殊的值。
树结构:
- 我们不能说树结构比其他结构都要好,因为每种数据结构都有自己特定的应用场景。
- 但是树确实也综合了上面的数据结构的优点(当然优点不足于盖过其他数据结构,比如效率一般情况下没有哈希表高)。
- 并且也弥补了上面数据结构的缺点。
而且为了模拟某些场景,我们使用树结构会更加方便。
- 因为数结构的非线性的,可以表示一对多的关系
- 比如文件的目录结构。
树的术语
在描述树的各个部分的时候有很多术语。
- 为了让介绍的内容更容易理解,需要知道一些树的术语。
- 不过大部分术语都与真实世界的树相关,或者和家庭关系相关(如父节点和子节点),所以它们比较容易理解。
树(Tree):n(n≥0)个节点构成的有限集合。
- 当n=0时,称为空树;
对于任一棵非空树(n> 0),它具备以下性质:
- 树中有一个称为“根(Root)”的特殊节点,用 r 表示;
- 其余节点可分为m(m>0)个互不相交的有限集T1,T2,..。,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
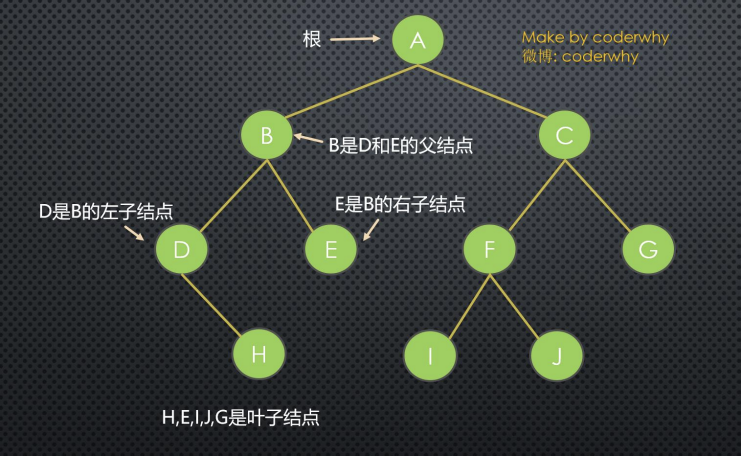
树的术语
树的术语:
1.节点的度(Degree):节点的子树个数。
2.树的度 (Degree) :树的所有节点中最大的度数。
3.叶节点(Leaf):度为0的节点。(也称为叶子节点)
4.父节点(Parent):有子树的节点是其子树的根节点的父节点
5.子节点(Child):若A节点是B节点的父节点,则称B节点是A节点的子节点;子节点也称孩子节点。
6.兄弟节点(Sibling):具有同一父节点的各节点彼此是兄弟节点。
7.路径和路径长度:从节点n1到nk的路径为一个节点序列n1 ,n2,… ,nk
- ni是 n(i+1)的父节点
- 路径所包含 边 的个数为路径的长度。
8.节点的层次(Level):规定根节点在1层,其它任一节点的层数是其父节点的层数加1。
9.树的深度(Depth):对于任意节点n, n的深度为从根到n的唯一路径长,根的深度为0。
10.树的高度(Height):对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0。
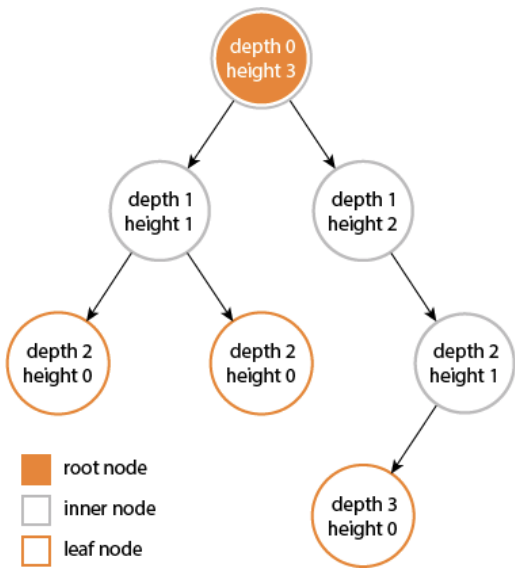
普通的表示方式
最普通的表示方式
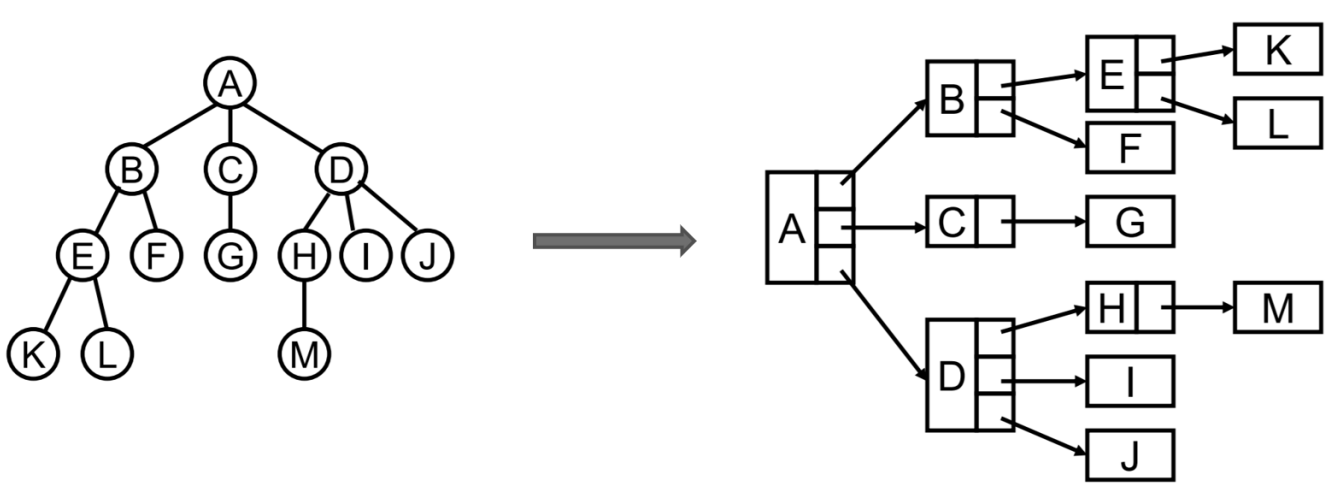
儿子-兄弟表示法
儿子-兄弟表示法
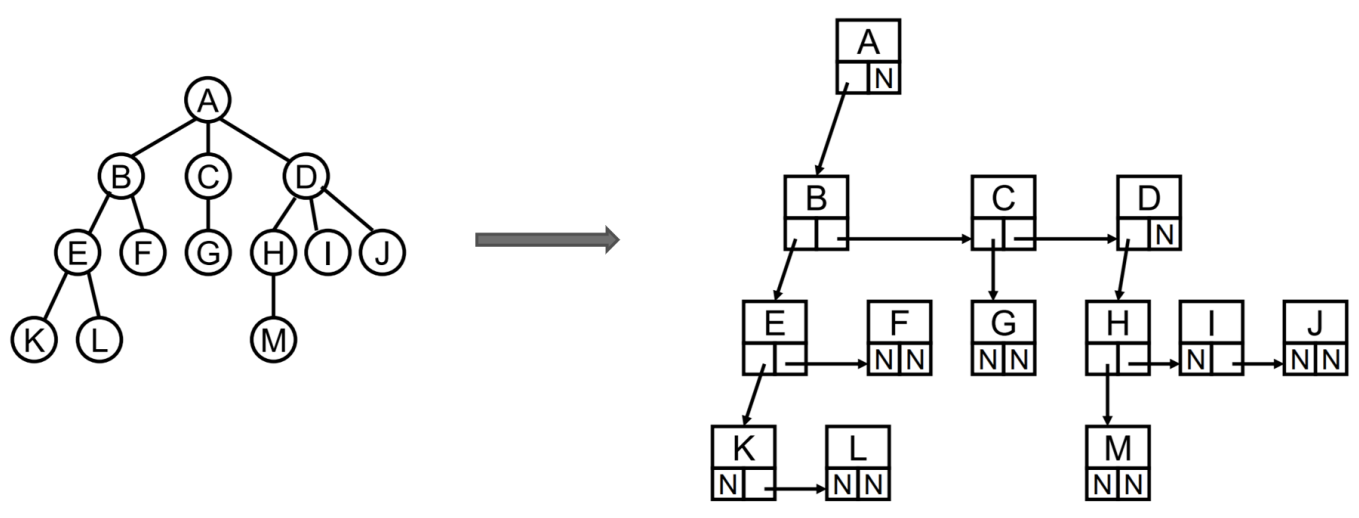
儿子-兄弟表示法旋转
儿子-兄弟表示法旋转
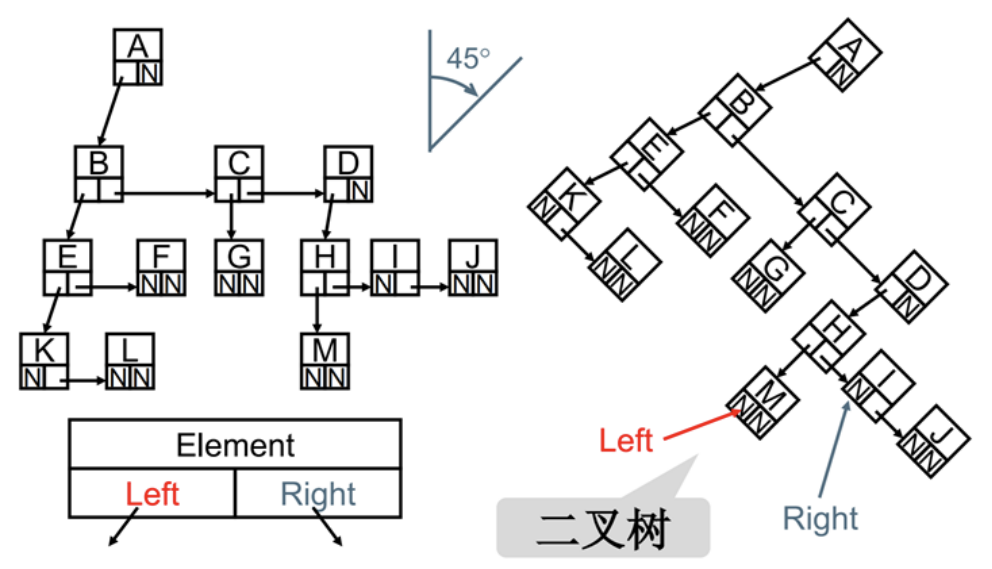
你发现上面规律了吗?
- 其实所有的树本质上都可以使用二叉树模拟出来。
- 所以在学习树的过程中,二叉树非常重要。
二叉树的概念
如果树中每个节点最多只能有两个子节点,这样的树就成为"二叉树"。
- 前面,我们已经提过二叉树的重要性,不仅仅是因为简单,也因为几乎上所有的树都可以表示成二叉树的形式。
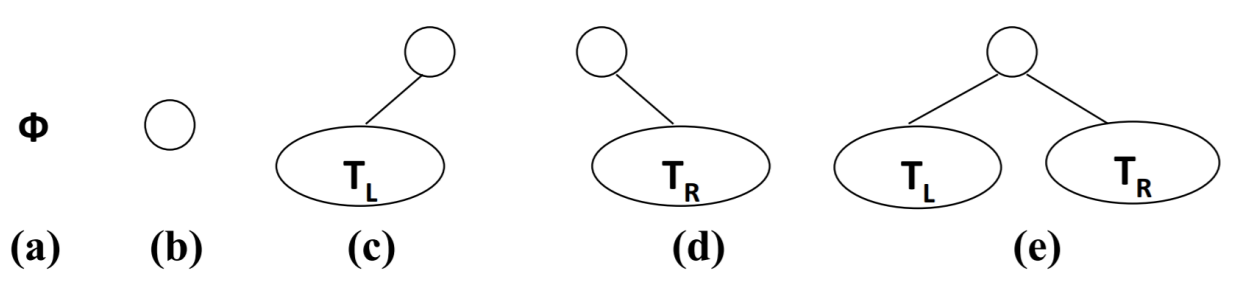
二叉树的定义
- 二叉树可以为空,也就是没有节点。
- 若不为空,则它是由根节点 和 称为其 左子树TL和 右子树TR 的两个不相交的二叉树组成。
二叉树有五种形态:
二叉树的特性
二叉树有几个比较重要的特性,在笔试题中比较常见:
- 一颗二叉树第 i 层的最大节点数为:2^(i-1),i >= 1;
- 深度为k的二叉树有最大节点总数为: 2^k - 1,k >= 1;
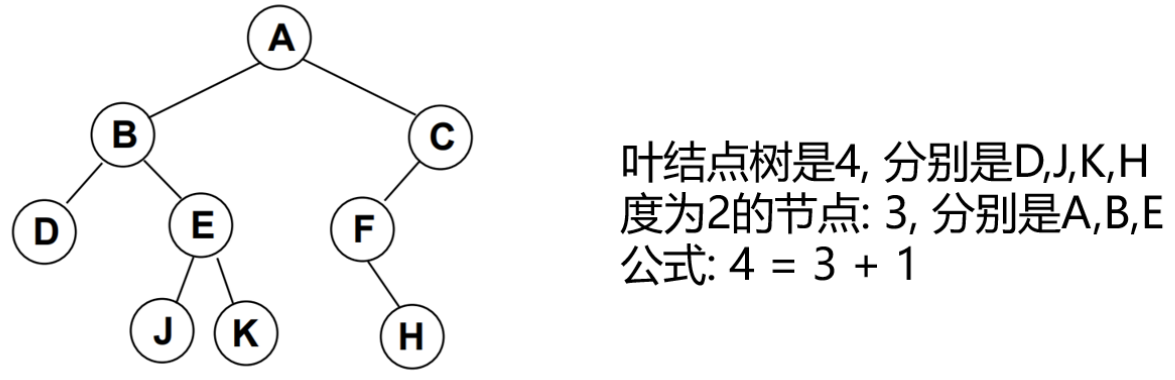
- 对任何非空二叉树 T,若n0表示叶节点的个数、n2是度为2的非叶节点个数,那么两者满足关系n0 = n2 + 1。
完美二叉树
完美二叉树(Perfect Binary Tree) ,也称为满二叉树(Full Binary Tree)
- 在二叉树中,除了最下一层的叶节点外,每层节点都有2个子节点,就构成了满二叉树。
完全二叉树
完全二叉树(Complete Binary Tree)
- 除二叉树最后一层外,其他各层的节点数都达到最大个数。
- 且最后一层从左向右的叶节点连续存在,只缺右侧若干节点。
- 完美二叉树是特殊的完全二叉树。
下面不是完全二叉树,因为D节点还没有右节点,但是E节点就有了左右节点。
二叉树的存储
二叉树的存储常见的方式是数组和链表。
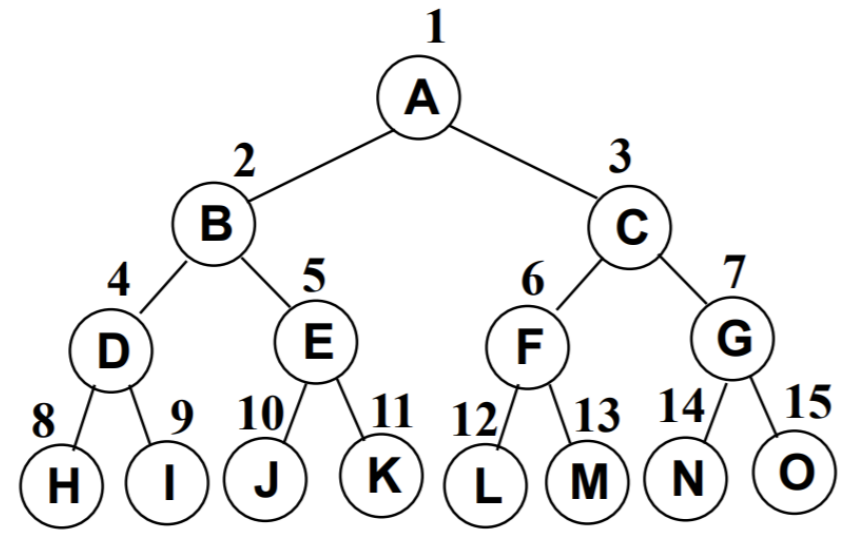
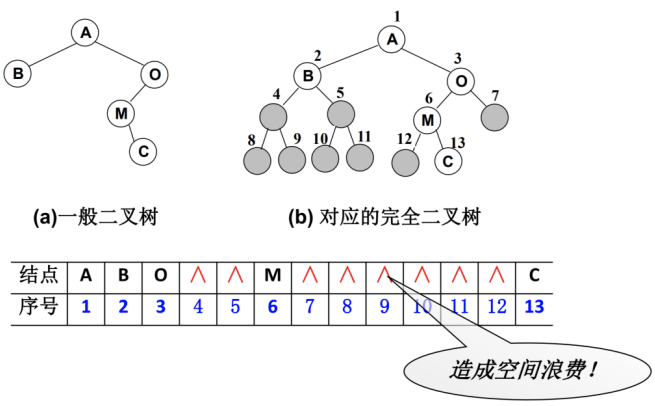
使用数组
- 完全二叉树:按从上至下、从左到右顺序存储
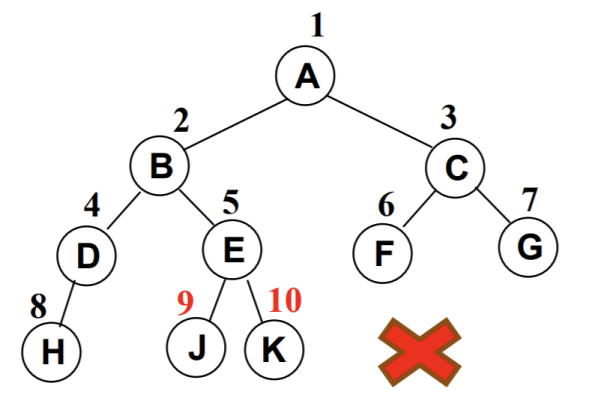
非完全二叉树:
- 非完全二叉树要转成完全二叉树才可以按照上面的方案存储。
- 但是会造成很大的空间浪费
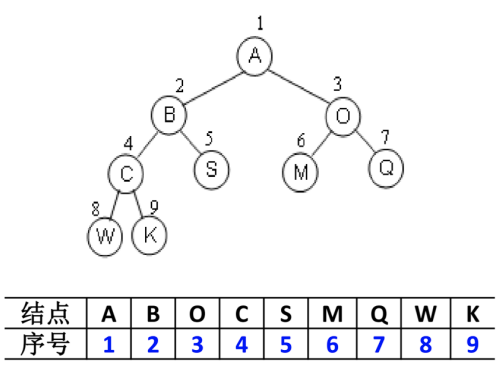
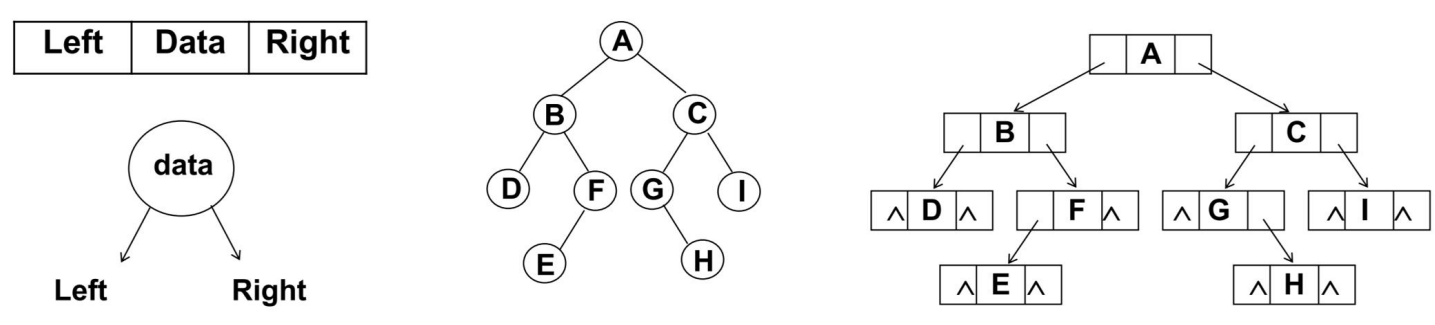
链表存储
二叉树最常见的方式还是使用链表存储。
- 每个节点封装成一个Node,Node中包含存储的数据,左节点的引用,右节点的引用。
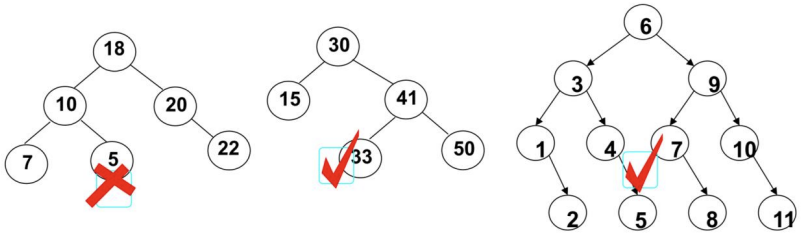
什么是二叉搜索树
二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树
二叉搜索树是一颗二叉树,可以为空;
如果不为空,满足以下性质:
- 非空左子树的所有键值小于其根节点的键值。
- 非空右子树的所有键值大于其根节点的键值。
- 左、右子树本身也都是二叉搜索树。
下面哪些是二叉搜索树,哪些不是?
二叉搜索树的特点:
- 二叉搜索树的特点就是相对较小的值总是保存在左节点上,相对较大的值总是保存在右节点上。
- 那么利用这个特点,我们可以做什么事情呢?
- 查找效率非常高,这也是二叉搜索树中,搜索的来源。
二叉搜索树
下面是一个二叉搜索树
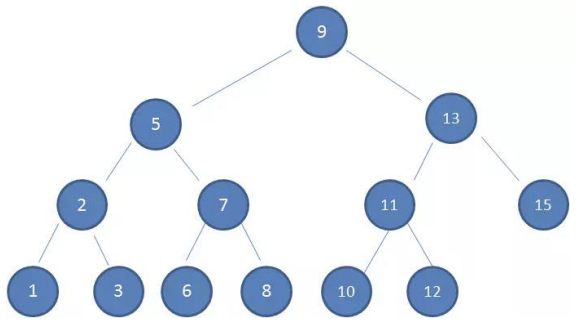
这样的数据结构有什么好处呢?
- 我们试着查找一下值为10的节点
这种方式就是二分查找的思想
- 查找所需的最大次数等于二叉搜索树的深度;
- 插入节点时,也利用类似的方法,一层层比较大小,找到新节点合适的位置。
二叉搜索树的封装
我们像封装其他数据结构一样,先来封装一个BSTree的类
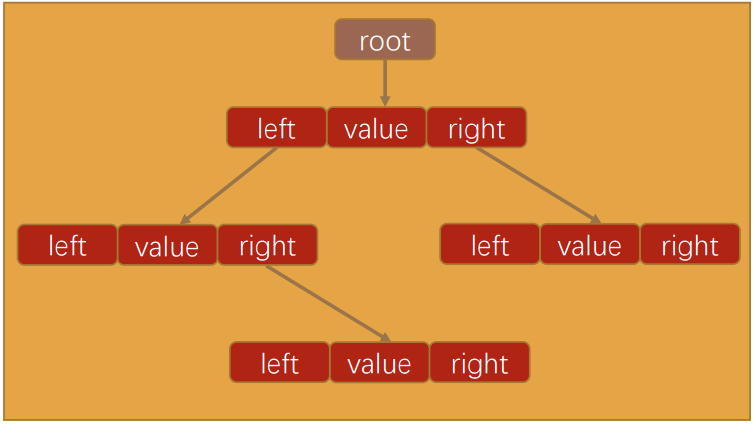
代码解析:
- 封装BSTree的类;
- 还需要封装一个用于保存每一个节点的类Node。
- 该类包含三个属性:节点对应的value,指向的左子树left,指向的右子树right
- 对于BSTree来说,只需要保存根节点即可,因为其他节点都可以通过根节点找到。


二叉搜索树常见操作
二叉搜索树有哪些常见的操作呢?
插入操作:
- insert(value):向树中插入一个新的数据。
查找操作:
- search(value):在树中查找一个数据,如果节点存在,则返回true;如果不存在,则返回false。
- min:返回树中最小的值/数据。
- max:返回树中最大的值/数据。
遍历操作:
- inOrderTraverse:通过中序遍历方式遍历所有节点。
- preOrderTraverse:通过先序遍历方式遍历所有节点。
- postOrderTraverse:通过后序遍历方式遍历所有节点。
- levelOrderTraverse:通过层序遍历方式遍历所有节点。
删除操作(有一点点复杂):
- remove(value):从树中移除某个数据。
向树中插入数据
我们分两个部分来完成这个功能。
首先,外界调用的insert方法:
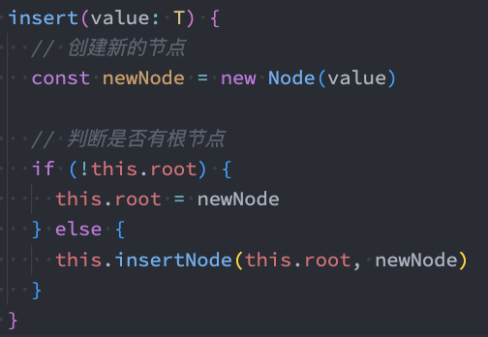
代码解析:
首先,根据传入的value,创建对应的Node。
其次,向树中插入数据需要分成两种情况:
- 第一次插入,直接修改根节点即可。
- 其他次插入,需要进行相关的比较决定插入的位置。
在代码中的insertNode方法,我们还没有实现,也是我们接下来要完成的任务。
向树中插入数据
其次,插入非根节点

代码解析:
插入其他节点时,我们需要判断该值到底是插入到左边还是插入到右边。
判断的依据来自于新节点的value和原来节点的value值的比较。
- 如果新节点的newvalue小于原节点的oldvalue,那么就向左边插入。
- 如果新节点的newvalue大于原节点的oldvalue,那么就向右边插入。
代码的1序号位置,就是准备向左子树插入数据。但是它本身又分成两种情况
- 情况一(代码1.1位置):左子树上原来没有内容,那么直接插入即可。
- 情况二(代码1.2位置):左子树上已经有了内容,那么就一次向下继续查找 新的走向,所以使用递归调用即可。
代码的2序号位置,和1序号位置几乎逻辑是相同的,只是是向右去查找。
- 情况一(代码2.1位置):左右树上原来没有内容,那么直接插入即可。
- 情况二(代码2.2位置):右子树上已经有了内容,那么就一次向下继续查找 新的走向,所以使用递归调用即可。
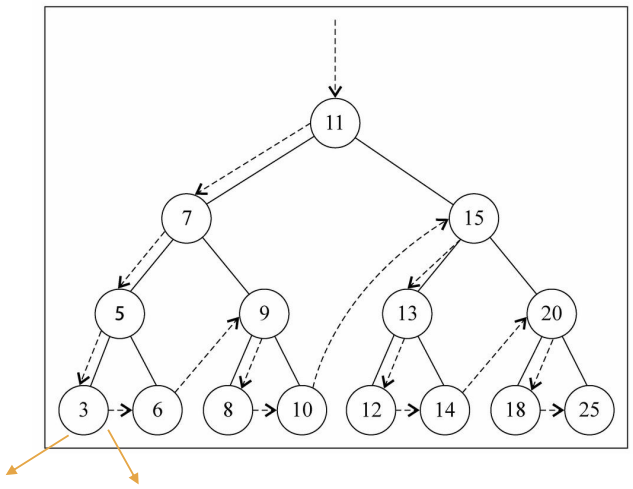
测试插入代码
// 插入数据
bst.insert(11)
bst.insert(7)
bst.insert(15)
bst.insert(5)
bst.insert(3)
bst.insert(9)
bst.insert(8)
bst.insert(10)
bst.insert(13)
bst.insert(12)
bst.insert(14)
bst.insert(20)
bst.insert(18)
bst.insert(25)
Bst.insert(6)
遍历二叉搜索树
前面,我们向树中插入了很多的数据,为了能很多的看到测试结果。我们先来学习一下树的遍历。
- 注意:这里我们学习的树的遍历,针对所有的二叉树都是适用的,不仅仅是二叉搜索树。
树的遍历:
- 遍历一棵树是指访问树的每个节点(也可以对每个节点进行某些操作,我们这里就是简单的打印)
- 但是树和线性结构不太一样,线性结构我们通常按照从前到后的顺序遍历,但是树呢?
- 应该从树的顶端还是底端开始呢? 从左开始还是从右开始呢?
二叉树的遍历常见的有四种方式:
- 先序遍历
- 中序遍历
- 后序遍历。
- 层序遍历
先序遍历
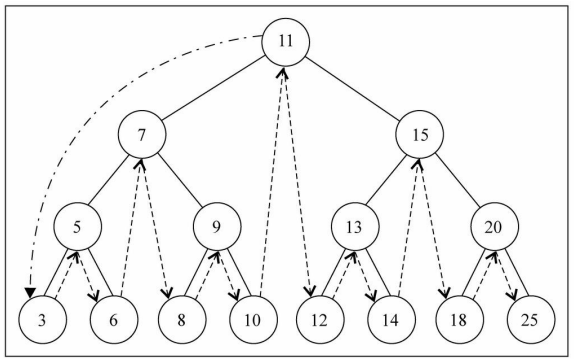
遍历过程为:
- ①访问根节点;
- ②先序遍历其左子树;
- ③先序遍历其右子树。
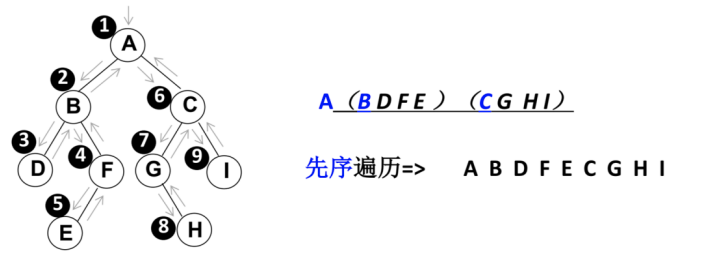

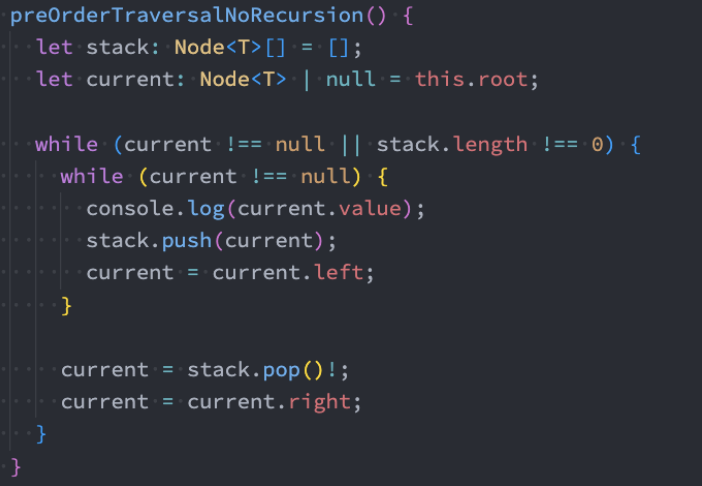
先序遍历(非递归 – 课下扩展)
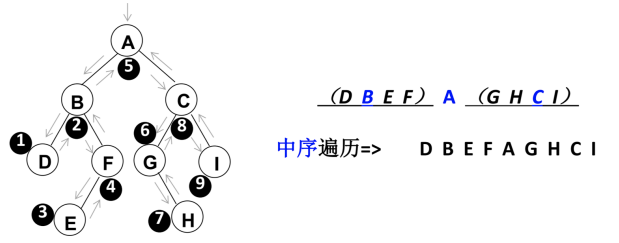
中序遍历
遍历过程为:
- ①中序遍历其左子树;
- ②访问根节点;
- ③中序遍历其右子树。

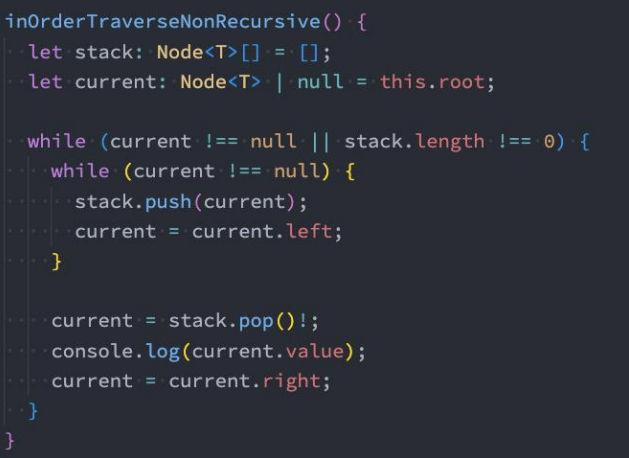
中序遍历(非递归 – 课下扩展)
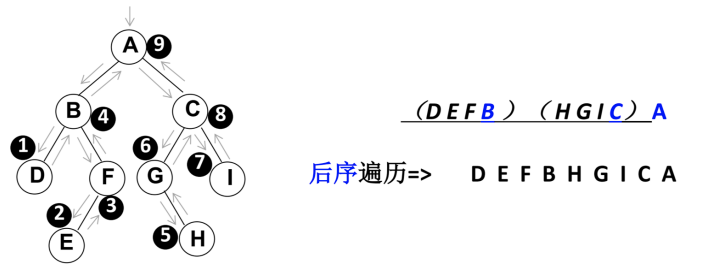
后序遍历
遍历过程为:
- ①后序遍历其左子树;
- ②后序遍历其右子树;
- ③访问根节点。
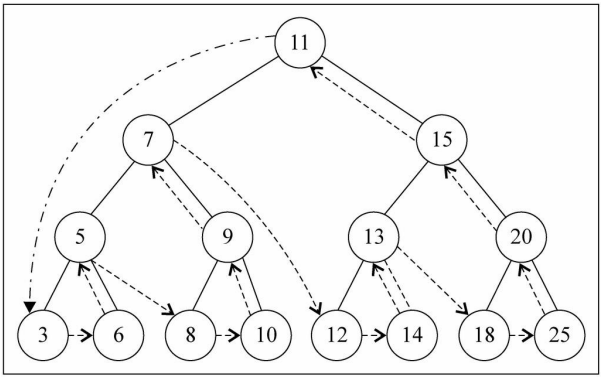

后序遍历(非递归 – 课下扩展)
层序遍历
遍历过程为:
- 层序遍历很好理解,就是从上向下逐层遍历。
- 层序遍历通常我们会借助于队列来完成;
- 也是队列的一个经典应用场景;
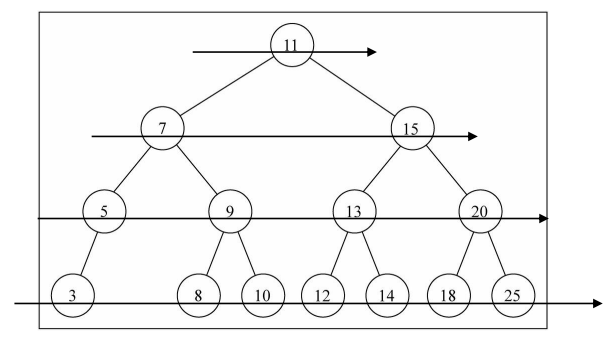

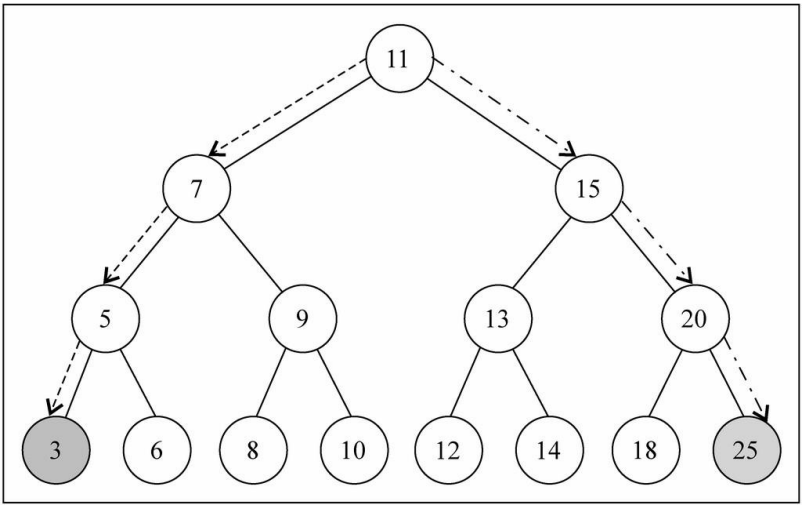
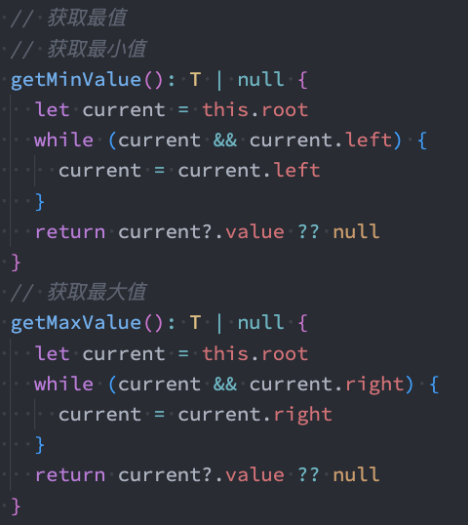
最大值 & 最小值
在二叉搜索树中搜索最值是一件非常简单的事情,其实用眼睛看就可以看出来了。
search搜索特定的值
二叉搜索树不仅仅获取最值效率非常高,搜索特定的值效率也非常高。
- 注意:这里的实现返回boolean类型即可。
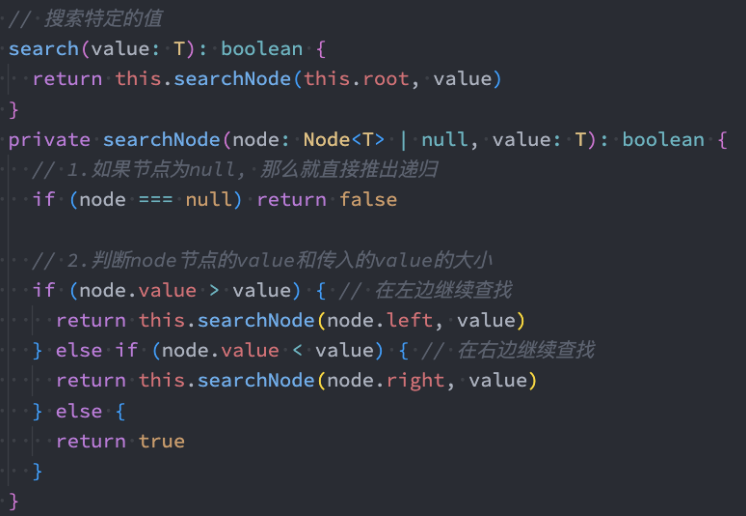
代码解析:
这里我们还是使用了递归的方式。
递归必须有退出条件,我们这里是两种情况下退出。
node === null,也就是后面不再有节点的时候。
找到对应的value,也就是node.value === value的时候。
在其他情况下,根据node.的value和传入的value进行比较来决定向左还是 向右查找。
如果node.value > value,那么说明传入的值更小,需要向左查找。
如果node.value < value,那么说明传入的值更大,需要向右查找。
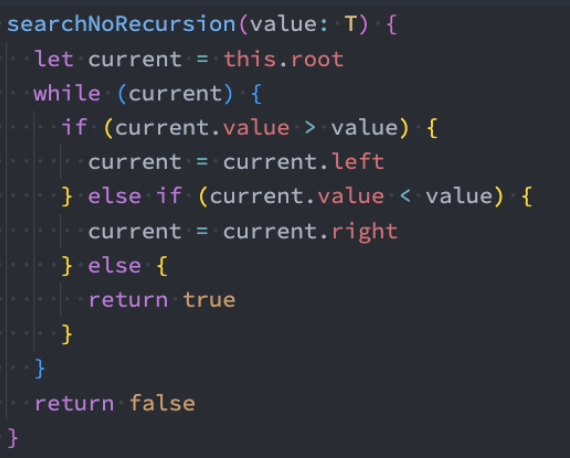
search搜索特定的值(非递归)
二叉搜索树的删除
二叉搜索树的删除有些复杂,我们一点点完成。
删除节点要从查找要删的节点开始,找到节点后,需要考虑三种 情况:
- 该节点是叶节点(没有字节点,比较简单)
- 该节点有一个子节点(也相对简单)
- 该节点有两个子节点.(情况比较复杂,我们后面慢慢道来)
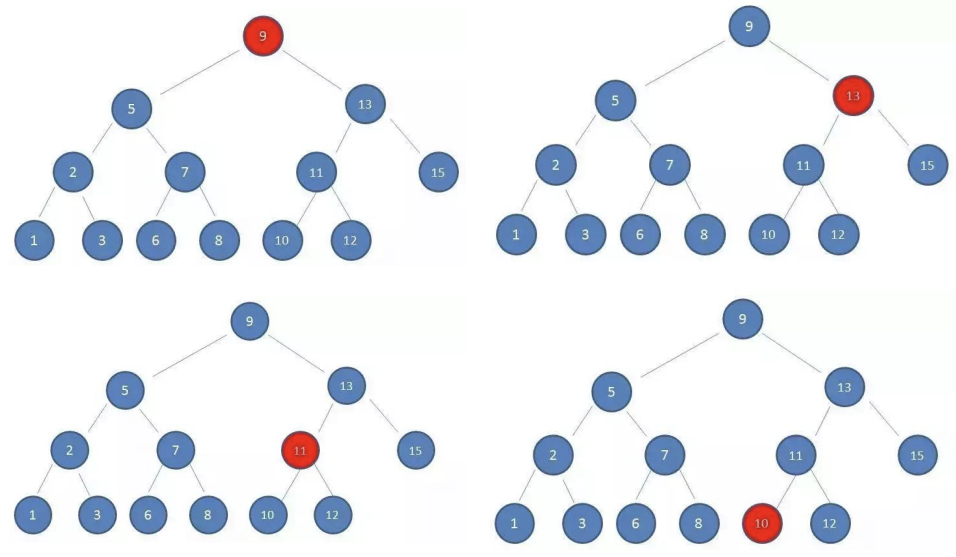
我们先从查找要删除的节点入手
1> 先找到要删除的节点,如果没有找到,不需要删除
2> 找到要删除节点
- 删除叶子节点
- 删除只有一个子节点的节点
- 删除有两个子节点的节点

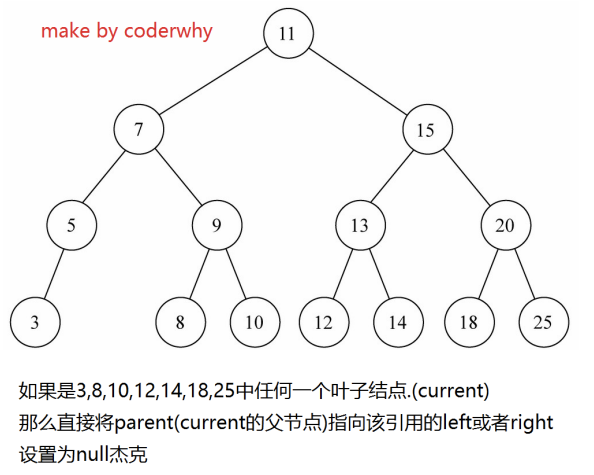
情况一:没有子节点
情况一:没有子节点.
- 这种情况相对比较简单,我们需要检测current的left以及right是否都为null.
- 都为null之后还要检测一个东西,就是是否current就是根,都为null,并且为跟根,那么相当于要清空二叉树(当然,只是清 空了根,因为只有它).
- 否则就把父节点的left或者right字段设置为null即可.
如果只有一个单独的根,直接删除即可
如果是叶节点,那么处理方式如下:
情况二:一个子节点
情况二:有一个子节点
- 这种情况也不是很难.
- 要删除的current节点,只有2个连接(如果有两个子节点, 就是三个连接了),一个连接父节点,一个连接唯一的子节 点.
- 需要从这三者之间:爷爷 - 自己 - 儿子,将自己(current) 剪短,让爷爷直接连接儿子即可.
- 这个过程要求改变父节点的left或者right,指向要删除节点 的子节点.
- 当然,在这个过程中还要考虑是否current就是根.
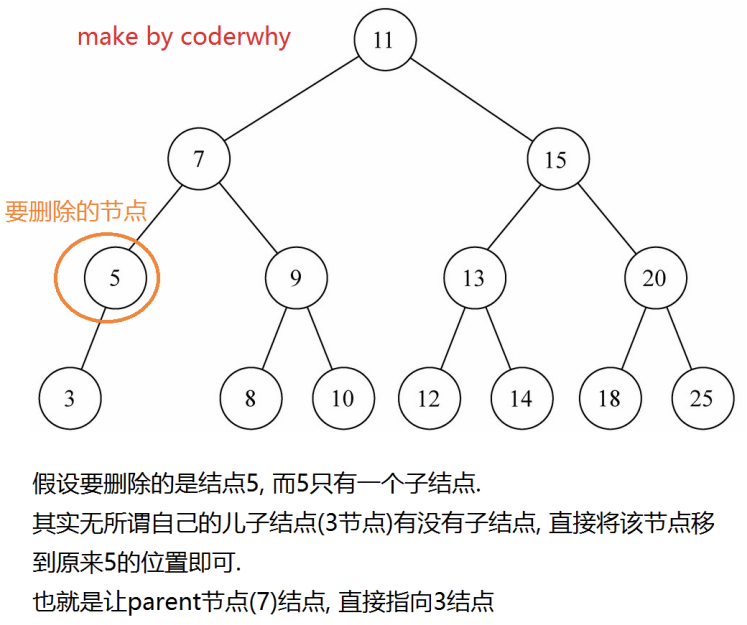
图解过程:
- 如果是根的情况,大家可以自己画一下,比较简单,这里 不再给出.
- 如果不是根,并且只有一个子节点的情况.
情况三:两个子节点
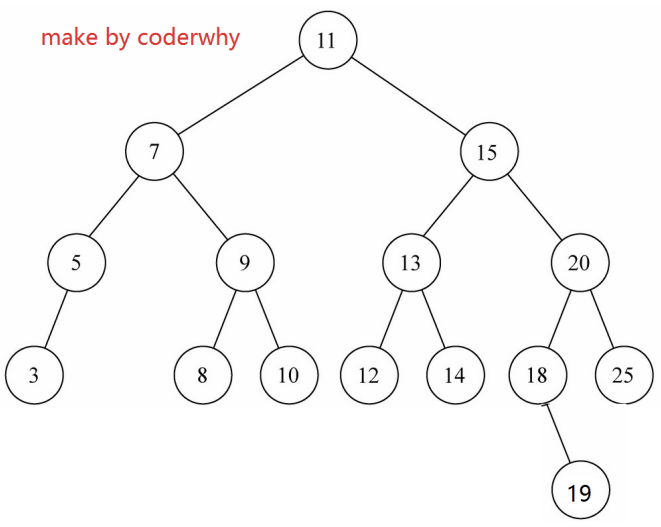

寻找规律
如果我们要删除的节点有两个子节点,甚至子节点还有子节点,这种情况下我们需要从下面的子节点中找到一个节点,来替换当前的节点.
但是找到的这个节点有什么特征呢? 应该是current节点下面所有节点中最接近current节点的.
- 要么比current节点小一点点,要么比current节点大一点点。
- 总结你最接近current,你就可以用来替换current的位置.
这个节点怎么找呢?
- 比current小一点点的节点,一定是current左子树的最大值。
- 比current大一点点的节点,一定是current右子树的最小值。
前驱&后继
- 在二叉搜索树中,这两个特别的节点,有两个特别的名字。
- 比current小一点点的节点,称为current节点的前驱。
- 比current大一点点的节点,称为current节点的后继。
也就是为了能够删除有两个子节点的current,要么找到它的前驱,要么找到它的后继。
所以,接下来,我们先找到这样的节点(前驱或者后继都可以,我这里以找后继为例)

删除操作总结
看到这里,你就会发现删除节点相当棘手。
实际上,因为它非常复杂,一些程序员都尝试着避开删除操作。
- 他们的做法是在Node类中添加一个boolean的字段,比如名称为isDeleted。
- 要删除一个节点时,就将此字段设置为true。
- 其他操作,比如find()在查找之前先判断这个节点是不是标记为删除。
- 这样相对比较简单,每次删除节点不会改变原有的树结构。
- 但是在二叉树的存储中,还保留着那些本该已经被删除掉的节点。
上面的做法看起来很聪明,其实是一种逃避。
- 这样会造成很大空间的浪费,特别是针对数据量较大的情况。
- 而且,作为程序员要学会通过这些复杂的操作,锻炼自己的逻辑。
二叉搜索树的缺陷
二叉搜索树作为数据存储的结构由重要的优势:
- 可以快速地找到给定关键字的数据项 并且可以快速地插入和删除数据项。
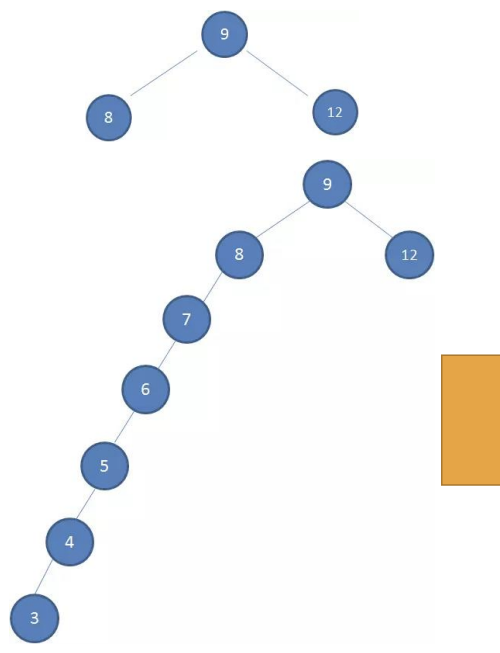
但是,二叉搜索树有一个很麻烦的问题:
- 如果插入的数据时有序的数据,比如下面的情况
- 有一棵初始化为 9 8 12 的二叉树
- 插入下面的数据:7 6 5 4 3
非平衡树:
- 比较好的二叉搜索树数据应该是左右分布均匀的
- 但是插入连续数据后,分布的不均匀,我称这种树为非平衡树。
- 对于一棵平衡二叉树来说,插入/查找等操作的效率是O(logN)
- 对于一棵非平衡二叉树,相当于编写了一个链表,查找效率变成了O(N)
树的平衡性
为了能以较快的时间O(logN)来操作一棵树,我们需要保证树总是平衡的:
- 至少大部分是平衡的,那么时间复杂度也是接近O(logN)的
- 也就是说树中每个节点左边的子孙节点的个数,应该尽可能的等于右边的子孙节点的个数。
- 常见的平衡树有哪些呢?
AVL树:
- AVL树是最早的一种平衡树。它有些办法保持树的平衡(每个节点多存储了一个额外的数据)
- 因为AVL树是平衡的,所以时间复杂度也是O(logN)。
- 但是,每次插入/删除操作相对于红黑树效率都不高,所以整体效率不如红黑树
红黑树:
- 红黑树也通过一些特性来保持树的平衡。
- 因为是平衡树,所以时间复杂度也是在O(logN)。
- 另外插入/删除等操作,红黑树的性能要优于AVL树,所以现在平衡树的应用基本都是红黑树。
图结构(Graph)
什么是图
在计算机程序设计中,图结构 也是一种非常常见的数据结构。
- 但是,图论其实是一个非常大的话题
- 我们通过本章的学习来认识一下关于图的一些内容 - 图的抽象数据类型 – 一些算法实现。
什么是图?
- 图结构是一种与树结构有些相似的数据结构。
- 图论是数学的一个分支,并且,在数学的概念上,树是图的一种。
- 它以图为研究对象,研究 顶点 和 边 组成的图形的数学理论和方法。
- 主要研究的目的是事物之间的关系,顶点代表事物,边代表两个事物间的关系
我们知道树可以用来模拟很多现实的数据结构
- 比如: 家谱/公司组织架构等等
- 那么图长什么样子?
- 或者什么样的数据使用图来模拟更合适呢?
图的现实案例
人与人之间的关系网。
- 甚至科学家们在观察人与人之间的关系网时,还发现了六度空间理论。
六度空间理论
- 理论上认为世界上任何两个互相不认识的两人。
- 只需要很少的中间人就可以建立起联系。
- 并非一定要经过6步,只是需要很少的步骤。
图的实现案例
北京地铁图
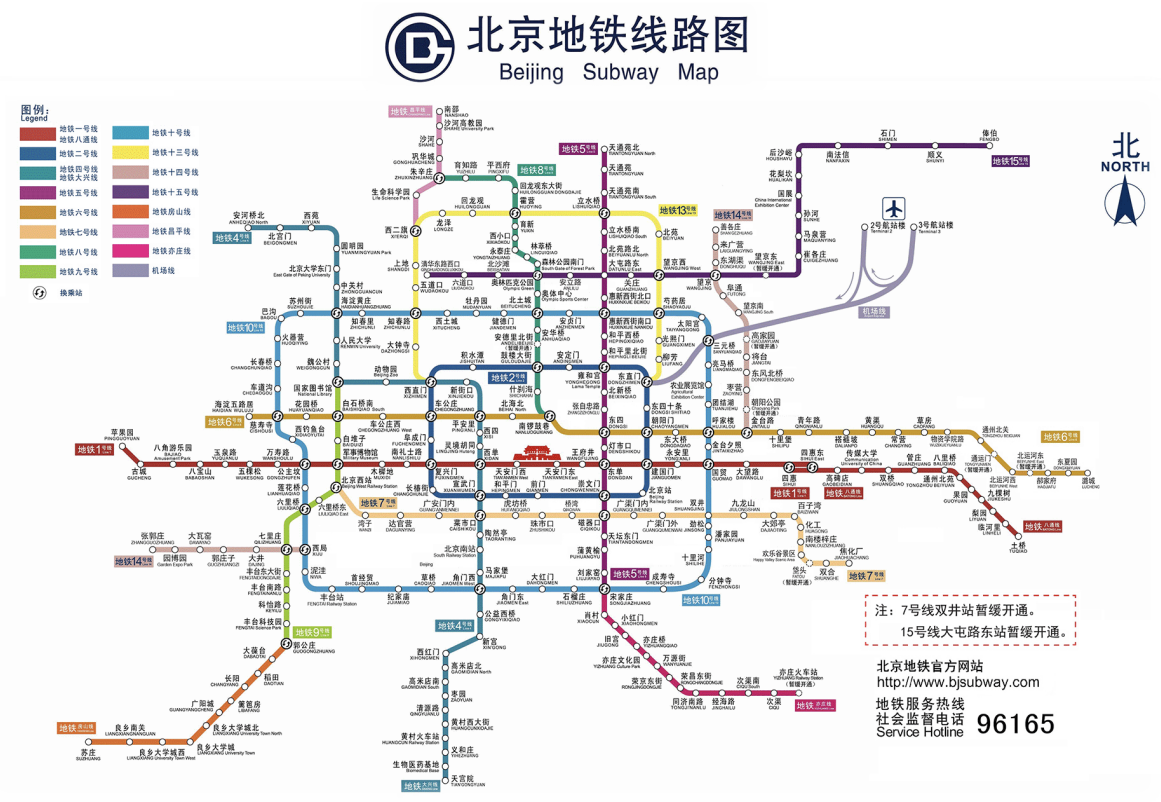
图的现实案例
村庄间的关系网
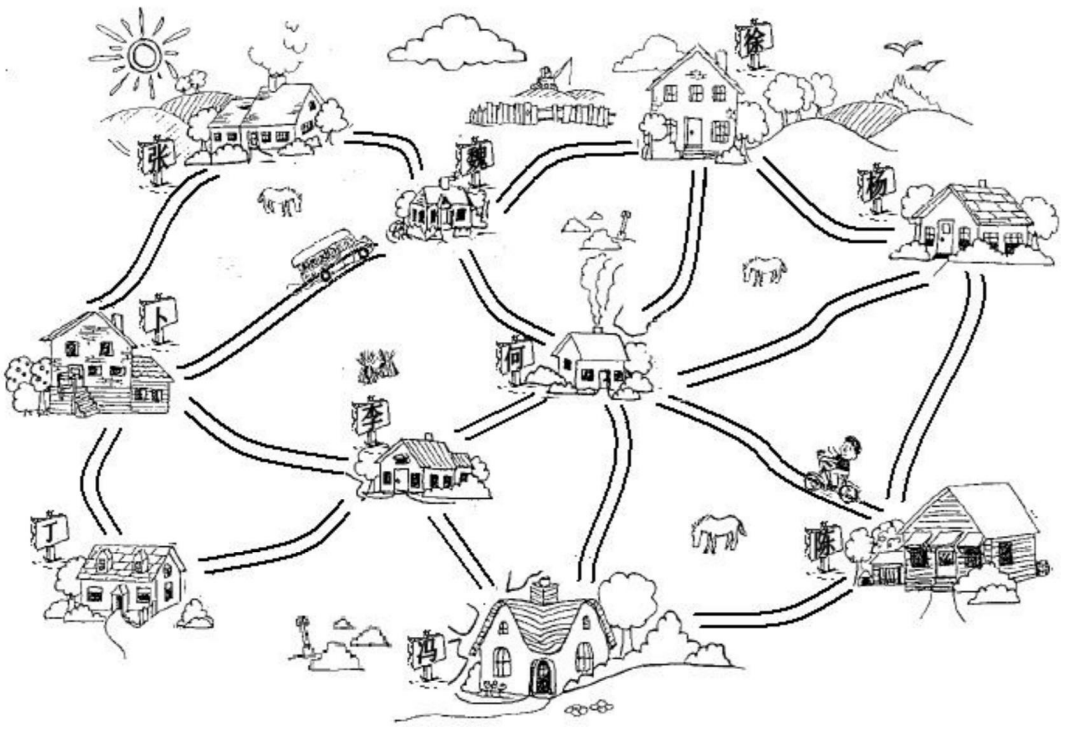
再次 什么是图
那么,什么是图呢?
- 我们会发现,上面的节点(其实图中叫顶点Vertex)之间的关系,是不能使用树来表示
- 使用任何的树结构都不可以模拟。
- 这个时候,我们就可以使用图来模拟它们。
图通常有什么特点呢?
- 一组顶点:通常用 V (Vertex) 表示顶点的集合
- 一组边:通常用 E (Edge) 表示边的集合
- 边是顶点和顶点之间的连线
- 边可以是有向的,也可以是无向的。
- 比如A --- B,通常表示无向。 A --> B,通常表示有向
历史故事
18世纪著名古典数学问题之一。
- 在哥尼斯堡的一个公园里,有七座桥将普雷格尔河中两个岛及岛与河岸连接起来(如图)。
- 有人提出问题: 一个人怎样才能不重复、不遗漏地一次走完七座桥,最后回到出发点。
1735年,有几名大学生写信给当时正在俄罗斯的彼得斯堡科学院任职的瑞典天才数学家欧拉,请他帮忙解决这一问题。
- 欧拉在亲自观察了哥伦斯堡的七桥后,认真思考走法,但是始终没有成功,于是他怀疑七桥问题是不是无解的。
- 1736年29岁的欧拉向 彼得斯堡 科学院递交了《哥尼斯堡的七座桥》的论文,在解答问题的同时,开创了数学的一个新的分支——图论与几何拓扑,也由此展开了数学史上的新历程。
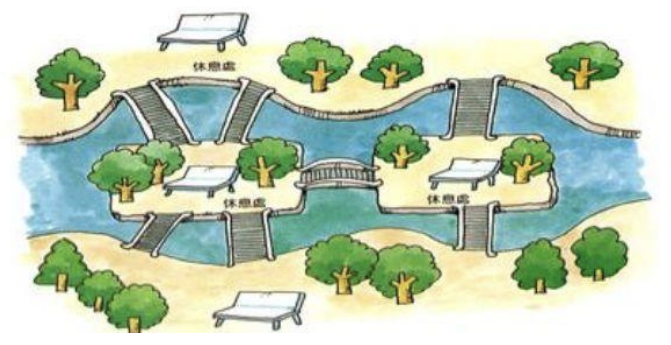
欧拉解答
他不仅解决了该问题,并且给出了 连通图 可以一笔画的充要条件是:
- 奇点的数目不是0个就是2 个
- 连到一点的边的数目如果是奇数条,就称为奇点
- 如果是偶数条就称为偶点
- 要想一笔画成,必须中间点均是偶点
- 也就是有来路必有另一条去路,奇点只可能在两端,因此任何图能 一笔画成,奇点要么没有要么在两端
个人思考:
- 欧拉在思考这个问题的时候,并不是针对某一个特性的问题去考虑, 而是将岛和桥抽象成了点和线。
- 抽象是数学的本质,而编程我们也一再强调抽象的重要性。
- 汇编语言是对机器语言的抽象,高级语言是对汇编语言的抽象。
- 操作系统是对硬件的抽象,应用程序在操作系统的基础上构建。
图的术语
关于术语的概述
- 我们在学习树的时候,树有很多的相关术语。
- 了解这些术语有助于我们更好的理解树结构。
我们也来学习一下图相关的术语。
- 但是图的术语其实非常多,如果你找一本专门讲图的各个方面的书籍,会发现 只是术语 就可以 占据满满的一个章节。
- 这里,我们先介绍几个比较常见的术语,某些术语后面用到的时候,再了解。
- 没有用到的,在自行深入学习的过程中,可以通过查资料去了解。
我们先来看一个抽象出来的图
- 用数字更容易我们从整体来观察整个图结构。
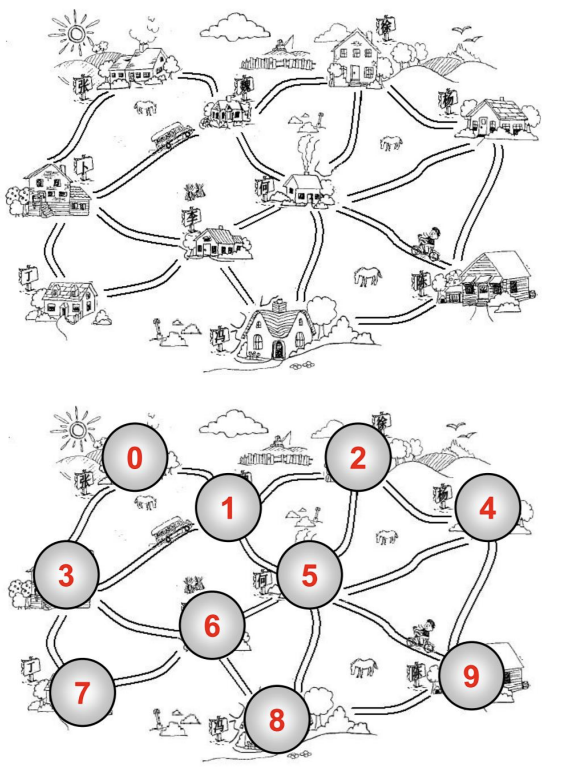
顶点:
- 顶点刚才我们已经介绍过了,表示图中的一个节点。
- 比如地铁站中某个站/多个村庄中的某个村庄/互联网中的某台主机/人际关系中的人。
边:
- 边刚才我们也介绍过了,表示顶点和顶点之间的连线。
- 比如地铁站中两个站点之间的直接连线,就是一个边。
- 注意: 这里的边不要叫做路径,路径有其他的概念,待会儿我们会介绍到。
- 之前的图中: 0 - 1有一条边,1 - 2有一条边,0 - 2没有边。
相邻顶点:
- 由一条边连接在一起的顶点称为相邻顶点。
- 比如0 - 1是相邻的,0 - 3是相邻的。 0 - 2是不相邻的。
度:
- 一个顶点的度是相邻顶点的数量。
- 比如0顶点和其他两个顶点相连,0顶点的度是2
- 比如1顶点和其他四个顶点相连,1顶点的度是4
路径:
- 路径是顶点v1,v2...,vn的一个连续序列,比如上图中0 1 5 9就是一条路径。
- 简单路径: 简单路径要求不包含重复的顶点。 比如 0 1 5 9是一条简单路径。
- 回路: 第一个顶点和最后一个顶点相同的路径称为回路。 比如 0 1 5 6 3 0
无向图:
- 上面的图就是一张无向图,因为所有的边都没有方向。
- 比如 0 - 1之间有变,那么说明这条边可以保证 0 -> 1,也可以保证 1 -> 0。
有向图:
- 有向图表示的图中的边是有方向的。
- 比如 0 -> 1,不能保证一定可以 1 -> 0,要根据方向来定。
无权图:
- 我们上面的图就是一张无权图(边没有携带权重)
- 我们上面的图中的边是没有任何意义的
- 不能说 0 - 1的边,比4 - 9的边更远或者用的时间更长。
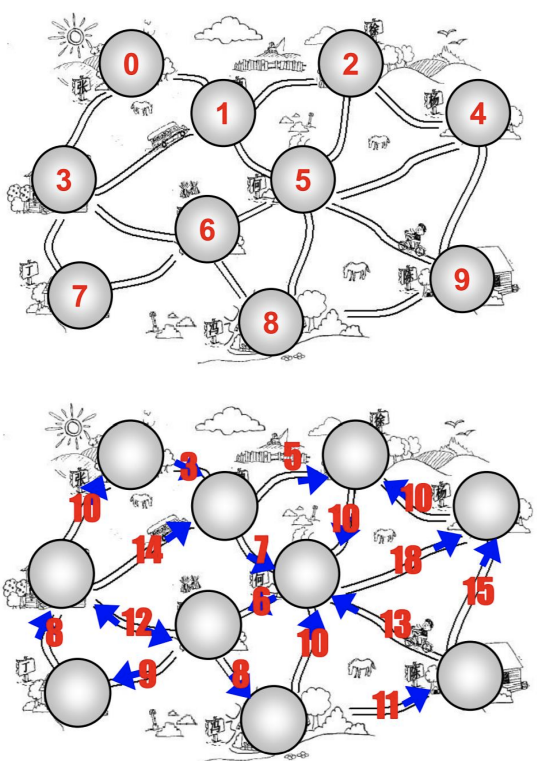
带权图:
- 带权图表示边有一定的权重。
- 这里的权重可以是任意你希望表示的数据:
- 比如距离或者花费的时间或者票价。
图的表示
怎么在程序中表示图呢?
- 我们知道一个图包含很多顶点,另外包含顶点和顶点之间的连线(边)
- 这两个都是非常重要的图信息,因此都需要在程序中体现出来。
顶点的表示相对简单,我们先讨论顶点的表示。
- 上面的顶点,我们抽象成了1 2 3 4,也可以抽象成A B C D。
- 在后面的案例中,我们使用A B C D。
- 那么这些A B C D我们可以使用一个数组来存储起来(存储所有的顶点)
- 当然,A,B,C,D也可以表示其他含义的数据(比如村庄的名字).
那么边怎么表示呢?
- 因为边是两个顶点之间的关系,所以表示起来会稍微麻烦一些。
- 下面,我们具体讨论一下变常见的表示方式。
邻接矩阵
一种比较常见的表示图的方式: 邻接矩阵。
- 邻接矩阵让每个节点和一个整数项关联,该整数作为数组的下标值。
- 我们用一个二维数组来表示顶点之间的连接。
- 二维数组[0][2] -> A -> C
画图演示:
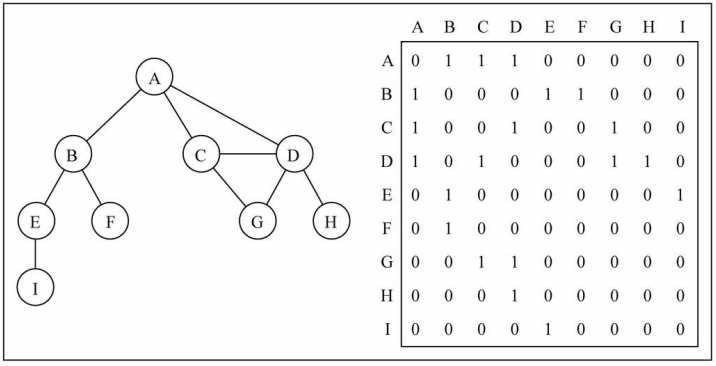
图片解析:
- 在二维数组中,0表示没有连线,1表示有连线。
- 通过二维数组,我们可以很快的找到一个顶点和哪些顶点有连线。(比如A顶点,只需要遍历第一行即可)
- 另外,A - A,B - B(也就是顶点到自己的连线),通常使用0表示。
邻接矩阵的问题:
- 邻接矩阵还有一个比较严重的问题,就是如果图是一个稀疏图
- 那么矩阵中将存在大量的0,这意味着我们浪费了计算机存储空间来表示根本不存在的边。
邻接表
另外一种常用的表示图的方式: 邻接表。
- 邻接表由图中每个顶点以及和顶点相邻的顶点列表组成。
- 这个列表有很多种方式来存储: 数组/链表/字典(哈希表)都可以。
画图演示
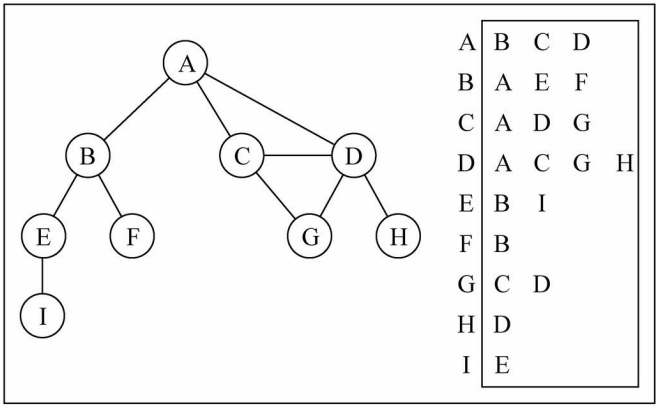
图片解析:
- 其实图片比较容易理解。
- 比如我们要表示和A顶点有关联的顶点(边),A和B/C/D有边,
- 那么我们可以通过A找到对应的数组/链表/字典,再取出其中的内容就可以啦。
邻接表的问题:
- 邻接表计算"出度"是比较简单的(出度: 指向别人的数量,入度: 指向自己的数量)
- 邻接表如果需要计算有向图的"入度",那么是一件非常麻烦的事情。
- 它必须构造一个“逆邻接表”,才能有效的计算“入度”。但是开发中“入度”相对用的比较少。
创建图类
我们先来创建Graph类

代码解析
- 创建Graph的构造函数,这个我们在封装其他数据结构的时候已经非常熟悉了。
- 定义了两个属性:
- vertexes: 用于存储所有的顶点,我们说过使用一个数组来保存。
- adjList: adj是adjoin的缩写,邻接的意思。 adjList用于存储所有的边,我们这里采用邻接表的形式。
之后,我们来定义一些方法以及实现一些算法就是一个完整的图类了
添加方法
现在我们来增加一些添加方法。
- 添加顶点: 可以向图中添加一些顶点。
- 添加边: 可以指定顶点和顶点之间的边。

添加顶点 代码解析:
- 我们将添加的顶点放入到数组中。
- 另外,我们给该顶点创建一个数组[],该数组用于存储顶点连接的所有的 边.(回顾邻接表的实现方式)

添加边 代码解析:
- 添加边需要传入两个顶点,因为边是两个顶点之间的边,边不可能单独存在。
- 根据顶点v取出对应的数组,将w加入到它的数组中。
- 根据顶点w取出对应的数组,将v加入到它的数组中。
- 因为我们这里实现的是无向图,所以边是可以双向的。
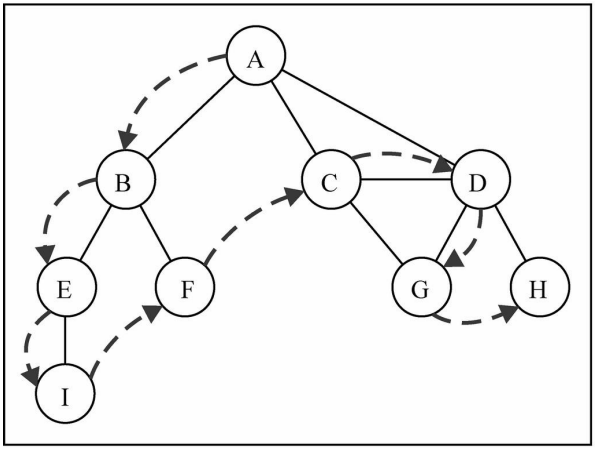
测试代码
// 添加边
graph.addEdge('A','B');
graph.addEdge('A','C');
graph.addEdge('A','D');
graph.addEdge('C','D');
graph.addEdge('C','G');
graph.addEdge('D','G');
graph.addEdge('D','H');
graph.addEdge('B','E');
graph.addEdge('B','F');
graph.addEdge('E','I');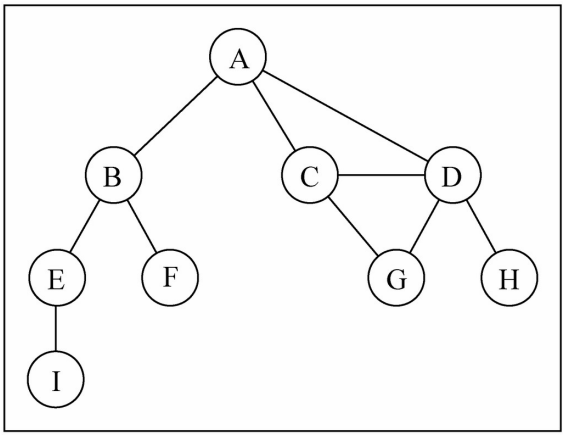
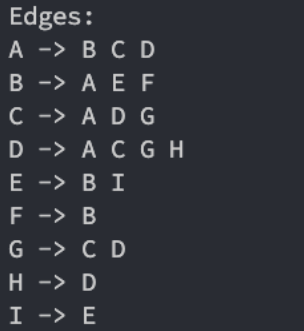
printEdges方法
为了能够正确的显示图的结果,我们来实现一下Graph的printEdges方法
图的遍历
图的遍历思想
- 图的遍历思想和树的遍历思想是一样的。
- 图的遍历意味着需要将图中每个顶点访问一遍,并且不能有重复的访问
有两种算法可以对图进行遍历
- 广度优先搜索(Breadth-First Search,简称BFS)
- 深度优先搜索(Depth-First Search,简称DFS)
- 两种遍历算法,都需要明确指定第一个被访问的顶点。
它们的遍历过程分别是怎么样呢?
- 我们以一个迷宫中关灯为例。
- 现在需要你进入迷宫,将迷宫中的灯一个个关掉,你会怎么关呢?

遍历的思想
两种算法的思想:
- BFS: 基于队列,入队列的顶点先被探索。
- DFS: 基于栈或使用递归,通过将顶点存入栈中,顶点是沿着路径被探索的,存在新的相邻顶点就去访问。
为了记录顶点是否被访问过,我们使用三种颜色来反应它们的状态
- 白色: 表示该顶点还没有被访问。
- 灰色: 表示该顶点被访问过,但并未被探索过。
- 黑色: 表示该顶点被访问过且被完全探索过。
或者我们也可以使用Set来存储被访问过的节点
广度优先搜索
广度优先搜索算法的思路:
- 广度优先算法会从指定的第一个顶点开始遍历图,先访问其所有的相邻点,就像一次访问图的一层。
- 换句话说,就是先宽后深的访问顶点
图解BFS
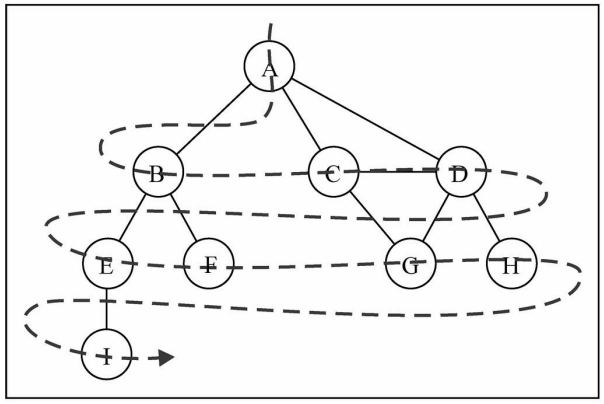
广度优先搜索的实现:
创建一个队列Q。
将v标注为被发现的(灰色),并将v将入队列Q
如果Q非空,执行下面的步骤:
将v从Q中取出队列。
将v标注为被发现的灰色。
将v所有的未被访问过的邻接点(白色),加入到队列中。
将v标志为黑色。
广度优先搜索的实现
深度优先搜索
深度优先搜索的思路:
- 深度优先搜索算法将会从第一个指定的顶点开始遍历图,沿着路径知道这条路径最后被访问了。
- 接着原路回退并探索下一条路径。
深度优先搜索算法的实现:
广度优先搜索算法我们使用的是队列,这里可以使用栈完成,也可以使用递归。
方便代码书写,我们还是使用递归(递归本质上就是函数栈的调用)
深度优先搜索
图的建模
对交通流量建模
- 顶点可以表示街道的十字路口,边可以表示街道。
- 加权的边可以表示限速或者车道的数量或者街道的距离。
- 建模人员可以用这个系统来判定最佳路线以及最可能堵车的街道。
对飞机航线建模
- 航空公司可以用图来为其飞行系统建模。
- 将每个机场看成顶点,将经过两个顶点的每条航线看作一条边。
- 加权的边可以表示从一个机场到另一个机场的航班成本,或两个机场间的距离。
- 建模人员可以利用这个系统有效的判断从一个城市到另一个城市的最小航行成本。